
1. 前言
在自己动手构建无锁的并发容器(栈和队列)中我们基于CAS算法构建了自己的无锁队列,其底层实现是不带哨兵结点的双向链表。双向链表为当前结点保留了指向前驱结点的引用,这种特性有时很有用,比如ReentrentLock中线程被唤醒后会通过prev指针找到前驱结点,通过判断其是否是头结点来决定是否要获取锁。然而大部分情况下我们只需要队列提供基本的入队和出队功能,基于双向链表来实现无疑把问题复杂化了。同时由于入队和出队过程增加了不必要的指针操作,一定程度上也影响了其性能。从上一篇最后对不同队列的性能测试中可以看出,基于双向链表实现的无锁队列在并发环境下的表现并不令人满意,不仅与同样使用CAS的ConcurrentLinkedQueue差距较大,连基于独占锁实现的LinkedBlockingQueue都比不过,这就有点尴尬了。从构建更加高效的队列的角度而言,双向链表并不是最优选择,尽管其在特殊情况下很有用,更好的方案是使用单向链表。下面就探讨下如何基于CAS算法和单向链表实现无锁的并发队列。完整的代码见github:beautiful-concurrent
2 队列内部结构
2.1 结点的定义
在进行正式编码前,我们来思考下基于单向链表实现的队列需要哪些结构。首先必须思考的是该链表是否带哨兵结点。哨兵结点可以帮我们排除某些边界情况,有利于编程模型的统一。尽管在基于双向链表实现队列时并没有使用哨兵,但这里还是选择带哨兵结点的方式,哨兵结点和链表中的正常结点用同样的数据结构表示,如下图所示
//链表结点
private static class Node<E> { //UNSAFE对象,用来进行CAS操作
private static final sun.misc.Unsafe UNSAFE; //next指针域在Node对象中的偏移量
private static final long nextOffset; static { try { //类加载时执行,反射方式创建UNSAFE对象,我们要通过该对象以CAS的方式更新
//Node对象中的next指针
Class<?> unsafeClass = Unsafe.class;
Field f = unsafeClass.getDeclaredField("theUnsafe");
f.setAccessible(true);
UNSAFE = (Unsafe) f.get(null);// UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = LockFreeSingleLinkedQueue.Node.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) { throw new Error(e);
}
} //CAS方式更新next指针,expect:cmp update:val
private boolean casNext(Node<E> cmp, Node<E> val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
} //实际存储的元素
public E item; //指向下一个结点的指针
public volatile Node<E> next; public Node(E item) { this.item = item;
} @Override
public String toString() { return "Node{" + "item=" + item + '}';
}
}结点的定义内容看似很多,其内部主要成员就两个,泛型元素item,这是存储于结点中真正有用的信息,其次是指向下一个结点的指针next。其他的内容主要是为了保证能原子的更新next指针。为什么结点中用来指向下一个结点的next指针需要被原子的更新
2.2 为什么结点内部的next指针需要原子的更新
在基于双向链表实现队列时,Node结点中定义的next指针并不需要被原子的更新,这是由其特殊的结构和特殊的插入方式决定的。回想其入队过程:
1.新结点的prev指针指向原尾结点
2.CAS方式更新尾指针指向新结点
3.原尾结点的next指针指向新结点
1主要用来确定结点在队列中的顺序,2则用来判断当前线程的插入是否成功,一旦2执行成功,新结点就算成功插入了。我们可以思考下以新结点的prev指针来确定队列的顺序有什么好处:每个结点在加入队列前都要通过1来维护在队列中的顺序,将其prev指针指向原尾结点。因为prev指针是每个结点都有的,故并发情况即使多个结点的prev指针都指向同一个尾结点也不会有覆盖的问题,它们不会相互影响。也就是说,在2真正执行前,所有成功执行1的结点都是平等的,都享有2的CAS竞争成功加入队列的权利。如下图所示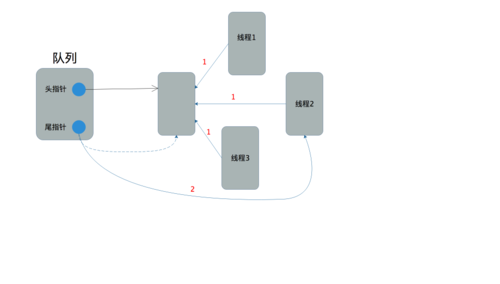
尽管图中是线程2CAS竞争成功从而将其结点入队,但如果是线程1或者线程3CAS竞争成功情况也是类似的。那单链表构成的队列又是怎样一种情况呢?单链表的入队流程相对简洁,只有两步:
1.原尾结点的next指针指向新结点
