
TypeScript在node项目中的实践
TypeScript可以理解为是JavaScript的一个超集,也就是说涵盖了所有JavaScript的功能,并在之上有着自己独特的语法。
最近的一个新项目开始了TS的踩坑之旅,现分享一些可以借鉴的套路给大家。
为什么选择TS
作为巨硬公司出品的一个静态强类型编译型语言,该语言已经出现了几年的时间了,相信在社区的维护下,已经是一门很稳定的语言。
我们知道,JavaScript是一门动态弱类型解释型脚本语言,动态带来了很多的便利,我们可以在代码运行中随意的修改变量类型以达到预期目的。
但同时,这是一把双刃剑,当一个庞大的项目出现在你的面前,面对无比复杂的逻辑,你很难通过代码看出某个变量是什么类型,这个变量要做什么,很可能一不小心就会踩到坑。
而静态强类型编译能够带来很多的好处,其中最重要的一点就是可以帮助开发人员杜绝一些马虎大意的问题: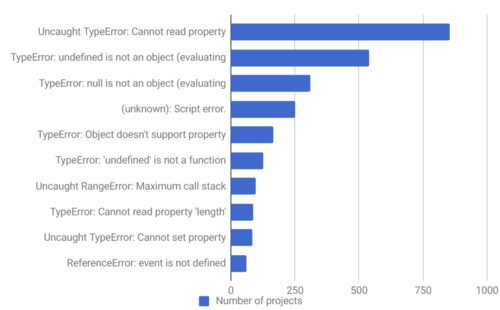
图为rollbar统计的数千个项目中数量最多的前十个异常
不难看出,因为类型不匹配、变量为空导致的异常比你敢承认的次数要多。
譬如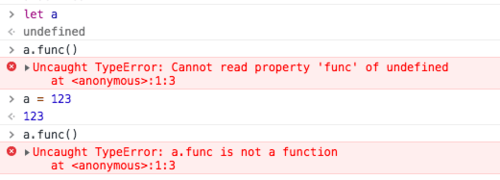
而这一点在TS中得到了很好的改善,任何一个变量的引用,都需要指定自己的类型,而你下边在代码中可以用什么,支持什么方法,都需要在上边进行定义: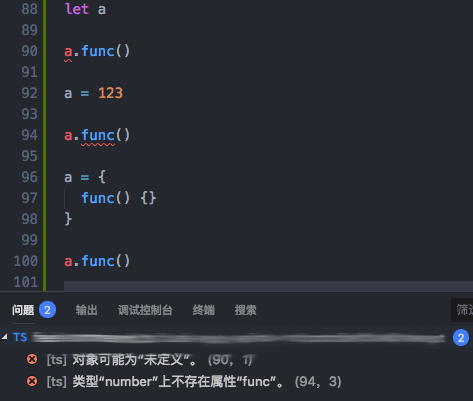
这个提示会在开发、编译期来提示给开发者,避免了上线以后发现有问题,再去修改。
另外一个由静态编译类型带来的好处,就是函数签名。
还是就像上边所说的,因为是一个动态的脚本语言,所以很难有编辑器能够在开发期间正确地告诉你所要调用的一个函数需要传递什么参数,函数会返回什么类型的返回值。
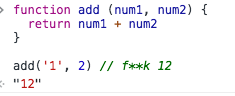
而在TS中,对于一个函数,首先你需要定义所有参数的类型,以及返回值的类型。
这样在函数被调用时,我们就可以很清晰的看到这个函数的效果: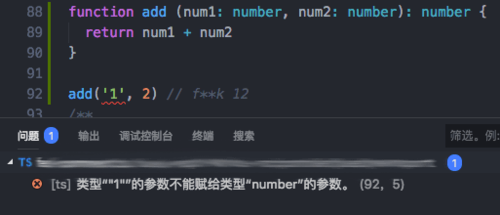
这是最基础的、能够让程序更加稳定的两个特性,当然,还有更多的功能在TS中的:TypeScript | Handbook
TypeScript在node中的应用
在TS的官网中,有着大量的示例,其中就找到了Express版本的例子,针对这个稍作修饰,应用在了一个 koa 项目中。
环境依赖
在使用TS之前,需要先准备这些东西:
VS code,同为巨硬公司出品,本身就是TS开发的,遂该编辑器是目前对TS支持度最高的一个
Node.js 推荐8.11版本以上
npm i -g typescript,全局安装TS,编译所使用的tsc命令在这里npm i -g nodemon,全局安装nodemon,在tsc编译后自动刷新服务器程序
以项目中使用的一些核心依赖:
reflect-metadata: 大量装饰器的包都会依赖的一个基础包,用于注入数据routing-controllers: 使用装饰器的方式来进行koa-router的开发sequelize: 抽象化的数据库操作sequelize-typescript: 上述插件的装饰器版本,定义实体时使用
项目结构
首先,放出目前项目的结构:

. ├── README.md ├── copy-static-assets.ts ├── nodemon.json ├── package-lock.json ├── package.json ├── dist ├── src │ ├── config │ ├── controllers │ ├── entity │ ├── models │ ├── middleware │ ├── public │ ├── app.ts │ ├── server.ts │ ├── types │ └── utils ├── tsconfig.json └── tslint.json
src为主要开发目录,所有的TS代码都在这里边,在经过编译过后,会生成一个与src同级的dist文件夹,这个文件夹是node引擎实际运行的代码。
在src下,主要代码分为了如下结构(依据自己项目的实际情况进行增删):
| # | folder | desc |
|---|---|---|
| 1 | controllers | 用于处理接口请求,原apps、routes文件夹。 |
