
准备阶段:GET和POST是什么?
GET
还记得上一节的Bonus吗?那里我们简单介绍了GET请求的作用:向网站获取资源,同时发送一定的数据(还记得王老五吗?)。如果在GET中向网站发送数据,数据会被记录在网址之中,通常都是以/?variable1=key1&variable2=key2&...的形式传输给服务器。我搭建了一个小网站来帮助大家理解GET请求,请点击这里访问。
你没有向服务器传输数据
这里显示了“你没有向服务器传输任何数据”,因为我们还没有在网址后面加?variable=key这样的字段,所以网站只返回了基础页面。你现在可以试试在网址后面输入?python=easy&learn=good然后访问。

返回了两组数据
这里网站就接受到了两组数据,第一组就是把变量名为python变量定义为easy,第二组就是把变量名learn变量定义为good。注意这里的python和learn变量都是在服务器中进行的处理。上次糗事百科的s也是服务器处理的变量。

s是服务器内部储存的变量
如果你更改了变量名,网站可能就没有办法正确处理你的请求,网站访问就可能出错。
基于GET请求的这些特性,我们也可以把这样的网址放在收藏夹里面。以后每次打开这个网站的时候都发送一样的信息(比如每次都给糗事百科说:我是王老五)
POST
有的时候我们要登录一个网站(比如知乎),或者填写了一个表格,要发送给网站。所以浏览器要对网站说:你好,这里是我的账号和密码,麻烦让我登陆一下可以吗?或者说,你给我的表格我都填好了,你查收一下吧。
对于这种登录、填表一类的数据,浏览器就会对网站发送POST请求,把表单信息(Form Data),也就是之前说的账号密码,问据调查一类的信息,发送到网站。
这一类的信息是不会储存在网址里面的,所以你也不用担心你的账号密码都明文发送到了服务器。
如何查看请求类型
我们打开开发者工具,点击Network选单,任意点击一个请求就可以看到它请求的类型。
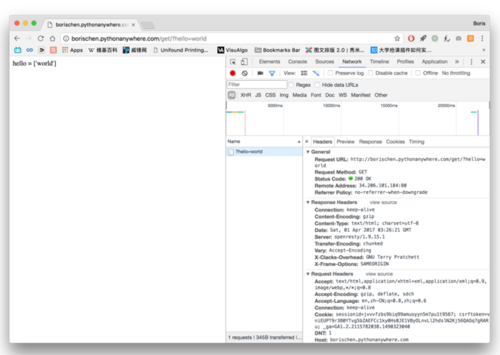
GET请求

POST请求
今天的目标
我们的目标是什么?当然是没有蛀牙。
呸!
事情是这样的,前几个月老师派我们去参加了泰迪杯的教练员培训,培训是全程录像的。老师希望我们能够把录像的视频发给他。