2.CAS更新尾指针指向新结点
1用来确定新结点在队列中的顺序,和双向链表中通过自身的prev指针来实现不同,单向链表中是通过修改原尾结点的next指针使其指向自己来达到目的的。这在并发环境下就会导致结果覆盖的问题,后一个执行1的线程将覆盖掉前一个线程执行1的结果。这意味着新结点要成功加入队列,不仅需要其所在线程成功竞争CAS,还要保证没有其他线程将其执行1的结果覆盖,而这在并发环境下是难以保证的,如下图:
线程1在成功竞争CAS前,线程2将尾结点的next从指向线程1的结点改为指向线程2的结点,哪怕线程1执行CAS成功,队列的结构已经被破坏了。最好的办法是在修改尾结点的next指针前判断其是否已经指向其他结点,因而对next指针的修改必须原子性的进行。当然最简单省事的方法就是使用AtomicReference即原子引用,然而正如在自己动手构建无锁的并发容器(栈和队列)第3节中指出的,原子引用逻辑上可以当成个特殊的引用,但其本质上是个对象。Node结点在队列使用时会被大量创建,其内部的AtomicReference对象也将被大量创建,这在高并发环境下无疑会一定程度影响性能。真的需要为原子的更新一个成员变量而每次创建一个对象吗其实没这个必要。所有的原子变量,其CAS算法底层都是通过sun.misc.Unsafe类中提供的本地方法实现的,尽管其被设计成不能直接被开发者使用,但是通过反射我们还是能够轻松绕过这层限制。Node类的定义中通过静态代码块在该类被加载时以反射的方式获得了Unsafe对象,并计算出了要进行原子更新的next指针域在Node对象中的相对偏移量,基于此可以实现对结点的next指针进行原子更新。这部分逻辑在casNext方法中定义,如下:
private boolean casNext(Node<E> cmp, Node<E> val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}2.3 队列的内部成员变量
队列的成员变量定义如下
//不带任何信息的哨兵结点Node<E> sentinel = new Node<>(null);//头指针指向哨兵结点Node<E> head = sentinel;//尾指针,原子引用AtomicReference<Node<E>> tail = new AtomicReference<>(sentinel);
在创建队列的时候就会初始化一个sentinel表示的哨兵结点。头指针head从始至终都指向该哨兵结点,因不会被修改,故不需要用volatile修饰。尾指针使用AtomicReference保证原子的修改。
3. 基于CAS算法和单向链表构建无锁的并发队列
3.1 出队方法
/**
* 将队列首元素从队列中移除并返回该元素,若队列为空则返回null
*
* @return
*/@Overridepublic E dequeue() { for (; ; ) { //队列首元素结点(哨兵结点之后的结点)
Node<E> headed = head.next; //队列尾结点
Node<E> tailed = tail.get(); if (headed == null) { //队列为空,返回null
return null;
} else if (headed == tailed) { //队列中只含一个元素
//CAS方式修改哨兵结点的next指针指向null
if (sentinel.casNext(headed, null)) { //cas方式修改尾指针指向哨兵结点,失败也没关系
tail.compareAndSet(tailed, sentinel); return headed.item;
}
} else if (sentinel.casNext(headed, headed.next)) { //队列中元素个数大于1
return headed.item;
}
}
}出队逻辑相对简单,只需要分三种情况讨论即可
1.队列为空,直接返回null
2.队列中元素结点个数(不包括哨兵结点)大于1,只需要修改哨兵结点的next指针指向原队列首元素结点的下一个结点。
3.队列中只有1个元素结点(不包括哨兵结点),需要同时更新尾指针和哨兵结点的next指针(头指针head自始至终都指向哨兵结点,队列首元素结点由哨兵结点的next指针指向)。
这里分为了两步,首先以CAS方式更新哨兵结点的next指针指向null,如果执行成功再以CAS方式修改tail指针指向哨兵结点。当然这里第二部修改tail指针的操作可能会失败,也可能还没来得及执行就失去cpu执行权导致队列处于一种混乱状态。比如下面这种情形:
只考虑出队情形,出队时一般只需要修改哨兵结点的next指针即可,只有在队列含元素的结点个数恰好为1时才需要更新tail指针,即使该操作没有执行或执行失败,如上图所示,只要哨兵结点的next指针为null,已经可以表示队列为空,之后的出队操作将返回null。所以仅就出队情形而言,tail指针是否更新成功对出队的结果没有任何影响。对于入队的情形,只要在新结点入队之前能够正确判断出队列此时正处于这种中间状态,并对其进行修复就行。
3.2 入队方法