| 2 | middleware | 存放了各种中间件、全局 or 自定义的中间件 |
| 3 | config | 各种配置项的位置,包括端口、log路径、各种巴拉巴拉的常量定义。 |
| 4 | entity | 这里存放的是所有的实体定义(使用了sequelize进行数据库操作)。 |
| 5 | models | 使用来自entity中的实体进行sequelize来完成初始化的操作,并将sequelize对象抛出。 |
| 6 | utils | 存放的各种日常开发中提炼出来的公共函数 |
| 7 | types | 存放了各种客制化的复合类型的定义,各种结构、属性、方法返回值的定义(目前包括常用的Promise版redis与qconf) |
controllers
controllers只负责处理逻辑,通过操作model对象,而不是数据库来进行数据的增删改查
鉴于公司绝大部分的Node项目版本都已经升级到了Node 8.11,理所应当的,我们会尝试新的语法。
也就是说我们会抛弃Generator,拥抱async/await 。
使用Koa、Express写过接口的童鞋应该都知道,当一个项目变得庞大,实际上会产生很多重复的非逻辑代码:
router.get('/', ctx => {})
router.get('/page1', ctx => {})
router.get('/page2', ctx => {})
router.get('/page3', ctx => {})
router.get('/pageN', ctx => {})
而在每个路由监听中,又做着大量重复的工作:
router.get('/', ctx => {
let uid = Number(ctx.cookies.get('uid'))
let device = ctx.headers['device'] || 'ios'
let { tel, name } = ctx.query
})
几乎每一个路由的头部都是在做着获取参数的工作,而参数很可能来自header、body甚至是cookie及query。
所以,我们对原来koa的使用方法进行了一个较大的改动,并使用routing-controllers大量的应用装饰器来帮助我们处理大部分的非逻辑代码。
原有router的定义:
module.exports = function (router) {
router.get('/', function* (next) {
let uid = Number(this.cookies.get('uid'))
let device = this.headers['device'] this.body = {
code: 200
}
})
}
使用了TypeScript与装饰器的定义:
@Controller
export default class {
@Get('/')
async index (
@CookieParam('uid') uid: number,
@HeaderParam('device') device: string
) { return {
code: 200
}
}
}
为了使接口更易于检索、更清晰,所以我们抛弃了原有的bd-router的功能(依据文件路径作为接口路径、TS中的文件路径仅用于文件分层)。
直接在controllers下的文件中声明对应的接口进行监听。
middleware
如果是全局的中间件,则直接在class上添加@Middleware装饰器,并设置type: 'after|before'即可。
如果是特定的一些中间件,则创建一个普通的class即可,然后在需要使用的controller对象上指定@UseBefore/@UseAfter(可以写在class上,也可以写在method上)。
所有的中间件都需要继承对应的MiddlewareInterface接口,并需要实现use方法
// middleware/xxx.tsimport {ExpressMiddlewareInterface} from "../../src/driver/express/ExpressMiddlewareInterface"export class CompressionMiddleware implements KoaMiddlewareInterface {
use(request: any, response: any, next?: Function): any {
console.log("hello compression ...")
