
据集:MNIST
框架:Keras
显卡:NVIDIA GEFORCE 750M
参考:Keras中文文档
这是优达学城的深度学习项目,数据集和需求都很简单,关键是为了熟悉框架的使用以及项目搭建的套路,只要用很简单的卷积神经网络就能实现,准确率轻轻松松就能上90%。
需求描述
随机从MNIST数据集中选择5个或5个以下的数字,拼成一张图片,如下图所示。搭建一个模型,识别图片中的数字,空白字符的类型为0。

imgs and labels
项目实战
载入数据集
keras有
from keras.datasets import mnist(X_raw, y_raw), (X_raw_test, y_raw_test) = mnist.load_data() n_train, n_test = X_raw.shape[0], X_raw_test.shape[0]
查看数据集
import matplotlib.pyplot as pltimport random
%matplotlib inline
%config InlineBackend.figure_format = 'retina'for i in range(15):
plt.subplot(3, 5, i+1)
index = random.randint(0, n_train-1)
plt.title(str(y_raw[index]))
plt.imshow(X_raw[index], cmap='gray')
plt.axis('off')
dataset
合成数据
载入数据集的时候将数据集分成了训练集X_raw和测试集X_test,这里需要从X_raw中随机选取数字,然后拼成新的图片,并将20%设为验证集,防止模型过拟合。
注意:数字的长度不一定为5,不到5的以空白填充,最终图片高28长28x5=140
为什么将数据分成训练集、验证集和测试集?
训练集是用来训练模型的;验证集是用来对训练的模型进行进一步调参优化,如果使用测试集验证,网络就会记住测试集,容易使模型过拟合;测试集用来测试模型表现。
难点:
原图是28x28,拼成28x140,原来一行有28,现在一行有140,是每行做的append,用list.append效率会很低,用矩阵转置就会很快。
import numpy as npfrom sklearn.model_selection import train_test_split n_class, n_len, width, height = 11, 5, 28, 28def generate_dataset(X, y): X_len = X.shape[0] # 原数据集有几个,新数据集还要有几个 # 新数据集的shape为(X_len, 28, 28*5, 1),X_len是X的个数,原数据集是28x28,取5个数字(包含空白)拼接,则为28x140, 1是颜色通道,灰度图,所以是1 X_gen = np.zeros((X_len, height, width*n_len, 1), dtype=np.uint8) # 新数据集对应的label,最终的shape为(5, X_len,11) y_gen = [np.zeros((X_len, n_class), dtype=np.uint8) for i in range(n_len)] for i in range(X_len): # 随机确定数字长度 rand_len = random.randint(1, 5) lis = list() # 设置每个数字 for j in range(0, rand_len): # 随机找一个数 index = random.randint(0, X_len - 1) # 将对应的y置1, y是经过onehot编码的,所以y的第三维是11,0~9为10个数字,10为空白,哪个索引为1就是数字几 y_gen[j][i][y[index]] = 1 lis.append(X[index].T) # 其余位取空白 for m in range(rand_len, 5): # 将对应的y置1 y_gen[m][i][10] = 1 lis.append(np.zeros((28, 28),dtype=np.uint8)) lis = np.array(lis).reshape(140,28).T X_gen[i] = lis.reshape(28,140,1) return X_gen, y_gen X_raw_train, X_raw_valid, y_raw_train, y_raw_valid = train_test_split(X_raw, y_raw, test_size=0.2, random_state=50) X_train, y_train = generate_dataset(X_raw_train, y_raw_train) X_valid, y_valid = generate_dataset(X_raw_valid, y_raw_valid) X_test, y_test = generate_dataset(X_raw_test, y_raw_test)
显示合成的图片
# 显示生成的图片for i in range(15):
plt.subplot(5, 3, i+1)
index = random.randint(0, n_test-1)
title = ''
for j in range(n_len):
title += str(np.argmax(y_test[j][index])) + ','
plt.title(title)
plt.imshow(X_test[index][:,:,0], cmap='gray')
plt.axis('off')
合成的图片
CNN搭建
使用了keras的函数式模型,很方便,可以参考官方文档。
由于数据集比较简答,所以随便一个网络结构都能有不错的表现,我用的是两层卷机模型,卷积层、最大池化层、卷积层、最大池化层,然后两个全连接层。
