接口咋整?前端数据药神来也
最近我的好友在写项目的时候经常会抱怨数据的来源,的确对于一个前端来说,数据接口数据资源永远是Mock。网上看很多大神python,node玩的飞起。但自我感觉,并没有一套好的流程方案可以走进我们开发的流程中。为了帮助我的好友并且需要数据的你来说,可以仔细的看看整套流程。因为我也是个前端,所以知道大家需要的是什么以及处理的方案。那么就跟着我一起学习下吧!
前言
学海无涯,我希望你可以跟着我的思路简单的实现下,与其临渊羡鱼,不如退而结网。文章中我会详细讲解每一步的操作和细节,nodejs一些常用的API,以及koa2简单的语法,大家也可以由此文开始你的koa2学习,真的很好用的一个web框架。另外文章中也会讲解数据跨域请求的方案和具体实现,最后就是数据的格式化处理和基本请求。三强上场,共唱一出好戏。
技术栈
http.request:node http 模块的request方法可以作为httpclient向服务器发起http请求,爬虫需要向目标链接发起http请求来获得页面信息
cheerio:通过 http 请求到的页面信息,由于缺乏浏览器的dom解析,看起来就是一段凌乱的字符串,实在糟糕好在我们可以使用 cheerio 库将其解析为 dom ,这样我们就可以使用类似 jquery 的语法去分析页面信息
koa2-static: koa-static静态资源中间件,可以访问到我们项目中的静态资源
koa2-cors: 实现数据跨域ajax请求,这个方法关键是在服务器端进行配置
axios + promise:由于node单线程的特性,不可避免的需要用到大量异步编程的写法,层层嵌套的回调写法已经 low 了,来试试 promise 的写法
具体实现
一、环境搭建
创建一个新文件夹,进入之后,我们初始化生产package.json文件
npm init -y
生成的package.json后,安装koa包,这里我们用npm来安装
npm install --save koa
其他的依赖跟上面一样的方式安装,这里就不展开了,写在一起
npm install --save koa-static npm install --save koa2-cors 复制代码
二、nodejs 上场
热身,构建一个爬虫基石
唱戏之前一定要排练好,要有剧本,每个人都应该清楚的知道自己的身份和出场时间。那么每次上台时都需要排练下,热下身。这样才能演绎一出好戏。我们也一样,先来一端代码热热身。在我们的文件夹下新建一个demo01.js吧,然后输入下面一端代码
var http = require('http') // Node.js提供了http模块,用于搭建HTTP服务端和客户端 var url = 'http://www.runoob.com/nodejs/nodejs-tutorial.html'; //输入任何网址都可以 http.get(url,function(res){ //发送get请求 var html='' res.on('data',function(data){ html += data //字符串的拼接 }) res.on('end',function(){ console.log(html) }) }).on('error',function(){ console.log('获取资源出错!') }) 复制代码打开终端,执行node demo01.js命令,你就会看到这个网页所有的html结构,这也是为我们的大戏敲响了第一声锣鼓。
开始我们的表演
在上面我们可以得到这个网页的所有HTML,这就以为着我们可以在这个HTML里去寻找我们需要的资源。nodejs为此提供了一种非常快捷并且方便的cheerio API。前言部分已介绍了它的功能,这里就直接演示怎么操作。 引入我们的cheerio
const cheerio = require('cheerio')
引用之后我们在把它包装一下,让他更像jquery,jquery的有点就是对dom操作的非常的简单
var $ = cheerio.load(html)
接下来就是去我们的html中寻找我们需要的资源了,每个人的需求都是不一样的,这里就以案例为主,去获取imooc上的视频资源。为了让我们的主体(前面热身提到的)可读性良好,因此我们把这部分封装成一个函数,接收html为参数.