next()
}
}// controllers/xxx.ts@UseBefore(CompressionMiddleware)
export default class { }
entity
文件只负责定义数据模型,不做任何逻辑操作
同样的使用了sequelize+装饰器的方式,entity只是用来建立与数据库之间通讯的数据模型。
import { Model, Table, Column } from 'sequelize-typescript'@Table({
tableName: 'user_info_test'})
export default class UserInfo extends Model<UserInfo> {
@Column({
comment: '自增ID',
autoIncrement: true,
primaryKey: true
})
uid: number
@Column({
comment: '姓名'
})
name: string
@Column({
comment: '年龄',
defaultValue: 0
})
age: number
@Column({
comment: '性别'
})
gender: number
}
因为sequelize建立连接也是需要对应的数据库地址、账户、密码、database等信息、所以推荐将同一个数据库的所有实体放在一个目录下,方便sequelize加载对应的模型
同步的推荐在config下创建对应的配置信息,并添加一列用于存放实体的key。
这样在建立数据库链接,加载数据模型时就可以动态的导入该路径下的所有实体:
// config.tsexport const config = { // ... mysql1: { // ... config+ entity: 'entity1' // 添加一列用来标识是什么实体的key },
mysql2: { // ... config+ entity: 'entity2' // 添加一列用来标识是什么实体的key } // ...}// utils/mysql.tsnew Sequelize({ // ...
modelPath: [path.reolve(__dirname, `../entity/${config.mysql1.entity}`)] // ...})
model
model的定位在于根据对应的实体创建抽象化的数据库对象,因为使用了sequelize,所以该目录下的文件会变得非常简洁。
基本就是初始化sequelize对象,并在加载模型后将其抛出。
export default new Sequelize({
host: '127.0.0.1',
database: 'database',
username: 'user',
password: 'password',
dialect: 'mysql', // 或者一些其他的数据库
modelPaths: [path.resolve(__dirname, `../entity/${configs.mysql1.entity}`)], // 加载我们的实体
pool: { // 连接池的一些相关配置
max: 5,
min: 0,
acquire: 30000,
idle: 10000
},
operatorsAliases: false,
logging: true // true会在控制台打印每次sequelize操作时对应的SQL命令})
utils
所有的公共函数,都放在这里。
同时推荐编写对应的索引文件(index.ts),大致的格式如下:
// utils/get-uid.tsexport default function (): number { return 123}// utils/number-comma.tsexport default function(): string { return '1,234'}// utils/index.tsexport {default as getUid} from './get-uid'export {default as numberComma} from './number-comma'
每添加一个新的util,就去index中添加对应的索引,这样带来的好处就是可以通过一行来引入所有想引入的utils:
import {getUid, numberComma} from './utils'
configs
configs下边存储的就是各种配置信息了,包括一些第三方接口URL、数据库配置、日志路径。
各种balabala的静态数据。
如果配置文件多的话,建议拆分为多个文件,然后按照utils的方式编写索引文件。
types
这里存放的是所有的自定义的类型定义,一些开源社区没有提供的,但是我们用到的第三方插件,需要在这里进行定义,一般来说常用的都会有,但是一些小众的包可能确实没有TS的支持,例如我们有使用的一个node-qconf:
// types/node-qconf.d.tsexport function getConf(path: string): string | nullexport function getBatchKeys(path: string): string[] | nullexport function getBatchConf(path: string): string | nullexport function getAllHost(path: string): string[] | nullexport function getHost(path: string): string | null
类型定义的文件规定后缀为 .d.ts
types下边的所有文件可以直接引用,而不用关心相对路径的问题(其他普通的model则需要写相对路径,这是一个很尴尬的问题)。
目前使用TS中的一些问题

当前GitHub仓库中,有2600+的开启状态的issues,筛选bug标签后,依然有900+的存在。
所以很难保证在使用的过程中不会踩坑,但是一个项目拥有这么多活跃的issues,也能从侧面说明这个项目的受欢迎程度。
目前遇到的唯一一个比较尴尬的问题就是:
引用文件路径一定要写全。。
import module from '../../../../f**k-module'
小结
初次尝试TypeScript,深深的喜欢上了这个语言,虽说也会有一些小小的问题,但还是能克服的:)。
使用一门静态强类型编译语言,能够将很多bug都消灭在开发期间。
基于上述描述的一个简单示例:代码仓库
希望大家玩得开心,如有任何TS相关的问题,欢迎来骚扰。NPM loves U.。
TypeScript在node项目中的实践




