
本文结构:
什么是 Language Model?
怎么实现?怎么应用?
cs224d Day 8: 项目2-用 RNN 建立 Language Model 生成文本
课程项目描述地址。
什么是 Language Model?
Language Model 是 NLP 的基础,是语音识别, 机器翻译等很多NLP任务的核心。
实际上是一个概率分布模型 P ,对于语言里的每一个字符串 S 给出一个概率 P(S) 。

怎么实现?怎么应用?
我们先训练一个语言模型,然后用它来生成句子。感兴趣的话可以去这里看完整代码。
1.问题识别:
我们要做的是,用 RNN 通过隐藏层的反馈信息来给历史数据 xt,xt−1,...,x1 建模。
例如,输入一个起始文本:'in palo alto',生成后面的100个单词。
其中 Palo Alto 是 California 的一个城市。
2.模型:
语言模型:给了 x1, . . . , xt, 通过计算下面的概率,预测 xt+1:

模型如下:

其中参数:

h^t 是t时刻的隐藏层,e^t 是输入层,就是 one-hot 向量 x^t 与 L 作用后得到的词向量,H 是隐藏层转换矩阵,I 是输入层词表示矩阵,U 是输出层词表示矩阵,b1,b2 是 biases,这几个是我们需要训练的参数。
我们用 cross-entropy loss 来衡量误差,使之达到最小:

我们通过评价 perplexity 也就是下面这个式子,来评价模型的表现:

当我们在最小化 mean cross-entropy 的同时,也达到了最小化 mean perplexity 的目的,因为 perplexity 就是 cross entropy 的指数形式。具体推导参考
对 J 求在 t 时刻的 各参数的偏导:


RNN 在一个时间点的 模型结构 如下:

将模型展开3步得到如下结构:

关于 t 时刻的 J 对 t-1 时刻的参数 L,H,I,b1 求导:


接下来用 Adam potimizer 来训练模型,得到 loss 最小时的参数。
再用训练好的模型去生成文本。
3.文本生成的实现
一共迭代max epoch次,
每一次都代入 training 数据,训练模型,并得到 perplexity 值,
再选择最小的 valid perplexity 并保存相应的 weights,
用模型作用在输入的初始文本,生成后面的单词。
def test_RNNLM():
config = Config()
gen_config = deepcopy(config)
gen_config.batch_size = gen_config.num_steps = 1
# We create the training model and generative model
with tf.variable_scope('RNNLM') as scope:
model = RNNLM_Model(config) # 要训练的model
# This instructs gen_model to reuse the same variables as the model above
scope.reuse_variables()
gen_model = RNNLM_Model(gen_config) # 要reuse的model
init = tf.initialize_all_variables()
saver = tf.train.Saver() with tf.Session() as session:
best_val_pp = float('inf')
best_val_epoch = 0
session.run(init) for epoch in xrange(config.max_epochs): # 迭代max epoch次
print 'Epoch {}'.format(epoch)
start = time.time() ###
train_pp = model.run_epoch(
session, model.encoded_train,
train_op=model.train_step)
valid_pp = model.run_epoch(session, model.encoded_valid) # 代入encoded train和valid数据,训练model,得到perplexity
print 'Training perplexity: {}'.format(train_pp) # training data和validation data的 perplexity
print 'Validation perplexity: {}'.format(valid_pp) if valid_pp < best_val_pp:
best_val_pp = valid_pp
best_val_epoch = epoch
saver.save(session, './ptb_rnnlm.weights') # 选择最小的 valid perplexity 并保存相应的weights
if epoch - best_val_epoch > config.early_stopping: break
print 'Total time: {}'.format(time.time() - start)
saver.restore(session, 'ptb_rnnlm.weights')
test_pp = model.run_epoch(session, model.encoded_test) # model.run_epoch,训练这个model
print '=-=' * 5
print 'Test perplexity: {}'.format(test_pp) print '=-=' * 5
starting_text = 'in palo alto'
while starting_text: print ' '.join(generate_sentence(
session, gen_model, gen_config, starting_text=starting_text, temp=1.0)) # 用模型作用在输入的初始文本,生成后面的单词
starting_text = raw_input('> ')if __name__ == "__main__":
test_RNNLM()4.模型是怎么训练的呢?
首先导入数据 training,validation,test:
def load_data(self, debug=False):
"""Loads starter word-vectors and train/dev/test data."""
self.vocab = Vocab()
self.vocab.construct(get_ptb_dataset('train'))
self.encoded_train = np.array(
[self.vocab.encode(word) for word in get_ptb_dataset('train')], # 将句子get成word,再encode成one-hot向量
dtype=np.int32)接下来建立神经网络:
添加 embedding 层:
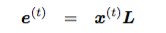
def add_embedding(self):
"""Add embedding layer.
variables you will need to create:
L: (len(self.vocab), embed_size)
Returns:
inputs: List of length num_steps, each of whose elements should be
a tensor of shape (batch_size, embed_size).
"""
# The embedding lookup is currently only implemented for the CPU
with tf.device('/cpu:0'):
embedding = tf.get_variable( 'Embedding',
[len(self.vocab), self.config.embed_size], trainable=True) # L: (len(self.vocab), embed_size)
inputs = tf.nn.embedding_lookup(embedding, self.input_placeholder) # Looks up ids in a list of embedding tensors.
inputs = [
tf.squeeze(x, [1]) for x in tf.split(1, self.config.num_steps, inputs)] # remove specific dimensions of size 1 at postion=[1]
return inputs添加 RNN 层:

