
1. Abstract
最近小弟参加了腾讯广告算法竞赛,虽然之前做了一次总结。但我觉得之前那个可能有点泛泛而谈,因此本次想仔细的讲讲关于CTR\推荐算法常用的一些模型。对于CTR预测或者推荐算法,数据大多主要是用户数据和推荐的商品,广告数据。这些数据都有一个很大的特点:稀疏。在机器学习上面。我们通常把这些问题使用有监督学习算法做二分类预测,我们将其看作一个概率模型P(click| product data, user data)。CTR在很多互联网公司都是及其重要的,因为提高点击率带来流量和收益。无论是工程上还是数据分析上,CTR问题都是很有挑战性:
数据量巨大:像一些大型的电商网站,游戏app,我们都会收集到大量的用户的数据和商品信息(上亿万级,可能上百G)。对于如此大量的数据,我们就应该考虑如何将所拥有的数据放入模型中训练。
特征维度高且稀疏:像电商平台里面,商品数据大多是都category,one label。当我们将其转化为one-hot并合并时,数据维度有可能爆炸。因此我们需要考虑如何处理好这些one label问题
存在时间序列:这些数据不是一成不变的,点击事件是不停产生。所以我们需要处理点击事件的时间序列问题。
2. Model
CTR预测需要很强的业务思考能力,找出一些强特征。有强特征,一切都好办。在机器学习里面,我们都认为我们手上的特征和数据决定我们预测的上面,而模型只是不同的逼近这个上限。所以业务能力和特征工程在CTR上是及其重要的一环。有了好的特征,我们用LR也能得到很好的结果。当然现在我们在工程上面,希望能降低data mining的能力,快速得到很好的结果(这不是说data mining不重要,而是我们希望能够弱化其难度但也能得到很好结果)。随着NN的快速发展,业界出现了很多效果棒且不需很强data mining能力的,例如GBDT + LR,FM,FFM,FNN,PNN,deepFM,NFFM等等。这里我介绍一些我用过的模型。
2.1 FM (Factorization Machines)
FM在线性模型上加入以下特性:
考虑特征之间的关联性
将稀疏的特征用一个特征向量表示,使得特征从稀疏变得稠密

FM模型数学表达
在前面的w_0与w_i作为参数组成了线性模型,而后项考虑到特征之间的相关性。而v_i和v_j是x_i和x_j的代表向量特征。本来这个二项式的参数是w_ij代表两两特征之间的相关性。但这样的二项式参数有n(n - 1) / 2,那就是半个矩阵的参数,而其实这个参数矩阵可能很稀疏的,因为不是每两维特征之间存在相关性。所以我们就将矩阵分解成latent vector,w_ij = v_i * v_j。这样一来,参数变少了(n * k,k为vector的长度,k << n),而且没必要训练的变量也变稠密了。
2.2 FFM (Field-aware Factorization Machines)
显然FFM是FM的升级版本。相对于FM,FFM加入的就是field这个概念,field就是原始数据当中的每个字段。在FM当中,我们只考虑到特征的相关性,而没有考虑到field之间的相关性。FFM就是考虑到特征向量对field敏感的。在FM中,向量的个数是n,在FFM中,向量的个数的n * f。
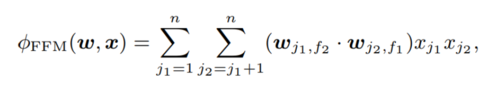
FFM的二项式
与FM不同,FFM的二项式考虑的是特征对应的Field。相对于FM不断增加latent vector长度来提高精度,FFM效果更好。
2.3 DeepFM
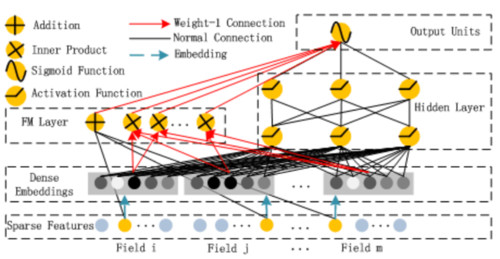
structure of DeepFM
DeepFM对PNN和FM做了整合,它认为FM训练的较为浅层的特征,而PNN训练得到较为深层的特征,于是将其两种整合一齐。因此作者称其为DeepFM。
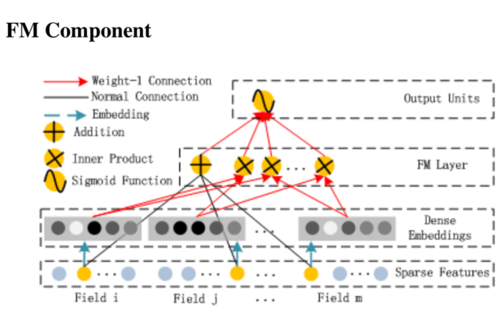
左侧FM structure
作者认为FM中线性组合为一阶特征,交叉组合(内积)是二阶特征。所以这部分就是一个FM模型。
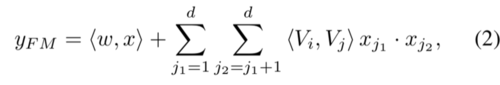
FM公式
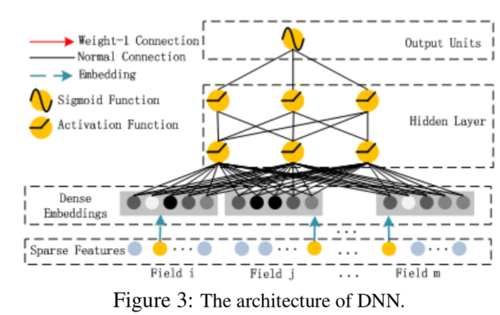
右侧Deep Component
我们将raw feature做embeddings,将其映射到一个稠密的特征向量当中。因为raw feature太稀疏了,在神经网络中是很难训练好的。我们将这些特征映射好以后就将其合并在一齐做DNN,这样我们就得到了高阶特征。
