
目的
给定一个或多个搜索词,如“高血压 患者”,从已有的若干篇文本中找出最相关的(n篇)文本。
理论知识
文本检索(text retrieve)的常用策略是:用一个ranking function根据搜索词对所有文本进行排序,选取前n个,就像百度搜索一样。
显然,ranking function是决定检索效果最重要的因素,本文选用了在实际应用中效果很好的BM25。BM25其实只用到了一些基础的统计和文本处理的方法,没有很高深的算法。
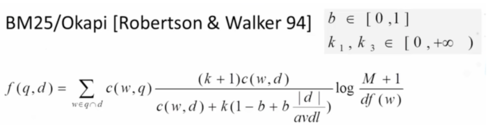
BM25
上图是BM25的公式,对于一个搜索q和所有文本,计算每一篇文本d的权重。整个公式其实是TF-IDF的改进:
第一项c(w,q)就是搜索q中词w的词频
第三项是词w的逆文档频率,M是所有文本的个数,df(w)是出现词w的文本个数
中间的第二项是关键,实质是词w的TF值的变换,c(w,d)是词w在文本d中的词频。首先是一个TF Transformation,目的是防止某个词的词频过大,经过下图中公式的约束,词频的上限为k+1,不会无限制的增长。例如,一个词在文本中的词频无论是50还是100,都说明文本与这个词有关,但相关度不可能是两倍关系。
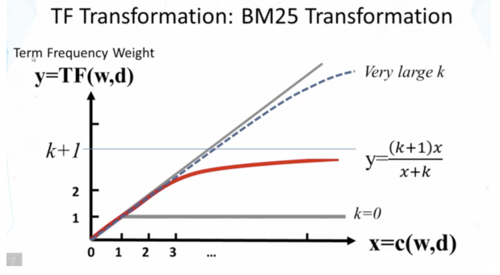
TF Transformation
上图的公式分母中的k还乘了一个系数,目的是归一化文本长度。归一化公式中,b是[0,1]之间的常数,avdl是平均文本长度,d是文本d的长度。显然,d比平均值大,则normalizer大于1,代入BM25最终的权重变小,反之亦然。
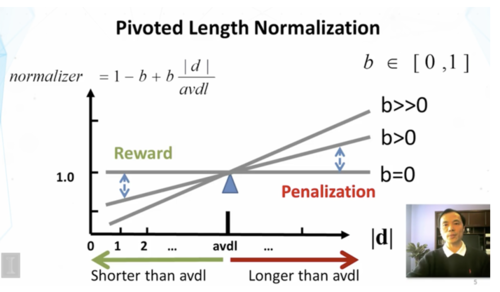
length normalization
python实现
下面通过一个例子来实现根据BM25来进行文本检索。现在从网上爬下来了几十篇健康相关的文章,部分如下图所示。模拟输入搜索词,如“高血压 患者 药物”,搜素最相关的文章。
文本列表
python的实现用到了gensim库,其中的BM25实现的源码如下:
#!/usr/bin/env python# -*- coding: utf-8 -*-## Licensed under the GNU LGPL v2.1 - http://www.gnu.org/licenses/lgpl.htmlimport math
from six import iteritems
from six.moves import xrange# BM25 parameters.PARAM_K1 = 1.5PARAM_B = 0.75EPSILON = 0.25class BM25(object):
def __init__(self, corpus): self.corpus_size = len(corpus) self.avgdl = sum(map(lambda x: float(len(x)), corpus)) / self.corpus_size self.corpus = corpus self.f = [] self.df = {} self.idf = {} self.initialize() def initialize(self): for document in self.corpus:
frequencies = {} for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.f.append(frequencies) for word, freq in iteritems(frequencies): if word not in self.df:
self.df[word] = 0
self.df[word] += 1
for word, freq in iteritems(self.df): self.idf[word] = math.log(self.corpus_size - freq + 0.5) - math.log(freq + 0.5) def get_score(self, document, index, average_idf):
score = 0
for word in document:
if word not in self.f[index]:
continue
idf = self.idf[word] if self.idf[word] >= 0 else EPSILON * average_idf
score += (idf * self.f[index][word] * (PARAM_K1 + 1)
/ (self.f[index][word] + PARAM_K1 * (1 - PARAM_B + PARAM_B * self.corpus_size / self.avgdl))) return score def get_scores(self, document, average_idf):
scores = [] for index in xrange(self.corpus_size):
score = self.get_score(document, index, average_idf)
scores.append(score) return scoresdef get_bm25_weights(corpus):
bm25 = BM25(corpus)
average_idf = sum(map(lambda k: float(bm25.idf[k]), bm25.idf.keys())) / len(bm25.idf.keys())
weights = [] for doc in corpus:
scores = bm25.get_scores(doc, average_idf)
weights.append(scores) return weightsgensim中代码写得很清楚,我们可以直接利用。
import jieba.posseg as psegimport codecsfrom gensim import corporafrom gensim.summarization import bm25import osimport re
构建停用词表
stop_words = '/Users/yiiyuanliu/Desktop/nlp/demo/stop_words.txt'stopwords = codecs.open(stop_words,'r',encoding='utf8').readlines() stopwords = [ w.strip() for w in stopwords ]
结巴分词后的停用词性 [标点符号、连词、助词、副词、介词、时语素、‘的’、数词、方位词、代词]
stop_flag = ['x', 'c', 'u','d', 'p', 't', 'uj', 'm', 'f', 'r']
对一篇文章分词、去停用词
def tokenization(filename): result = [] with open(filename, 'r') as f: text = f.read() words = pseg.cut(text) for word, flag in words: if flag not in stop_flag and word not in stopwords: result.append(word) return result
