
前 言
Seq2Seq,全称Sequence to Sequence。它是一种通用的编码器——解码器框架,可用于机器翻译、文本摘要、会话建模、图像字幕等场景中。Seq2Seq并不是GNMT(Google Neural Machine Translation)系统的官方开源实现。框架的目的是去完成更广泛的任务,而神经机器翻译只是其中之一。在循环神经网络中我们了解到如何将一个序列转化成定长输出。在本文中,我们将探究如何将一个序列转化成一个不定长的序列输出(如机器翻译中,源语言和目标语言的句子往往并没有相同的长度)。
简单入门
(1)****设计目标
通用
这个框架最初是为了机器翻译构建的,但是后来使用它完成了各种其他任务,包括文本摘要、会话建模和图像字幕。只要我们的任务,可以将输入数据以一种格式编码并将其以另一种格式解码,我们就可以使用或者扩展这个框架。可用性
支持多种类型的输入数据,包括标准的原始文本。重现性
用YAML文件来配置我们的pipelines和models,容易复现。可扩展性
代码以模块化的方式构建,添加一种新的attention机制或编码器体系结构只需要最小的代码更改。文档化:所有的代码都使用标准的Python文档字符串来记录,并且编写了使用指南来帮助我们着手执行常见的任务。
良好的性能:为了代码的简单性,开发团队并没有试图去尽力压榨每一处可能被拓展的性能,但是对于几乎所有的生产和研究项目,当前的实现已经足够快了。此外,tf-seq2seq还支持分布式训练。
(2)****主要概念
Configuration
许多objects都是使用键值对来配置的。这些参数通常以YAML的形式通过配置文件传递,或者直接通过命令行传递。配置通常是嵌套的,如下例所示:
model_params: attention.class: seq2seq.decoders.attention.AttentionLayerBahdanau attention.params: num_units: 512 embedding.dim: 1024 encoder.class: seq2seq.encoders.BidirectionalRNNEncoder encoder.params: rnn_cell: cell_class: LSTMCell cell_params: num_units: 512
Input Pipeline
InputPipeline定义了如何读取、解析数据并将数据分隔成特征和标签。如果您想要读取新的数据格式,我们需要实现自己的输入管道。
Encoder(编码)
Decoder(解码)
Model(Attention)
Encoder-Decoder
整个过程可以用下面这张图来诠释:

image
图 1:最简单的Encoder-Decoder模型
其中,X、Y均由各自的单词序列组成(X,Y可以是同一种语言,也可以是两种不同的语言):
X = (x1,x2,...,xm)
Y = (y1,y2,...,yn)
Encoder:是将输入序列通过非线性变换编码成一个指定长度的向量C(中间语义表示),得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
C = F(x1,x2,...,xm)
Decoder:是根据向量C(encoder的输出结果)和之前生成的历史信息y1,y2,...,yn来生成i时刻要生成的单词yi。
yi = G( C , y1,y2,...,yn-1)
下图是一个生成对联的示意图。

image
图 2:生活中的小栗子
编码阶段
在RNN中,当前时间的隐藏状态由上一时间的状态和当前时间输入决定的,即:
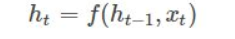
image
获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后的语义向量

image
当然,有一种最简单的方法是将最后的隐藏层作为语义向量C,即

image
解码阶段
可以看做编码的逆过程。这个阶段,我们根据给定的语义向量C和之前已经生成的输出序列y1,y2,...,yt-1来预测下一个输出的单词yt,即

image
也可以写作

image
在RNN中,也可以简化成

image
其中s是输出RNN(即RNN解码器)中的隐藏层,C代表之前编码器得到的语义向量,yt-1表示上个时间段的输出,反过来作为这个时间段的输入。g可以是一个非线性的多层神经网络,产生词典中各个词语属于yt的概率。
Attention模型
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,二是先输入的内容携带的信息会被后输入的信息稀释掉。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码时准确率就要打一定折扣。 为了解决上述问题,在 Seq2Seq出现一年之后,Attention模型被提出了。该模型在产生输出的时候,会产生一个注意力范围来表示接下来输出的时候要重点关注输入序列的哪些部分,然后根据关注的区域来产生下一个输出,如此反复。attention 和人的一些行为特征有一定相似之处,人在看一段话的时候,通常只会重点注意具有信息量的词,而非全部词,即人会赋予每个词的注意力权重不同。attention 模型虽然增加了模型的训练难度,但提升了文本生成的效果。模型的大概示意图如下。

image
图 3:经典的attention模型
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用 aij 衡量编码中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 ci 就来自于所有 hj对 aij的加权和。

image
图 4:不同关注度示意图
输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的 a11就比较大,而相应的 a12 、a13 、 a14 就比较小。c2应该和“爱”最相关,因此对应的 a22 就比较大。最后的c3和h3、h4最相关,因此 a33 、 a34的值就比较大。具体模型权重 aij 是如何计算出来的呢?
比如:
输入的是英文句子:Tom chase Jerry,生成:“汤姆”,“追逐”,“杰瑞”。
注意力分配概率分布值的通用计算过程:

image
图 5:权重计算示意图
当前输出词Yi针对某一个输入词j的注意力权重由当前的隐层Hi,以及输入词j的隐层状态(hj)共同决定;然后再接一个sofrmax得到0-1的概率值。即通过函数F(hj,Hi)来获得目标单词Yi和每个输入单词对应的对齐可能性。更多细节,请大家参看知乎何之源的文章,文末会给出文章链接。
CNN的seq2seq
现在大多数场景下使用的Seq2Seq模型是基于RNN构成的,虽然取得了不错的效果,但也有一些学者发现使用CNN来替换Seq2Seq中的encoder或decoder可以达到更好的效果。最近,FaceBook发布了一篇论文:《Convolutional Sequence to Sequence Learning》,提出了完全使用CNN来构成Seq2Seq模型,用于机器翻译,超越了谷歌创造的基于LSTM机器翻译的效果。此网络获得暂时性胜利的重要原因在于采用了很多的窍门,这些技巧值得学习:
捕获long-distance依赖关系
底层的CNN捕捉相聚较近的词之间的依赖关系,高层CNN捕捉较远词之间的依赖关系。通过层次化的结构,实现了类似RNN(LSTM)捕捉长度在20个词以上的Sequence的依赖关系的功能。
效率高
假设一个sequence序列长度为n,采用RNN(LSTM)对其进行建模 需要进行n次操作,时间复杂度O(n)。相比,采用层叠CNN只需要进行n/k次操作,时间复杂度O(n/k),k为卷积窗口大小。
并行化实现
RNN对sequence的建模依赖于序列的历史信息,因此不能并行实现。相比,层叠CNN对整个sequence进行卷积,不依赖序列历史信息,可以并行实现,特别是在工业生产,面临处理大数据量和实时要求比较高的情况下,模型训练更快。
融合多层attention
融合了Residual connection、liner mapping的多层attention。通过attention决定输入的哪些信息是重要的,并逐步往下传递。把encoder的输出和decoder的输出做点乘(dot products),再归一化,再乘以encoder的输入X之后做为权重化后的结果加入到decoder中预测目标语言序列。
gate mechanism
采用GLU做为gate mechanism。GLU单元激活方式如下公式所示:

image
进行了梯度裁剪和精细的权重初始化,加速模型训练和收敛
基于CNN的seq2seq模型和基于LSTM的Seq2Seq模型孰好孰坏,我们不能妄加评判。采用CNN的Seq2Seq最大的优点在于速度快,效率高,缺点就是需要调整的参数太多。在CNN和RNN用于NLP问题时,CNN也是可行的,且网络结构搭建更加灵活,效率高,由于RNN训练时往往需要前一时刻的状态,很难并行,特别是在大数据集上,CNN-Seq2Seq往往能取得比RNN-Seq2Seq更好的效果。
应用领域
**机器翻译 **

image
<center style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important;">图 6:采用Seq2Seq效果对比</center>
从图像可以看出,模型中的语境向量很明显的包涵了输入序列的语言意义,能够将由不同次序所产生的不同意思的语句划分开来,这对于提升机器翻译的准确率很有帮助。当前,主流的在线翻译系统都是基于深度学习模型来构建的,包括 Google、百度等。
**语音识别 **
输入是语音信号序列,输出是文字序列。**文本摘要 **
输入是一段文本序列,输出是这段文本序列的摘要序列。通常将文本摘要方法分为两类,extractive 抽取式摘要和 abstractive 生成式摘要。前者是从一篇文档或者多篇文档中通过排序找出最有信息量的句子,组合成摘要;后者类似人类编辑一样,通过理解全文的内容,然后用简练的话将全文概括出来。在应用中,extractive摘要方法更加实用一些,也被广泛使用,但在连贯性、一致性上存在一定的问题,需要进行一些后处理;abstractive 摘要方法可以很好地解决这些问题,但研究起来非常困难。**对话生成 **
Seq2Seq 模型提出之后,就有很多的工作将其应用在 Chatbot 任务上,希望可以通过海量的数据来训练模型,做出一个智能体,可以回答任何开放性的问题;而另外一拨人,研究如何将 Seq2Seq 模型配合当前的知识库来做面向具体任务的 Chatbot,在一个非常垂直的领域(比如:购买电影票等)也取得了一定的进展。

image
<center data-anchor-id="p096" style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important; color: rgb(44, 62, 80);">图 7:对话生成Chatbot</center>
**诗词生成 ** 让机器为你写诗并不是一个遥远的梦,Seq2Seq 模型一个非常有趣的应用正是诗词生成,即给定诗词的上一句来生成下一句。
**生成代码补全 **
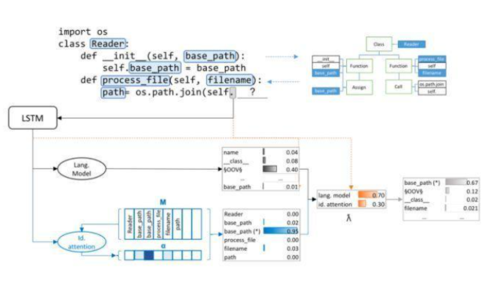
image
<center style="margin: 0px; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important;">图 8:代码补全示意图</center>
**预训练 ** 2015年,Google提出了将Seq2Seq的自动编码器作为LSTM文本分类的一个预训练步骤,从而提高了分类的稳定性。这使得Seq2Seq技术的目的不再局限于得到序列本身,为其应用领域翻开了崭新的一页。
阅读理解
将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
小结
Seq-to-Seq模型从一开始在机器翻译领域被提出,到后来被广泛应用到NLP各个领域,原因就在于其对序列数据的完美使用,而且解决了以前RNN模型输出维度固定的难题,所以很快得到了推广。但Seq-to-Seq不是万能药,只有在合适的场景,它才能发挥它最大的作用。
参考资料
《Convolutional Sequence to Sequence Learning》:
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1705.03122《Language modeling with gated linear units》:
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1612.08083《A Convolutional Encoder Model for Neural Machine Translation》:
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1611.02344Google Neural Machine Translation:
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html简书:Datartisan
https://www.jianshu.com/p/124b777e0c55PaperWeekly:张俊
https://zhuanlan.zhihu.com/p/26753131
作者:机器学习算法工程师
链接:https://www.jianshu.com/p/226502603066





