
为了展现 Pandas 的实用性,本文将利用 Pandas 来解决 MovieLen 数据集的一些问题。我们首先回顾下如何将数据集读进 DataFrame 中并将其合并:

评价最多的 25 部电影

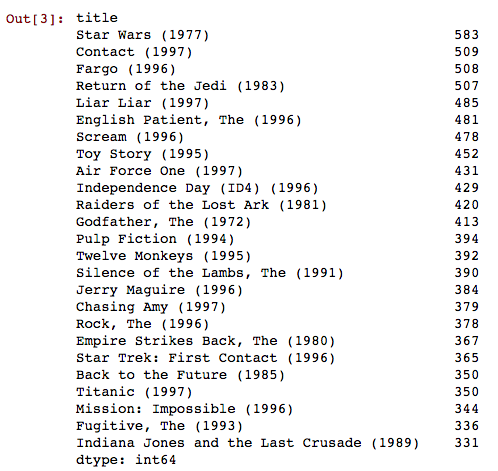
上述代码的含义是先将 DataFrame 按电影标题分组,接下来利用size方法计算每组样本的个数,最后按降序方式输出前 25 条观测值。
在 SQL 中,等价的代码为:
SELECT title, count(1)
FROM lens
GROUP BY title
ORDER BY 2 DESC
LIMIT 25;
此外,在 Pandas 中有一个非常好用的替代函数——value_counts:
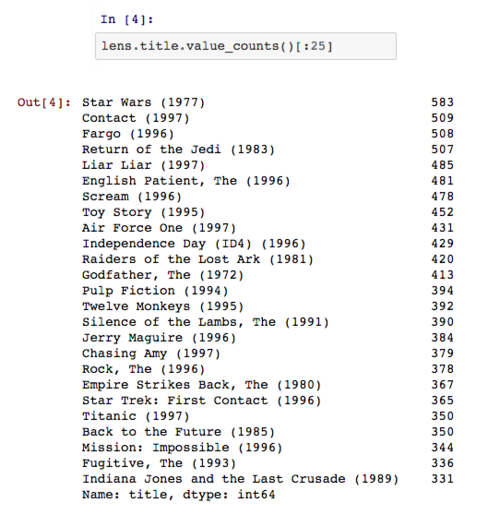
评价最高的电影
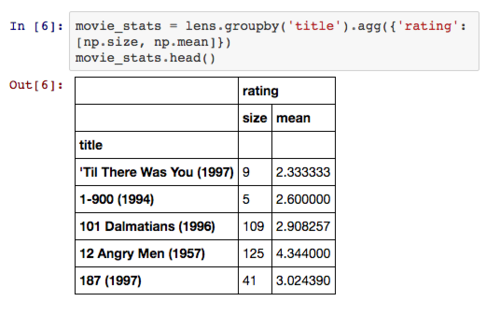
我们可以利用agg方法来进行分组汇总计算,其参数包括键值和汇总方法。接下来我们对汇总结果进行排序即可得到评价最高的电影:
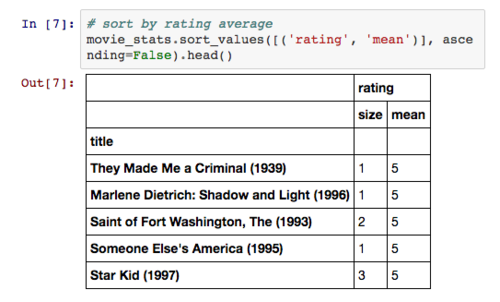
由于movie_stats是一个 DataFrame,因此我们可以利用sort方法来排序——Series 对象则使用order方法。此外,由于该数据集包含多层索引,所以我们需要传递一个元组数据来指定排序变量。
上表列出来的电影中评价数量都非常少,以致于我们无法从中得到一些有价值的信息。因此我们考虑对数据集进行筛选处理,只分析评价数量大于 100 的电影:
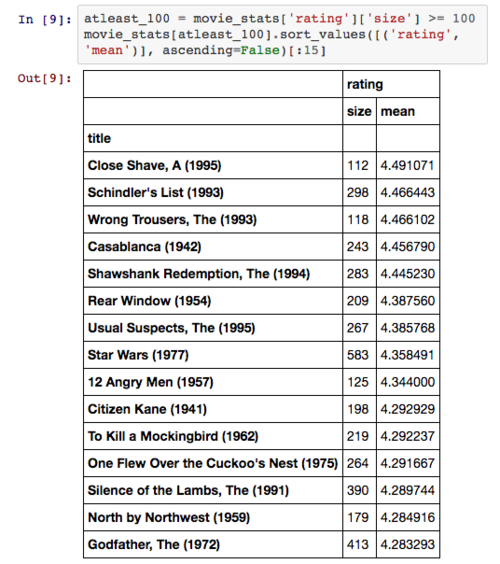
这个结果看起来比较靠谱,需要注意的是在这里我们利用布尔索引来筛选数据。
在SQL中,等价的代码为:
SELECT title, COUNT(1) size, AVG(rating) mean
FROM lens
GROUP BY title
HAVING COUNT(1) >= 100
ORDER BY 3 DESC
LIMIT 15;
筛选部分数据
为了便于进一步分析,我们从数据集中筛选出评价数最高的 50 部电影:
SQL 中的等价代码为:
CREATE TABLE most_50 AS(
SELECT movie_id, COUNT(1)
FROM lens
GROUP BY movie_id
ORDER BY 2 DESC
LIMIT 50
);
此外,我们也可以利用 EXISTS, IN 或者 JOIN 来过滤数据:
SELECT *
FROM lens
WHERE EXISTS (SELECT 1 FROM most_50 WHERE lens.movie_id = most_50.movie_id);
不同年龄段观众之间争议最大的电影
首先,我们来看下数据集中用户的年龄分布情况:
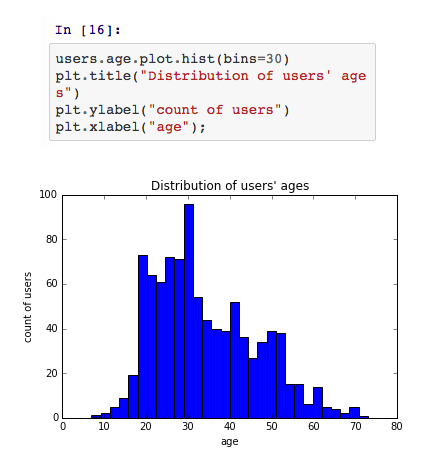
Pandas 整合了matplotlib的基础画图功能,我们只需要对列变量调用hist方法即可绘制直方图。当然了,我们也可以利用matplotlib.pyplot来自定义绘图。
对用户进行分箱处理
我认为直接对比不同年龄用户的行为无法得到有价值的信息,所以我们应该根据用户的年龄情况利用 pandas.cut 将所有用户进行分箱处理。