对目录下的所有文本进行预处理,构建字典
corpus = [];
dirname = '/Users/yiiyuanliu/Desktop/nlp/demo/articles'filenames = []for root,dirs,files in os.walk(dirname): for f in files: if re.match(ur'[\u4e00-\u9fa5]*.txt', f.decode('utf-8')):
corpus.append(tokenization(f))
filenames.append(f)
dictionary = corpora.Dictionary(corpus)print len(dictionary)Building prefix dict from the default dictionary ... Loading model from cache /var/folders/1q/5404x10d3k76q2wqys68pzkh0000gn/T/jieba.cache Loading model cost 0.328 seconds. Prefix dict has been built succesfully.2552
建立词袋模型
打印了第一篇文本按词频排序的前5个词
doc_vectors = [dictionary.doc2bow(text) for text in corpus] vec1 = doc_vectors[0] vec1_sorted = sorted(vec1, key=lambda (x,y) : y, reverse=True)print len(vec1_sorted)for term, freq in vec1_sorted[:5]: print dictionary[term]
76 高血压 患者 药物 血压 治疗
用gensim建立BM25模型
bm25Model = bm25.BM25(corpus)
根据gensim源码,计算平均逆文档频率
average_idf = sum(map(lambda k: float(bm25Model.idf[k]), bm25Model.idf.keys())) / len(bm25Model.idf.keys())
假设用户输入了搜索词“高血压 患者 药物”,利用BM25模型计算所有文本与搜索词的相关性
query_str = '高血压 患者 药物'query = []for word in query_str.strip().split():
query.append(word.decode('utf-8'))
scores = bm25Model.get_scores(query,average_idf)# scores.sort(reverse=True)print scores[4.722034069722618, 4.5579610648148625, 2.859958016641194, 3.388613898734133, 4.6281563584251995, 4.730042214103296, 1.447106736835707, 2.595169814422283, 2.894213473671414, 2.952010252059601, 3.987044912721877, 2.426869660460219, 1.1583806884161147, 0, 3.242214688067997, 3.6729065940310752, 3.025338037306947, 1.57823130047124, 2.6054874252518214, 3.4606547596124635, 1.1583806884161147, 2.412854586446401, 1.7354863870557247, 1.447106736835707, 3.571235274862516, 2.6054874252518214, 2.695780408029825, 2.3167613768322295, 4.0309963518837595, 0, 2.894213473671414, 3.306255023356817, 3.587349029341776, 3.4401107112269824, 3.983307351035947, 0, 4.508767501123564, 3.6289862140766926, 3.6253442838304633, 4.248297326100691, 3.025338037306947, 3.602635199166345, 3.4960329155028464, 3.3547048399034876, 1.57823130047124, 4.148340973502125, 1.1583806884161147]
idx = scores.index(max(scores))print idx
5
找到最相关的文本
fname = filenames[idx]print fname
关于降压药的五个问题.txt
with open(fname,'r') as f: print f.read()
高血压的重要治疗方式之一,就是口服降压药。对于不少刚刚被确诊的“高血压新手”来说,下面这些关于用药的事情,是必须知道的。 1. 贵的药,真的比便宜的药好用吗? 事实上,降压药物的化学机构和作用机制不一样。每一种降压药,其降压机理和适应人群都不一样。只要适合自己的病情和身体状况,就是好药。因此,不存在“贵重降压药一定比便宜的降压药好使”这一说法。 2. 能不吃药就不吃药,靠身体调节血压,这种想法对吗? 这种想法很幼稚。其实,高血压是典型的,应该尽早服药的疾病。如果服药太迟,高血压对重要脏器持续形成伤害,会让我们的身体受很大打击。所以,高血压患者尽早服药,是对身体的最好的保护。 3. 降压药是不是得吃一辈子? 对于这个问题,中医和西医有着不同的认识。西医认为,降压药服用之后不应该停用,以免血压形成波动,造成对身体的进一步伤害。中医则认为,通过适当的运动和饮食调节,早期的部分高血压患者,可以在服药之后的某段时间里停药。总之,处理这一问题的时候,我们还是要根据自己的情况而定。对于高血压前期,或者轻度高血压的人来说,在生活方式调节能够让血压稳定的情况下,可以考虑停药,采取非药物疗法。对于中度或者重度的高血压患者来说,就不能这么做了。 4. 降压药是不是要早晨服用? 一般来说,长效的降压药物,都是在早晨服用的。但是,我们也可以根据高血压患者的波动情况,适当改变服药时间。 5. 降压药是不是一旦服用就不能轻易更换? 高血压病人一旦服用了某种降压药物,就不要轻易更换。只要能维持血压在正常范围而且稳定,就不用换药。只有在原有药物不能起到控制作用的时候,再考虑更换服药方案。对于新发高血压病人来说,长效降压药若要达到稳定的降压效果,往往需要4到6周或者更长时间。如果经过4到6周也实现不了好的控制效果,可以考虑加第二种药物来联合降压,不必盲目换药。
参考资料:
Coursera: Text Mining and Analytics
作者:lyy0905
链接:https://www.jianshu.com/p/ff28004efb8a