function filterChapters(html) { var $ = cheerio.load(html) var chapters = $('.course-wrap') //在html里寻找我们需要的资源的class var courseData = [] // 创建一个数组,用来保存我们的资源 chapters.each(function(item) { //遍历我们的html文档 var chapter = $(this) var chapterTitle = chapter.find('h3').text().replace(/\s/g, "") var videos = chapter.find('.video').children('li') //使用childern去获取下个节点 var chapterData = { chapterTitle: chapterTitle, videos: [] } videos.each(function(item) { //遍历视频中的资源,title,id, url var video = $(this).find('.J-media-item') //同样的方式找到我们需要的class部分 var videoTitle = video.text().replace(/\n/g, "").replace(/\s/g, ""); var id = video.attr('href').split('video/')[1]; //切割我们的href的到我们的id var url = `http://www.imooc.com/video/${id}` // es6字符串模板的方式去通过id拿到我们的视频url chapterData.videos.push({ title:videoTitle, id: id, url: url }) }) courseData.push(chapterData) }) return courseData //返回我们需要的资源 } 复制代码采坑记录:我们得到的资源可能有换行符或者空格符之类的,如果不去除的话后面的json格式就会出错,而却夹带着\n等符号,这显然不是我们需要的格式和数据,因此在我们.text()的时候应该把这些html自带的\n,\t等去除。使用正则和replace API。
var videoTitle = video.text().replace(/\n/g, "").replace(/\s/g, "");
演完收工
拿到我们需要的资源之后,并不会是一个json对象的形式,因此我们还需要加工一次,
var courseData = filterChapters(html) let content = courseData.map((o)=>{ return JSON.stringify(o) // JSON.stringify() 方法用于将 JavaScript 值转换为 JSON 字符串。 }) 复制代码得到我们真正想要的资源以后,接下来就是保存它了。新建一个index.json文件用来存放我们的资源。使用nodejs的fs去写入我们的数据,这里简单介绍下fs,fs应该是node中最常用的api了,其中包含了我们很多需要的操作,比如读,写 下载。有兴趣的同学可以看看文档fs。我们引入fs把爬下来的数据写进我们的index.json文件夹中
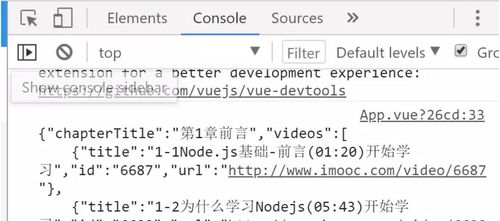
fs.writeFile('./index.json',content, function(err){ //文件路经,写入的内容,回调函数 if(err) throw new Error ('写文件失败'+err); console.log("成功写入文件") }) 复制代码大功告成,我们去看看我们的成果,打开index.json文件我们可以看到我们拍下来的数据了
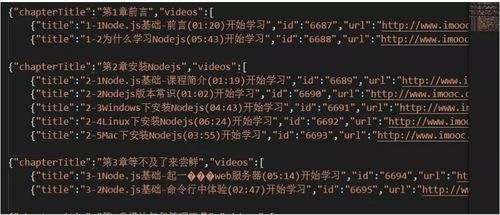
是不是我们需要的数据呢!!!窃喜窃喜。nodejs演技十分的不错!
二、koa2上场
koa 是什么,借用官网的一句话:koa --基于Node.js平台的下一代web开发框架。 它很小,但扩展性很强。Koa给人一种干净利落的感觉,体积小、编程方式干净。为什么我要用一下他呢,nodejs一样可以完成我接下的操作。的确我们也可以用creatServer去创建一个服务,但是作为程序员应该去摄取新知识,尤其是好的受欢迎的,这样才能保持与时俱进!其KOA2真的挺简单,比起node来说。前文已导入了koa,这里还会直接讲如何使用。不懂的同学我觉得可以看看koa官网了解下基本的使用。
思考一:拿到了我们需要的资源后,怎么把它挂在到网上可以请求呢
easyMock, 把爬下来的数据拷贝一份直接丢到Mock里它会帮你创建一个url,就可以访问了。
koa2 启动一个服务,把我们的数据挂载上去,访问端口号
对于一个mock用到快吐的我来说,绝不能忍受爬来的数据又放到mock上。于是开启我们的koa2之旅。
const app = new Koa() const staticPath = './static' //静态文件夹 app.use(static( path.join( __dirname, staticPath) ////设置静态文件地址,这里本来想用路由的但是觉得没必要启动。 )) app.use( async ( ctx ) => { //在我们的页面输出hello world,这里只是为了演示下koa的入门。我们访问我们的静态资源在地址栏加/index.json ctx.body = 'hello world' }) app.listen(3000, () => { //启动一个3000的端口 console.log('[demo] static-use-middleware is starting at port 3000') }) 复制代码思考二: 兴高采烈的那着我的端口去请求数据,发现

koa2-cors 的自我理解:
CORS将请求分为简单请求和非简单请求,可以简单的认为,简单请求就是没有加上额外请求头部的get和post请求,并且如果是post请求,请求格式不能是application/json(因为我对这一块理解不深如果错误希望能有人指出错误并提出修改意见)。而其余的,put、post请求,Content-Type为application/json的请求,以及带有自定义的请求头部的请求,就为非简单请求。简单请求的配置十分简单,如果只是完成响应就达到目的的话,仅需配置响应头部的Access-Control-Allow-Origin即可
解决问题
app.use(cors({ origin: function(ctx) { if (ctx.url === '/index') { return false; } return '*'; }, 复制代码三、axios上场
由于本文重在介绍爬虫并且我最近在写一个vue项目就用这个演示下axios的基本请求,想了解更多axios可以去axios github上理解更多的用法。
methods: { getdata () { axios.get('http://localhost:3000/index.js',{ //访问我们创建的端口 dataType: 'json', contentType:"application/json", crossDomain: true, }) .then(function(response){ console.log(response.data); }) .catch(function(err){ console.log(err); }); } }, mounted () { this.getdata() //可以用async/awiter让你的请求变得更优雅,这里就不做处理。主要是太懒了... } 复制代码请求完数据,我们在控制台打印输出了我们的data