
一.概念
支持向量机(Support Vector Machine),简称SVM。是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
SVM的主要思想可以概括为两点:
1.它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
2.它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
二.特征
⑴SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
⑵SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
⑶通过对数据中每个分类属性引入一个哑变量,SVM可以应用于分类数据。
⑷SVM一般只能用在二类问题,对于多类问题效果不好。
三.分类
3.1线性分类
如果需要分类的数据是线性可分的,比如说存在一条直线可以将坐标系(二维)的两类数据完全分离,或者延伸到存在一个超平面,可以将一个N维空间的数据完全分离。但我们知道这样一条直线(超平面)是不唯一的。例如图中的粗黑线:
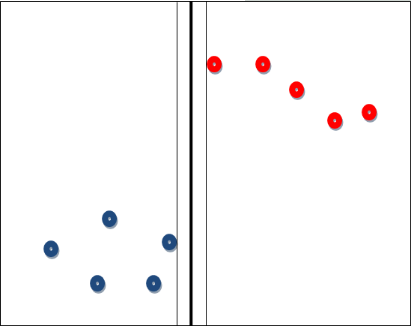
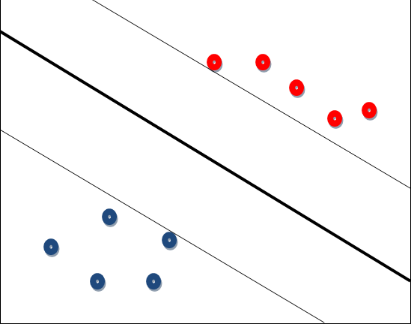
问题在于,那种分类方案是最优的呢?这里引入一个概念MMH:最大间隔分类器Maximum Margin Classifier,对一个数据点进行分类,当超平面离数据点的“间隔”越大,分类的确信度(confidence)也越大。所以,为了使得分类的确信度尽量高,需要让所选择的超平面能够最大化这个“间隔”值。这个“间隔”值也就是粗线与细线(细线临近数据点)的距离。那么临近细线的点,就叫做支持向量点。因此SVM有一个优点,就是即使有大量的数据,但是支持向量点是固定的,因此即使再次训练大量数据,这个超平面也可能不会变化。
sklearn里的SVM模块提供了这样分类的方法(SVC)
SVC参数解释(1)C: 目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的,default C = 1.0;(2)kernel:参数选择有RBF, Linear, Poly, Sigmoid, 默认的是"RBF";(3)degree:if you choose 'Poly' in param 2, this is effective, degree决定了多项式的最高次幂;(4)gamma:核函数的系数('Poly','Linear', 'RBF' and 'Sigmoid'), 默认是gamma = 1 / n_features;(5)coef0:核函数中的独立项,'RBF' and 'Poly'有效;(6)probablity: 可能性估计是否使用(true or false);(7)shrinking:是否进行启发式;(8)tol(default = 1e - 3): svm结束标准的精度;(9)cache_size: 制定训练所需要的内存(以MB为单位);(10)class_weight: 每个类所占据的权重,不同的类设置不同的惩罚参数C, 缺省的话自适应;(11)verbose: 跟多线程有关,不大明白啥意思具体;(12)max_iter: 最大迭代次数,default = 1, if max_iter = -1, no limited;(13)decision_function_shape : ‘ovo’ 一对一, ‘ovr’ 多对多 or None 无, default=None (14)random_state :用于概率估计的数据重排时的伪随机数生成器的种子。ps:7,8,9一般不考虑。
代码:
# coding:utf-8 from sklearn import svmimport numpy as npimport matplotlib.pyplot as plt#np.random.seed(0) 指定随机参数,用于测试x = np.r_[np.random.randn(20,2)-[2,2],np.random.randn(20,2)+[2,2]] #正态分布来产生数字,设置偏移量y = [0]*20+[1]*20 #分类标记 20个class0,20个class1 print('x = ',x)print('y = ',y)clf = svm.SVC(kernel='linear') #svm.svc模块,kernel='linear'线性核函数 clf.fit(x,y)#coef_存放回归系数,intercept_存放截距w = clf.coef_[0] #获取w a = -w[0]/w[1] #斜率 #画图划线 xx = np.linspace(-4,4) #图像区间yy = a*xx-(clf.intercept_[0])/w[1] #xx带入y,截距 #画出与点相切的线 b = clf.support_vectors_[0]yy_down = a*xx+(b[1]-a*b[0])b = clf.support_vectors_[-1]yy_up = a*xx+(b[1]-a*b[0])print("W:",w)print("a:",a)print("support_vectors_:",clf.support_vectors_)print("clf.coef_:",clf.coef_)plt.figure(figsize=(8,4))#plt.xlabel("X") #plt.ylabel("Y") #plt.title("Test") plt.plot(xx,yy)plt.plot(xx,yy_down)plt.plot(xx,yy_up)plt.