def add_model(self, inputs):
with tf.variable_scope('InputDropout'):
inputs = [tf.nn.dropout(x, self.dropout_placeholder) for x in inputs] # dropout of inputs
with tf.variable_scope('RNN') as scope:
self.initial_state = tf.zeros( # initial state of RNN
[self.config.batch_size, self.config.hidden_size])
state = self.initial_state
rnn_outputs = [] for tstep, current_input in enumerate(inputs): # tstep 多少个时刻,多少个单词
if tstep > 0:
scope.reuse_variables()
RNN_H = tf.get_variable( 'HMatrix', [self.config.hidden_size, self.config.hidden_size])
RNN_I = tf.get_variable( 'IMatrix', [self.config.embed_size, self.config.hidden_size])
RNN_b = tf.get_variable( 'B', [self.config.hidden_size])
state = tf.nn.sigmoid(
tf.matmul(state, RNN_H) + tf.matmul(current_input, RNN_I) + RNN_b) # 这里state是当前时刻的隐藏层
rnn_outputs.append(state) # 不过它在下一个循环中就被用了,所以也是用来存上一时刻隐藏层的
self.final_state = rnn_outputs[-1]
with tf.variable_scope('RNNDropout'):
rnn_outputs = [tf.nn.dropout(x, self.dropout_placeholder) for x in rnn_outputs] # dropout of outputs
return rnn_outputs建立 projection 层:

def add_projection(self, rnn_outputs):
with tf.variable_scope('Projection'):
U = tf.get_variable( 'Matrix', [self.config.hidden_size, len(self.vocab)])
proj_b = tf.get_variable('Bias', [len(self.vocab)])
outputs = [tf.matmul(o, U) + proj_b for o in rnn_outputs] # outputs=rnn_outputs*U+b2
return outputs用 cross entropy 计算 loss:
def add_loss_op(self, output):
all_ones = [tf.ones([self.config.batch_size * self.config.num_steps])]
cross_entropy = sequence_loss( # cross entropy
[output], [tf.reshape(self.labels_placeholder, [-1])], all_ones, len(self.vocab))
tf.add_to_collection('total_loss', cross_entropy)
loss = tf.add_n(tf.get_collection('total_loss')) # 最终的loss
return loss用 Adam 最小化 loss:
def add_training_op(self, loss): optimizer = tf.train.AdamOptimizer(self.config.lr) train_op = optimizer.minimize(self.calculate_loss) # 用Adam最小化loss return train_op
每一次训练后,得到了最小化 loss 相应的 weights。
训练后的模型,就可以用来生成文本了:
while starting_text: print ' '.join(generate_sentence(
session, gen_model, gen_config, starting_text=starting_text, temp=1.0)) # 用模型作用在输入的初始文本,生成后面的单词
starting_text = raw_input('> ')




