
一. 导语:
决策树(Decision Tree)的思想是贪心(最优化分) 与 分治(子树划分)。构建决策树的目的是:随着划分过程的进行,使得决策树分支结点所包含的样本尽可能属于同一类别,即使得分类更准确。
决策树还是比较基础的分类算法,这篇文章主要用于记录自己的学习过程。文中尽量减少了数学公式,由于LaTeX公式导入有点问题,所以本文的公式都用的是在word中编辑后截图帖进来的,文字中有些数字的上下标采用的html标签,但是我发现在客户端是看可能加载不了。特意说明一下
<sub></sub>代表的是下标,<sup></sup>代表的是上标
二. 算法流程:
Input: 训练集D={(x1, y1), (x2, y2), ..., (xm, ym)};
属性集A={a1, a2, ..., ad}.Output: 以node为根节点的一个决策树Process:## 通过给定样本集D和属性集A构建决策树TreeGenerate(D, A){ 1: 生成结点node; 2: if D 中样本全属于同一类别C then
3: 将node标记为 C类 叶节点; return
4: end if
5: if A = ∅ OR D中样本在A上取值相同 then
6: 将node标记为叶节点,其类别标记为D中样本数最多的类; return
7: end if
8: 从 A 中选择最优化分属性 a* 9: for a* 的每一值a[i] do
10: 为node生成一个分支; 令Dv表示D中在 a* 上取值为 a[i] 的样本子集; 11: if Dv is empty then
12: 将分支结点标记为叶节点,其类别为D中样本最多的类; return
13: else
14: 以 TreeGenerate(Dv, A\{a*}) 为分支结点; 15: end if
16: end for}决策树采用递归的方式建立,从算法伪代码可知3、6、12行可导致递归返回。
当前节点包含的样本属于同一类别,无需划分;
当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
当前结点包含的样本集合为空,不能划分;
三. 划分选择
从伪代码中可以看到,决策树的关键在于伪代码第8行,即选择能产生最优划分的属性a*。那么我们应该以什么准则来度量“划分最优”?
3.1 信息熵
熵(entropy)是表示随机变量不确定性的度量,设D是一个取有限个值的离散随机变量,其概率分布为P(X=xk) = pk, k = 1,2,3...,n,则随机变量D的熵定义为:
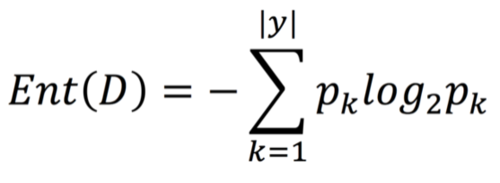
其中,若pk=0,则定义0log0 = 0,式中log的底数通常以2为底或e为底,这时它们的单位分别为比特(bit)或纳特(nat)。
在机器学习任务中,信息熵是度量样本集合纯度的指标。上式对应的意义为:对应当前样本集合D中第k类样本所占的比例为pk(k=1,2,3...|y|)。Ent(D)值越小,则D的纯度越高,也可以说D中样本的确定性越高。
3.2 信息增益
假定离散属性a有V个可能取值{a1,a2,a3,...,aV},若使用a对样本D进行划分,则会产生V个分支节点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。信息增益就是通过度量不同分支结点所包含的样本数不同,给分支结点赋予权重|Dv|/|D|,即样本数越多的分支结点影响越大,于是信息增益(information gain)定义如下:
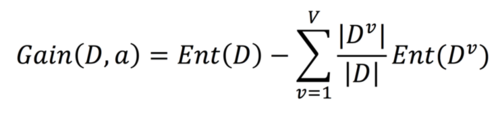
一般来说,信息增益越大说明使用属性a进行划分所获得的“纯度提升”越大,因此我们可以用信息增益作为一种属性划分的选择。(选择属性a进行划分后,将不再作为候选的划分属性,即每个属性参与划分后就将其从候选集中移除)
著名的ID3决策树就是采用信息增益作为最优划分选择。事实上,信息增益准则对可取值数目较多的属性有所偏好,这种偏好可能带来不良影响。
3.3 增益率
为减少信息增益准则的偏好影响,因此提出了使用“增益率”来选择最优化分。C4.5决策树就是采用这种方式来确定最优划分。增益率(gain ratio)定义为:
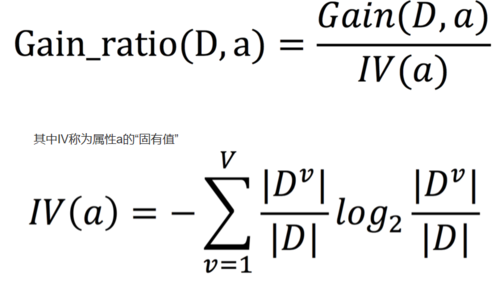
属性a的可能取值数目越多,则IV(a)的值越大,这样通过引入约束项,可以从一定程度上削弱“对取值多的属性”的偏好,但是同时增益率准则对可取值数目较少的属性有所偏好(是不是很尴尬)
3.4 基尼指数
CART决策树使用“基尼指数”(Gini index)来选择划分属性,数据集D的纯度可以用基尼值来度量:
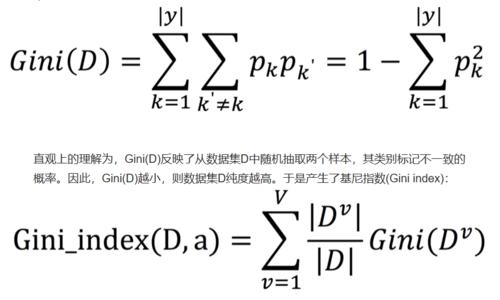
于是可以选择使得基尼指数最小的属性作为最优化分属性。
四. 剪枝处理
剪枝(pruning)是解决决策树过拟合的主要手段,通过剪枝可以大大提升决策树的泛化能力。通常,剪枝处理可分为:预剪枝,后剪枝。
预剪枝:通过启发式方法,在生成决策树过程中对划分进行预测,若当前结点的划分不能对决策树泛化性能提升,则停止划分,并将其标记为叶节点
后剪枝:对已有的决策树,自底向上的对非叶结点进行考察,若该结点对应的子树替换为叶结点能提升决策树的泛化能力,则将改子树替换为叶结点
对于后剪枝策略,可以通过极小化决策树整体的损失函数(Cost function)来实现。设树T的叶节点个数为|T|,t是树T的叶结点,该叶节点有Nt个样本点,其中k类的样本点有Ntk个,k=1,2,...,K,Ht(T)为叶结点t上的经验熵,α≥0为参数,则决策树学习的损失函数可以定义为:
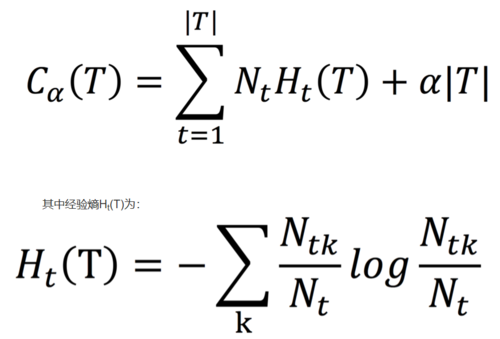
令C(T)表示模型对训练数据预测误差,即模型与训练数据的拟合程度,|T|表示模型的复杂度,参数α≥0调节二者关系。
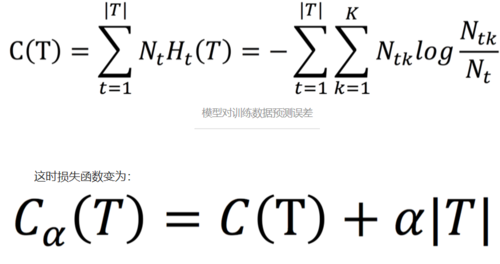
较大的α促使树的结构更简单,较小的α促使树的结构更复杂,α=0意味着不考虑树的复杂度(α|T|就是正则项,加入约束,使得模型简单,避免过拟合)。
Input: 生成算法产生的整个决策树T,参数αOutput: 剪枝后的子树T’Process:1: 计算每个结点的经验熵2: 递归地从树的叶结点向上回缩(参考下图) 设一组叶结点回缩到父结点之前与之后的整体树分别为T1于T2, 其对应的损失函数值分别为Cα(T1)和Cα(T2), if Cα(T1)≤Cα(T2) then 进行剪枝(pruning) end if3: 返回第2步,直至不能继续为止,得到损失函数最小的子树T’
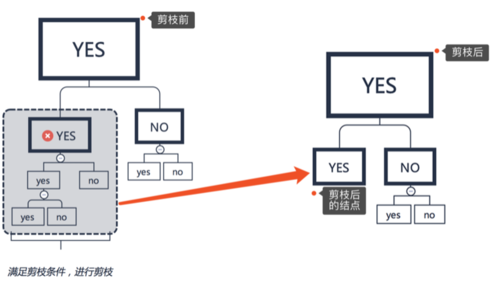
由于是自底向上的剪枝,因此可以用动态规划(DP)实现。实际对于CART决策树还有专门针对决策树的剪枝算法,下次再补充。
文中可能会有错误,欢迎大家指正。
作者:ChongmingLiu
链接:https://www.jianshu.com/p/38aa0daf6841