上述代码中,我们首先创建分组标签名,然后根据年龄变量将用户分成八组(0-9, 10-19, 20-29,...),其中参数right=False用于剔除掉区间上界数据,即30岁的用户对应的标签为 30-39。
现在我们可以比较不同年龄组之间的评分情况:
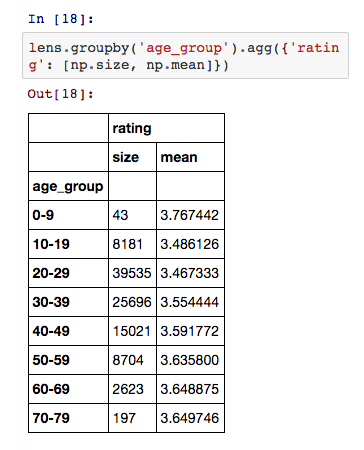
从上表中我们可以看出,年轻用户比其他年龄段的用户更加挑剔。接下来让我们看下这 50 部热评电影中不同年龄组用户的评价情况。
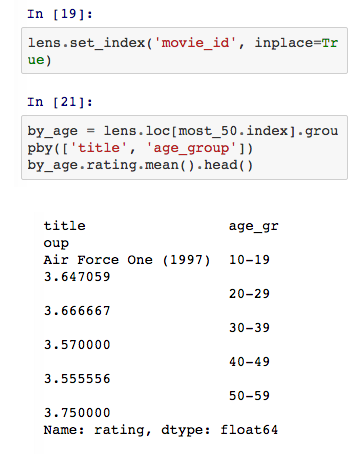
需要注意的是,此处的电影标题和年龄组都是索引值,平均评分为 Series 对象。如果你觉得这个展示结果不直观的话,我们可以利用unstack方法将其转换成表格形式。
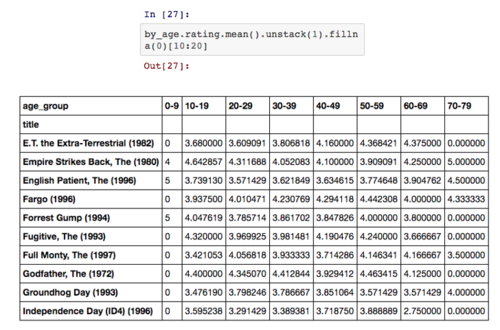
unstack方法主要用于拆分多层索引,此例中我们将移除第二层索引然后将其转换成列向量,并用 0 来填补缺失值。
男士与女士分歧最大的电影
首先思考下你会如何利用 SQL 来解决这个问题,你可能会利用判断语句和汇总函数来旋转你的数据集,你的查询语句大概会是这个样子:
SELECT title, AVG(IF(sex = 'F', rating, NULL)), AVG(IF(sex = 'M', rating, NULL))
FROM lens
GROUP BY title;
想象下,如果你必须处理多列数据的话,这样运算是多么的麻烦。DataFrame 提供了一个简便的方法——pivot_table。
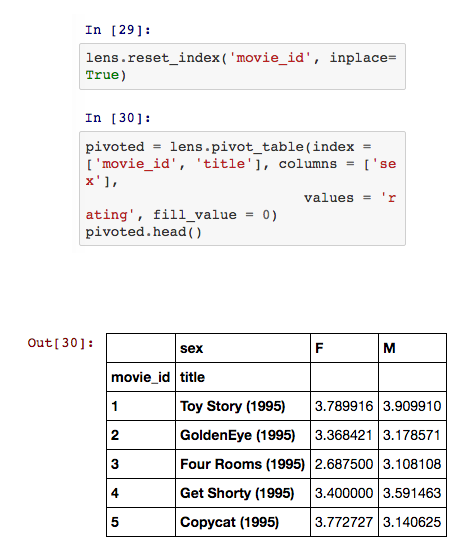
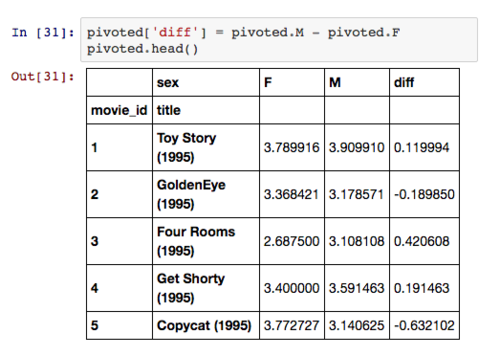

从上图中我们可以看出,男性喜欢《终结者》的程度远高于女性,女性用户则更喜欢《独立日》。这个结果可靠吗?

原文链接:http://www.gregreda.com/2013/10/26/using-pandas-on-the-movielens-dataset/
原文作者:Greg Reda
译者:Fibears
作者:Datartisan数据工匠
链接:https://www.jianshu.com/p/6088278507d5