from keras.models import Modelfrom keras.layers import *import tensorflow as tf# This returns a tensorinputs = Input(shape=(28, 140, 1)) conv_11 = Conv2D(filters= 32, kernel_size=(5,5), padding='Same', activation='relu')(inputs) max_pool_11 = MaxPool2D(pool_size=(2,2))(conv_11) conv_12 = Conv2D(filters= 10, kernel_size=(3,3), padding='Same', activation='relu')(max_pool_11) max_pool_12 = MaxPool2D(pool_size=(2,2), strides=(2,2))(conv_12) flatten11 = Flatten()(max_pool_12) hidden11 = Dense(15, activation='relu')(flatten11) prediction1 = Dense(11, activation='softmax')(hidden11) hidden21 = Dense(15, activation='relu')(flatten11) prediction2 = Dense(11, activation='softmax')(hidden21) hidden31 = Dense(15, activation='relu')(flatten11) prediction3 = Dense(11, activation='softmax')(hidden31) hidden41 = Dense(15, activation='relu')(flatten11) prediction4 = Dense(11, activation='softmax')(hidden41) hidden51 = Dense(15, activation='relu')(flatten11) prediction5 = Dense(11, activation='softmax')(hidden51) model = Model(inputs=inputs, outputs=[prediction1,prediction2,prediction3,prediction4,prediction5]) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
可视化网络
依赖 pydot-ng 和 graphviz,若出现错误,用命令行输入pip install pydot-ng & brew install graphviz
windows需要安装一下graphviz,配置一下环境
from keras.utils.vis_utils import plot_model, model_to_dotfrom IPython.display import Image, SVG SVG(model_to_dot(model).create(prog='dot', format='svg'))
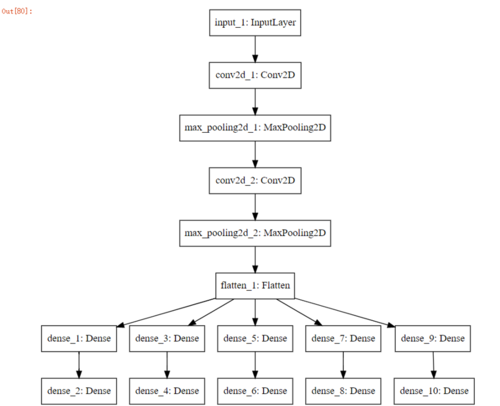
网络可视化
训练模型
训练20代,如果验证集上的准确率连续两次没有提高,就减小学习率。显卡不是很好,但依然很快,大概20分钟左右就学好了。
from keras.callbacks import ReduceLROnPlateau learnrate_reduce_1 = ReduceLROnPlateau(monitor='val_dense_2_acc', patience=2, verbose=1,factor=0.8, min_lr=0.00001) learnrate_reduce_2 = ReduceLROnPlateau(monitor='val_dense_4_acc', patience=2, verbose=1,factor=0.8, min_lr=0.00001) learnrate_reduce_3 = ReduceLROnPlateau(monitor='val_dense_6_acc', patience=2, verbose=1,factor=0.8, min_lr=0.00001) learnrate_reduce_4 = ReduceLROnPlateau(monitor='val_dense_8_acc', patience=2, verbose=1,factor=0.8, min_lr=0.00001) learnrate_reduce_5 = ReduceLROnPlateau(monitor='val_dense_10_acc', patience=2, verbose=1,factor=0.8, min_lr=0.00001) model.fit(X_train, y_train, epochs=20, batch_size=128, validation_data=(X_valid, y_valid), callbacks=[learnrate_reduce_1,learnrate_reduce_2,learnrate_reduce_3,learnrate_reduce_4,learnrate_reduce_5])
计算模型准确率
5个数字全部识别正确为正确,错一个即为错。可以用循环一一比对,我这里用了些概率论知识,因为都是独立事件,所以5个数字的准确率乘起来就是模型准确率。
def evaluate(model): # TODO: 按照错一个就算错的规则计算准确率. result = model.evaluate(np.array(X_test).reshape(len(X_test),28,140,1), [y_test[0], y_test[1], y_test[2], y_test[3], y_test[4]], batch_size=32) return result[6] * result[7] * result[8] * result[9] * result[10] evaluate(model)
最后可以得到0.9476的正确率。
预测值可视化
def get_result(result):
# 将 one_hot 编码解码
resultstr = ''
for i in range(n_len):
resultstr += str(np.argmax(result[i])) + ','
return resultstr
index = random.randint(0, n_test-1)
y_pred = model.predict(X_test[index].reshape(1,28,140,1))
plt.title('real: %s\npred:%s'%(get_result([y_test[x][index] for x in range(n_len)]), get_result(y_pred)))
plt.imshow(X_test[index,:,:,0], cmap='gray')
plt.axis('off')
预测结果可视化
保存模型
model.save('model.h5')
作者:刘开心_8a6c
链接:https://www.jianshu.com/p/79265078c95b