最后如第一副图所示,FM和DNN的输出做多一层NN就在用sigmoid代表其输出概率。而FM和DNN是共享这个embeddings层。embeddings是对Field做的,也就是说基本每个特征都必须是category。相对于FNN和PNN来说,DeepFM无需用FM预训练embedding(FNN),也不像PNN那样只有高阶特征。
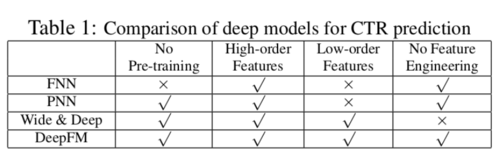
CTR模型之间的对比
可见DeepFM不需要pre-training,不需要feature engineering(傻瓜式),同时既有低阶特征,也有高阶特征。
2.4 GBDT+LR/FM
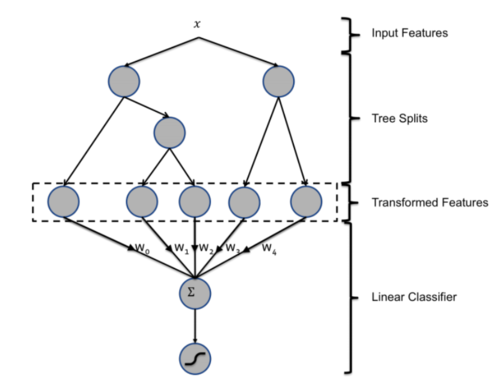
GBDT + LR/FM
看图就能理解了。我们先训练好GBDT,每个叶子节点都有一个权值。那么我们利用这些权值作为特征训练一个LR模型作为我们的输出结果。这个样子有点像迁移学习。代码如下(还是挺简单的。。)
# -*- coding: utf-8 -*-from scipy.sparse.construct import hstackfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_breast_cancerfrom sklearn.linear_model.logistic import LogisticRegressionfrom sklearn.metrics.ranking import roc_auc_scorefrom sklearn.preprocessing.data import OneHotEncoderimport numpy as npimport lightgbm as lgbimport xgboost as xgbdef xgb_lr_train():
data = load_breast_cancer()
X_train, X_valid, y_train, y_valid = train_test_split(data.data, data.target, test_size=0.3)
xgboost = xgb.XGBClassifier(nthread=4, learning_rate=0.08, n_estimators=200, max_depth=5, gamma=0, subsample=0.9,
colsample_bytree=0.5)
xgboost.fit(X_train, y_train)
xgb_valid_auc = roc_auc_score(y_valid, xgboost.predict(X_valid))
print("XGBoost valid AUC: %.5f" % xgb_valid_auc)
X_train_leaves = xgboost.apply(X_train)
X_valid_leaves = xgboost.apply(X_valid)
all_leaves = np.concatenate((X_train_leaves, X_valid_leaves), axis=0)
all_leaves = all_leaves.astype(np.int32)
xgbenc = OneHotEncoder()
X = xgbenc.fit_transform(all_leaves)
(train_rows, cols) = X_train_leaves.shape
lr = LogisticRegression()
lr.fit(X[:train_rows, :], y_train)
xgb_lr_valid_auc = roc_auc_score(y_valid, lr.predict_proba(X[train_rows:, :])[:, 1])
print("XGBoost-LR valid AUC: %.5f" % xgb_lr_valid_auc) # X_train_leaves = lgb_model.apply(X_train)
# X_valid_leaves = lgb_model.apply(X_valid)if __name__ == '__main__':
xgb_lr_train()3. Summary
其实我觉得这些模型都挺实在的,尤其DeepFM,它弱化了特征工程的,让我们可以轻松的把指标提上去。虽然有好的模型,但我这里还是要跟大家讲一句,特征才是重点当中的重点。在CTR,我们要让模型做到更好的个性化,就必须把特征做细粒度,特征越细越具备个性化。这大概是我这段时间做CTR预测的一些想法吧。
Refence
「人徒知枯坐息思为进德之功,殊不知上达之士,圆通定慧,体用双修,即静而动,虽撄而宁。」
作者:Salon_sai
链接:https://www.jianshu.com/p/8c2d0beb9349






