
在前面章节中,我们花费大量精力详细解析了神经网络的内在原理。神经网络由如下4个部分组成:
1,神经层,每层由多个神经元组合而成。
2,输入训练数据,已经数据对应的结果标签
3,设计损失函数,也就是用数学公式来表示,神经网络的输出结果与正确结果之间的差距。
4,优化,通过梯度下降法修改神经元的链路权重,然后使得网络的输出结果与正确结果之间的差距越来越小。
下图就能将网络的各个组件以及我们前面讨论过的内容综合起来:

屏幕快照 2018-06-19 上午10.58.04.png
神经网络的学习过程,其实就是把大量数据输入,让网络输出结果,计算结果与预期结果间的差距,通过梯度下降法修改神经元链路权重,以便降低输出结果与预期结果的差距。这个流程反复进行,数据量越大,该流程进行的次数越多,链路权重的修改就能越精确,于是网络输出的结果与预期结果就越准确。
本节我们将神经网络技术直接运用到具体的项目实践上,我们用神经网络来判断用户在网络上编写的影评中包含的是正能量还是负能量,如果对电影正能量的影评越多,电影的票房便会越好,负能量影评越多,电影票房可能就会暗淡。在项目中我们不再像以前一样从零创建一个网络,而是直接使用keras框架快速的搭建学习网络。
首先要做的是将影评数据下载到本地,我们使用的是国外著名电影评论网站IDMB的数据,数据有60000条影评,其中一半包含正能量,另一半包含负能量,这些数据将用于训练我们的网络,数据的下载代码如下:
from keras.datasets import imdb(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
数据流不小,下载可能需要几十秒,运行上面代码后,结果如下:

屏幕快照 2018-06-19 上午11.04.58.png
数据中的评论是用英语拟写的文本,我们需要对数据进行预处理,把文
本变成数据结构后才能提交给网络进行分析。我们当前下载的数据条目中,包含的已经不是原来的英文,而是对应每个英语单词在所有文本中的出现频率,我们加载数据时,num_words=10000,表示数据只加载那些出现频率排在前一万位的单词。我们看看数据内容:
print(train_data[0])print(train_labels[0])
上面带运行后结果如下:

屏幕快照 2018-06-19 上午11.10.42.png
train_data的一个元素的值是1,它对应的是频率出现排在第一位的单词,假设频率出现最高的单词是"is",那么train_data第1个元素对应的单词就是"is",以此类推。train_lables用来存储对应影评是正能量还是负能量,1表示正能量,0表示负能量。
接下来我们尝试根据train_data中给定的单词频率,把单词还原回来。频率与单词的对应存储在imdb.get_word_index()返回的哈希表中,通过查询该表,我们就能将频率转换成对应的单词,代码如下:
#频率与单词的对应关系存储在哈希表word_index中,它的key对应的是单词,value对应的是单词的频率word_index = imdb.get_word_index()#我们要把表中的对应关系反转一下,变成key是频率,value是单词reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) ''' 在train_data所包含的数值中,数值1,2,3对应的不是单词,而用来表示特殊含义,1表示“填充”,2表示”文本起始“, 3表示”未知“,因此当我们从train_data中读到的数值是1,2,3时,我们要忽略它,从4开始才对应单词,如果数值是4, 那么它表示频率出现最高的单词 '''decoded_review = ' '.join([reverse_word_index.get(i-3, '?') for i in train_data[0]]) print(decoded_review)
上面这段代码运行后,我们把条目一的影评还原如下:
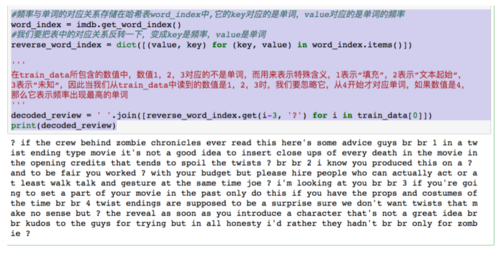
屏幕快照 2018-06-19 上午11.32.26.png
对英语不好的同学可能会吃力点,但没办法,这些标记好的训练数据只有英语才有,中文没有相应的训练数据,从这点看可以明白,为何西方人的科技会领先中国,他们有很多人愿意做一些为他人铺路的工作。
在把数据输入网络前,我们需要对数据进行某种格式化,数据的格式对网络的分析准确性具有很大的影响。在深度学习中,有一种常用的数据格式叫:one-hot-vector,它的形式是这样的,假设集合中总共有10个整数{0,1,2,3,4,5,6,7,8,9},我们选取一个子集,它包含所有偶数,也就是{0,2,4,6,8},那么对应的one-hot-vector就是一个含有10个元素的向量,如果某个元素出现在子集中,我们就把向量中对应的元素设置为1,没有出现则设置为0,于是对应子集的向量就是:[1, 0, 1, 0, 1, 0, 1, 0, 1, 0]。
由于文本中只包含10000个单词,于是我们设置一个长度为一万的向量,当某个频率的词出现在文章中时,我们就把向量相应位置的元素设置成1,代码如下:
import numpy as npdef vectorize_sequences(sequences, dimension=10000):
'''
sequences 是包含所有评论的序列,一条评论对应到一个长度为10000的数组,因此我们要构建一个二维矩阵,
矩阵的行对应于评论数量,列对应于长度为10000
'''
results = np.zeros((len(sequences),dimension)) for i, sequence in enumerate(sequences):
results[i, sequence] = 1.0
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
print(x_train[0])
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')经过上面的格式化后,网络的输入数据就是简单的向量,训练数据对应的结果就是简单的0或1。接下来我们要构建一个三层网络,代码如下:
from keras import modelsfrom keras import layers model = models.Sequential()#构建第一层和第二层网络,第一层有10000个节点,第二层有16个节点#Dense的意思是,第一层每个节点都与第二层的所有节点相连接#relu 对应的函数是relu(x) = max(0, x)model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))#第三层有16个神经元,第二层每个节点与第三层每个节点都相互连接model.add(layers.Dense(16, activation='relu'))#第四层只有一个节点,输出一个0-1之间的概率值model.add(layers.Dense(1, activation='sigmoid'))
上面代码构造了一个四层网络,第一层含有10000个神经元,用于接收长度为10000的文本向量,第二第三层都含有16个神经元,最后一层只含有一个神经元,它输出一个概率值,用于标记文本含有正能量的可能性。
接下来我们设置损失函数和设置链路参数的调教方式,代码如下:
from keras import lossesfrom keras import metricsfrom keras import optimizers model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])
optimizer参数指定的是如何优化链路权重,事实上各种优化方法跟我们前面讲的梯度下降法差不多,只不过在存在一些微小的变化,特别是在更新链路权值时,会做一些改动,但算法主体还是梯度下降法。当我们的网络用来将数据区分成两种类型时,损失函数最好使用binary_crossentroy,它的表达式如下:
Hy′(y):=−∑i(y′ilog(y[i])+(1−y′[i])log(1−y[i]))
其中y[i]对应的是训练数据提供的结果,y'[i]是我们网络计算所得的结果。metrics用于记录网络的改进效率,我们暂时用不上。接着我们把训练数据分成两部分,一部分用于训练网络,一部分用于检验网络的改进情况:
x_val = x_train[:10000] partial_x_train = x_train[10000:] y_val = y_train[: 10000] partial_y_train = y_train[10000:]history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=512, validation_data = (x_val, y_val))
训练数据总共有60000条,我们把最前一万条作为校验数据,用来检测网络是否优化到合适的程度,然后我们把数据从第一万条开始作为训练网络来用,把数据分割好后,调用fit函数就可以开始训练过程,上面代码运行后结果如下:

屏幕快照 2018-06-19 下午5.38.26.png
我把代码运行结果最后部分信息截取出来。我们看到loss的值越来越小,这意味着网络越来越能准确的识别训练数据的类型,但是校验数据的识别准确度却越来越低,也就是我们的模型只试用与训练数据,不适用与校验数据,这意味着我们的训练过程有问题。fit函数返回的history对象记录了训练过程中,网络的相关数据,通过分析这些数据,我们可以了解网络是如何改进自身的,它是一个哈希表,记录了四种内容:
history_dict = history.historyprint(history_dict.keys())
上面输出结果如下:
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
它记录了网络对训练数据识别的精确度和对校验数据识别的精确度。我们把数据画出来看看:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)#绘制训练数据识别准确度曲线plt.plot(epochs, loss, 'bo', label='Trainning loss')#绘制校验数据识别的准确度曲线plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Trainning and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()上面代码运行后结果如下:

屏幕快照 2018-06-19 下午5.48.15.png
我们看上面图示能发现一个问题,随着迭代次数的增加,网络对训练数据识别的准确度越来越高,也就是loss越来越低,然后校验数据的识别准确的却越来越低,这种现象叫“过度拟合”,这意味着训练的次数并不是越多越好,而是会“过犹不及”,有时候训练迭代次数多了反而导致效果下降。从上图我们看到,大概在第4个epoch的时候,校验数据的识别错误率开始上升,因此我们将前面的代码修改,把参数epochs修改成4才能达到最佳效果。
训练好网络后,我们就可以用它来识别新数据,我们把测试数据放入网络进行识别,代码如下:
model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=4, batch_size=512) results = model.evaluate(x_test, y_test)
上面代码运行后结果如下:

这里写图片描述
results有两个值,第二个表示的是判断的准确度,从结果我们可以看到,网络经过训练后,对新的影评文本,其对其中正能量和负能量的判断准确率达到88%。对于专业的项目实施,经过巧妙的调优,各种参数的调整,多增加网络的层次等方法,准确率可以达到95%左右。接着我们看看网络对每一条测试文本得出它是正能量的几率:
model.predict(x_test)
代码运行后结果如下:

这里写图片描述
网络对每一篇影评给出了其是正能量的可能性。
我们的网络还有不少可以尝试改进的地方,例如在中间多增加两层神经元,改变中间层神经元的数量,将16改成32,64等,尝试使用其他损失函数等。
从整个项目流程我们看到,一个神经网络在实践中的应用需要完成以下几个步骤:
1,将原始数据进行加工,使其变成数据向量以便输入网络。
2,根据问题的性质选用不同的损失函数和激活函数,如果网络的目标是将数据区分成两类,那么损失函数最好选择binary_crossentropy,输出层的神经元如果选用sigmoid激活函数,那么它会给出数据属于哪一种类型的概率。
3,选取适当的优化函数,几乎所有的优化函数都以梯度下降法为主,只不过在更新链路权重时,有些许变化。
4,网络的训练不是越多越好,它容易产生“过度拟合”的问题,导致训练的越多,最终效果就越差,所以在训练时要密切关注网络对检验数据的判断准确率。
作者:望月从良
链接:https://www.jianshu.com/p/be447ac804db