/**
* 将元素加入队列尾部
* @param e 要入队的元素
* @return true:入队成功 false:入队失败
*/@Overridepublic boolean enqueue(E e) { //构造新结点
Node<E> newNode = new Node<>(e); //死循环,保证入队
for (; ; ) { //当前尾结点
Node<E> tailed = tail.get(); //当前尾结点的下一个结点
Node<E> tailedNext = tailed.next; //判断队列此时正处于出队操作导致的中间状态
if (sentinel.next == null && tailed != sentinel) { //CAS方式使尾指针指向哨兵结点,失败也没关系
tail.compareAndSet(tailed, sentinel);
} else if (tailed == tail.get()) { //尾指针尚未改变,即没有其他线程将结点插入队列
//其他线程正在执行入队,此时队列处于中间状态
if (tailedNext != null) { //替其他线程完成更新尾指针的操作
tail.compareAndSet(tailed, tailedNext);
} else if (tailed.casNext(null, newNode)) { //没有其他线程正在执行入队,CAS更新尾原结点的next指针指向新结点
//CAS更新尾指针,失败也没关系
tail.compareAndSet(tailed, newNode); return true;
}
}
}
}在正式执行入队操作前要将当前队列的状态“记录”下来‘:获取当前队列的尾结点tailed和尾结点的下一个结点tailedNext(可能为null)。这是CAS算法的通用流程,毕竟CAS更新成功的前提是没有其他线程对状态进行过修改。然而,这里还有第二层含义,可以让线程发现当前队列是否正处于一种结点入队的中间状态,即一个线程已经修改尾结点的next指针指向新结点,但尚未来得及更新tail指针。当前线程如果发现队列正处于这样一种中间状态,则可以替其他线程执行CAS更新尾指针的操作。但在这么做之前,还必须保证队列此时没有处于出队操作导致的中间状态:队列为空,但tail指针并没有指向哨兵。故首先需要通过
if (sentinel.next == null && tailed != sentinel)
进行判断,并在必要的情况下对队列状态进行修复。之后,通过
if (tailed == tail.get())
判断是否已经有其他线程已经完成了入队操作,是的话则要重新执行for循环。否则队列此时必然处于以下两种情况之一
1.所记录的尾结点的下一个结点(tailedNext)存在

说明此时已经有线程正在执行入队操作,但刚执行完第一步,还未来得及修改tail指针,那我们就帮它完成剩下的工作,当然这一步失败也没关系,可能是它自己完成了或者还有其他雷锋抢先我们一步。
2 所记录的尾结点的下一个结点(tailedNext)不存在

此时首先CAS更新尾结点的next指针指向新结点,CAS竞争失败说明有其他线程快我们一步,重新执行for循环;否则CAS方式更新tail指针,当然这一步同样可能失败,不过没关系,我为人人,人人为我,肯定有其他线程帮我们做了这工作。
4. 性能测试
为了放大测试结果的差异,这次我们开启200个线程,每个线程混合进行10000次入队和出队操作,将上述流程重复进行100次统计出执行的平均时间(毫秒),完整的测试代码见github:beautiful-concurrent。测试结果如下图所示
从测试结果可知,基于单向链表实现的无锁队列LockFreeSingleLinkedQueue取得了第二名的好成绩。尽管与同样使用CAS构建的ConcurrentLinkedQueue依旧有很大差距,但已经比基于锁实现线程安全的LinkedBlockingQueue出色不少了。当然也比基于双向链表实现的无锁队列表现的更为出色。
5. 总结
CAS算法将多线程间同步的范围缩小到了单个变量,最大限度的提升了程序执行的并行度,某种程度上可以说这种并行化带来的可伸缩性是CAS算法最大的优势。然而也要看到,当对某个数据结构的修改涉及到多个变量时,CAS算法却无法同时对多个变量进行同步,这可能导致线程对数据结构的修改处于某个中间状态,而这个中间状态可能导致其他线程无法继续执行。这时候,可以基于CAS算法实现线程间的协作。当线程发现数据结构处于某个中间状态(意味着其他线程正在对其进行修改,但可能未修改完成便失去了CPU执行权),可以对这种中间状态进行修复(替其他线程执行其未完成的操作),比起白白自旋消耗cpu,这种相互协作显然能更好的提升性能,前面入队方法的实现就是这种基于CAS协作的典型例子,当然这也依赖于CAS操作本身的特性:符合预期才能执行成功且执行失败无副作用。理解了这一点,我们才能更好的使用CAS算法构建出高效的无锁的数据结构。
原文出处https://www.cnblogs.com/takumicx/p/9478445.html





