
这是众多卷积神经网络可视化方法之一,方法来自于论文《Learning Deep Features for Discriminative Localization》,论文译文在[翻译]Learning Deep Features for Discriminative Localization。
这篇文章的核心思想是提出了一种叫Class Activation Mapping(类激活图)的方法,可以通过它将CNN在分类时“看”到的东西可视化出来。它的原理是:CNN的卷积层包含大量位置信息,使其具有良好的定位能力,但是全连接层使这种能力丧失,如果只保留最后一个用于分类的全连接层(特指softmax),把其余全连接层替换成全局平均池化层(Global Average Pooling)层,就可以保留这中定位能力,把最后一个softmax层各个单元的权重与最后一个卷积层的输出相乘(求加权总和),绘制热成像图,得到的结果就是一个类激活图。
举个例子,假设图片经过最后一个卷积层的shape为(14,14,512),第一维和第二维代表宽高,第三维代表卷积层深度,softmax层的shape为(512,10),第一维代表unit数,第二维代表分类数,想得到某一个类的类激活图,就用通过最后一个卷积层的矩阵乘以sotfmax某类的矩阵,即(14,14,512)的矩阵乘以(512,1)的矩阵,得到(14,14,1)的矩阵,也就是那个类的类激活图,下面是类激活图
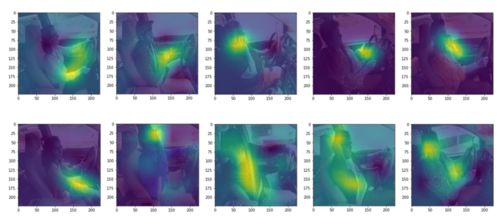
司机驾驶状态分类
论文中提到最后一个卷积层输出的分辨率越高,定位能力越强,得到的CAM图越好。对应的处理方法就是不仅要砍掉全连接层,还要砍掉一些卷积层,使分辨率控制在14左右。下面是论文中图,与上图最大差别就是有红色,原因可能是分辨率问题,也可能单纯是颜色表示问题,还需要进一步实验确定,但是并不影响可视化,分类准确率也在90%以上。

狗分类
其实到这里很自然会有一个疑问:砍掉那么多层,准确率会不会降低?
答案是肯定的,但不会降低很多,可以通过微调来保持网络准确率。
下面是大家最关心的代码部分,我使用的基于TensorFlow的Keras,所以颜色通道在最后,使用其他框架的同学调一下就好,过段时间会放到Github仓库
def visualize_class_activation_map(model, img_path, target_class): ''' 参数: model:模型 img_path:图片路径 target_class:目标类型 ''' origin_img = get_im_cv2([img_path], 224, 224, 3) # 这是一个自定义读取图片函数 class_weights = model.layers[-1].get_weights()[0] # 取最后一个softmax层的权重 final_conv_layer = model.layers[17] # 这是最后一个卷积层的索引 get_output = K.function([model.layers[0].input],[final_conv_layer.output, model.layers[-1].output]) [conv_outputs, predictions] = get_output([origin_img]) conv_outputs = conv_outputs[0, :, :, :] cam = np.zeros(dtype=np.float32, shape=(14, 14)) for i, w in enumerate(class_weights[:, target_class]): cam += conv_outputs[:, :, i] * w cam = cv2.resize(cam, (224, 224)) cam = 100 * cam plt.imshow(origin_img[0]) plt.imshow(cam, alpha=0.8, interpolation='nearest') plt.show()
作者:刘开心_8a6c
链接:https://www.jianshu.com/p/641a6fc97117