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=80)plt.scatter(x[:,0],x[:,1],c=y,cmap=plt.cm.Paired) #[:,0]列切片,第0列 plt.axis('tight')plt.show()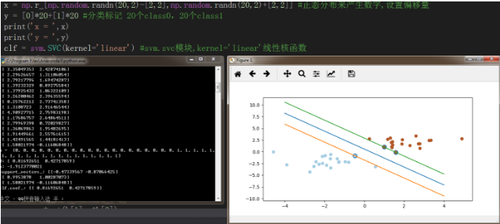
3.2非线性分类
当面对非线性可解的分类时,我们需要把数据投放到更高的维度再分割。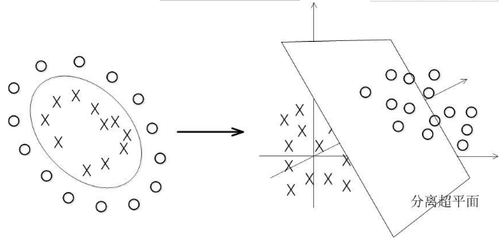
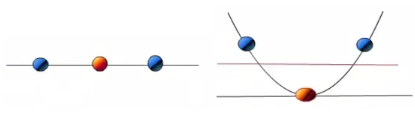
如下图:当f(x)=x时,这组数据是个直线,但是当我把这组数据变为f(x)=x^2时,这组数据就可以被红线所分割了。
比如说,我这里有一组三维的数据X=(x1,x2,x3),线性不可分割,因此我需要将他转换到六维空间去。
因此我们可以假设六个维度分别是:x1,x2,x3,x1^2,x1*x2,x1*x3,当然还能继续展开,但是六维的话这样就足够了。
新的决策超平面:d(Z)=WZ+b,解出W和b后带入方程,因此这组数据的超平面应该是:
d(Z)=w1x1+w2x2+w3x3+w4*x1^2+w5x1x2+w6x1x3+b
转换高纬度一般是以内积(dot product)的方式进行的,内积的算法复杂度非常大。
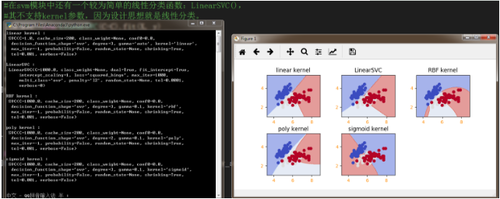
SVC提供了其他非线性的核函数:(参数为kernel,默认为rbf)
enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED };LINEAR:线性核函数(linear kernel) K(x,y)=x·yPOLY:多项式核函数(ploynomial kernel) K(x,y)=[(x·y)+1]^dRBF:径向机核函数(radical basis function) K(x,y)=exp(-|x-y|^2/d^2)SIGMOID: 神经元的非线性作用函数核函数(Sigmoid tanh) K(x,y)=tanh(a(x·y)+b)PRECOMPUTED:用户自定义核函数以下代码为以常见的iris测试数据,各核函数的分类视图
# coding:utf-8 import numpy as npimport matplotlib.pyplot as pltfrom sklearn import svm, datasetsiris = datasets.load_iris()X = iris.data[:, :2] #萼片长宽 y = iris.target #类别 C = 1e3 svc = svm.SVC(kernel="linear").fit(X, y)rbf_svc = svm.SVC(kernel="rbf", gamma=0.1, C=C).fit(X, y)poly_svc = svm.SVC(kernel="poly", gamma=0.1,degree=2, C=C).fit(X, y)sigmoid_svc = svm.SVC(kernel="sigmoid",gamma=0.1,C=C).fit(X, y)#在svm模块中还有一个较为简单的线性分类函数:LinearSVC(),#其不支持kernel参数,因为设计思想就是线性分类。lin_svc =svm.LinearSVC(C=C).fit(X, y)X_min, X_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(X_min, X_max, 0.02),np.arange(y_min, y_max, 0.02))test_x = np.c_[xx.ravel(), yy.ravel()]titles = ['linear kernel','LinearSVC','RBF kernel','poly kernel','sigmoid kernel']plt.figure(figsize=(8,4))for i, clf in enumerate((svc, lin_svc, rbf_svc, poly_svc,sigmoid_svc)):plt.subplot(2, 3, i+1)plt.subplots_adjust(wspace=0.4, hspace=0.4)print(titles[i],':\n',clf,'\n')Z = clf.predict(test_x).reshape(xx.shape)plt.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.5)plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm)plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())plt.xticks(fontsize=10, color="darkorange")plt.yticks(fontsize=10, color="darkorange")plt.title(titles[i])plt.show()
四.回归
支持分类的支持向量机可以推广到解决回归问题,这种方法称为支持向量回归
支持向量分类所产生的模型仅仅依赖于训练数据的一个子集,因为构建模型的成本函数不关心在超出边界范围的点,类似的,通过支持向量回归产生的模型依赖于训练数据的一个子集,因为构建模型的函数忽略了靠近预测模型的数据集。
有三种不同的实现方式:支持向量回归SVR,nusvr和linearsvr。linearsvr提供了比SVR更快实施但只考虑线性核函数,而nusvr实现比SVR和linearsvr略有不同。
作为分类类别,训练函数将X,y作为向量,在这种情况下y是浮点数
# coding:utf-8 from sklearn import svmimport numpy as npimport matplotlib.pyplot as pltdef f(x):return np.sin(x)/2PI=3.1415926x = np.sort(PI*2 * np.random.rand(40, 1) -PI, axis=0) #产生40组数据,每组一个数据,axis=0决定按列排列,=1表示行排列 y = f(x).ravel() #np.sin()输出的是列,和x对应,ravel表示转换成行 # 干扰数据 y[::5] += 3 * (0.5 - np.random.rand(8))print('x = ',x)print('y = ',y)clf_rbf = svm.SVR(kernel='rbf', C=1e3, gamma=0.1)clf_linear = svm.SVR(kernel='linear', C=1e3)clf_poly = svm.SVR(kernel='poly', C=1e3, degree=2)clf_rbf.fit(x,y)clf_linear.fit(x,y)clf_poly.fit(x,y)yy_linear = clf_linear.predict(x)yy_rbf = clf_rbf.predict(x)yy_poly = clf_poly.predict(x)plt.figure(figsize=(8,4))plt.scatter(x,y, color='darkorange',label='data')plt.plot(x, yy_rbf,lw = 2,color='red',label='rbf')plt.plot(x, yy_linear,lw = 2, color='blue',label='linear')plt.plot(x, yy_poly,lw = 2, color='green',label='poly')plt.axis('tight')plt.legend()plt.show()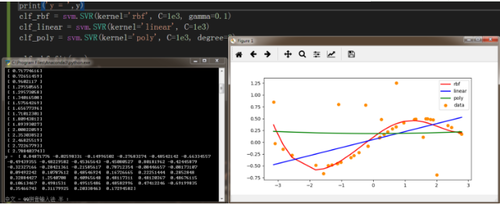
五.总结
SVM方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(Hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题.简单地说,就是升维和线性化.升维,就是把样本向高维空间做映射,一般情况下这会增加计算的复杂性,甚至会引起“维数灾难”,因而人们很少问津.但是作为分类、回归等问题来说,很可能在低维样本空间无法线性处理的样本集,在高维特征空间中却可以通过一个线性超平面实现线性划分(或回归).一般的升维都会带来计算的复杂化,SVM方法巧妙地解决了这个难题:应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”.这一切要归功于核函数的展开和计算理论。
六.相关学习资源
http://blog.csdn.net/jerry81333/article/details/53183543
http://blog.csdn.net/v_july_v/article/details/7624837
http://blog.csdn.net/gamer_gyt/article/details/51265347