视频有这么多
大概看了一下,视频有这么多!一个一个下载,那不是虐待自己嘛!
那怎么办?要不用爬虫来下载吧。
模拟登陆
由于泰迪杯网站问题,测试之后发现无法用正常的账号密码登陆,这里会使用访客账号登陆,其他网站分析步骤和此一致。
我们先打开泰迪杯的登陆界面,打开开发者工具,选择Network选单,点击访客登陆。
注意到index.php的资源请求是一个POST请求,我们把视窗拉倒最下面,看到表单数据(Form data),浏览器在表单数据中发送了两个变量,分别是username和password,两个变量的值都是guest。这就是我们需要告诉网站的信息了。
知道了这些信息,我们就可以使用requesst来模拟登陆了。
import requests
s = requests.Session()
data = { 'username': 'guest', 'password': 'guest',
}
r = s.post('http://moodle.tipdm.com/login/index.php', data)
print(r.url)同样的,在第一行我们引入requests包。但与上次不同的是我们这次并没有直接使用request.post(),而是在第二行先创建了一个Session实例s,Session实例可以将浏览过程中的cookies保存下来。
我们先来简单认识一下cookies是什么:
cookies指网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)
来源:维基百科
换句话说,泰迪杯的网站要聪明一点,不是只是用GET请求传递的数据来确认用户身份,而是要用保存在本地的cookies来确认用户身份(你再也不能伪装成隔壁老王了)。
在python2.7大家通常使用urllib和urllib2包中,有一套很复杂的代码来储存cookies。但是在requests中,我们只要创建一个Session实例(比如这里的s),然后之后的请求都用Session实例s来发送,cookies的事情就不用管了。
我们再来看这几行代码:
data = { 'username': 'guest', 'password': 'guest',
}
r = s.post('http://moodle.tipdm.com/login/index.php', data)s.post()和上次教程中的requests.get()是相对应的,一个发送POST请求,一个发送GET请求。上一篇中我们并没有介绍Session实例,所以用的requests。在之后的请求发送中,大家尽量多使用s.get()和s.post(),这样可以避免很多错误。
POST请求在之前讲过了,是一定要向服务器发送一个表单数据(form data)的。那这个数据到底怎么发送,发送什么呢?答案就在开发者工具的Form Data里面。
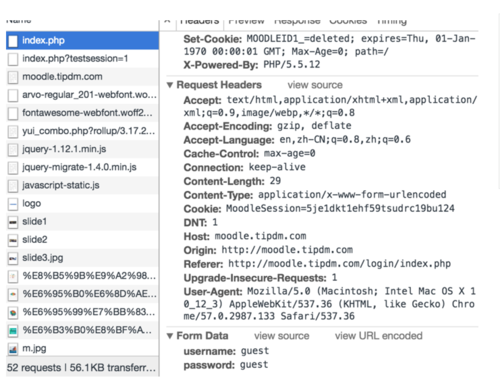
右下角有Form Data
我们看到泰迪杯网站要求上传的表单数据就是username和password,两者的值都是guest,所以在python里面我们创建一个dict,命名为data,里面的数据就输入username和password。最后再用s把数据post到网址,模拟登陆就完成了。
恭喜你,你已经学会了如何模拟登陆一个网站。你可以给你自己鼓鼓掌,然后我们开始进入下一个部分。
视频下载
我们进入到我们要下载的视频的页面,然后对要下载的链接进行审查元素。

元素都在`a`标签中
使用上篇教程中的分析方法我们不难发现,所有这样的a标签(a tag)都在<div class="activityinstance">标签中。所以我们只要找到所有的class为acticityinstance的div标签,然后提取里面a标签的href属性,就知道视频的地址了对吧?
同样的,我们使用beautiful soup包来实现我们想要的功能。
from bs4 import BeautifulSoup
r = s.get('http://moodle.tipdm.com/course/view.php?id=16')
soup = BeautifulSoup(r.text, 'lxml')
divs = soup.find_all("div", class_='activityinstance')for div in divs:
url = div.a.get('href')
print(url)注意,现在所有的代码看起来应该是这样的:
import requestsfrom bs4 import BeautifulSoup
data = { 'username': 'guest', 'password': 'guest',
}
s = requests.Session()
r = s.post('http://moodle.tipdm.com/login/index.php', data)
r = s.get('http://moodle.tipdm.com/course/view.php?id=16')
soup = BeautifulSoup(r.text, 'lxml')
divs = soup.find_all("div", class_='activityinstance')for div in divs:
url = div.a.get('href')
print(url)恭喜,你现在离成功只有一步之遥了!
我们点开其中的一个网址,看看里面的结构:

下载的链接就在眼前了
可以看到下载链接已经在你面前了,我们对它进行审查元素,看到了一个.mp4的下载地址,那下一步我们就是要获取这个mp4的下载地址。
我强烈建议你在这里暂停一下,先不要看下面的内容。试试自己写能不能写出来,写不出来再看看下面给出来的代码。
for div in divs[1:]: # 注意这里也出现了改动
url = div.a.get('href')
r = s.get(url)
soup = BeautifulSoup(r.text, 'lxml')
target_div = soup.find('div', class_='resourceworkaround')
target_url = target_div.a.get('href')
print(target_url)divs[1:]的意思是我们忽视掉divs列表(list)中的第一个元素,然后进行下面的操作。
这里请你思考一个问题——为什么我们要忽视divs中的第一个元素呢?
注意,到目前为止,你的代码看起来应该是这样的:
import requestsfrom bs4 import BeautifulSoup
data = { 'username': 'guest', 'password': 'guest',
}
s = requests.Session()
r = s.post('http://moodle.tipdm.com/login/index.php', data)
r = s.get('http://moodle.tipdm.com/course/view.php?id=16')
soup = BeautifulSoup(r.text, 'lxml')
divs = soup.find_all("div", class_='activityinstance')for div in divs[1:]: # 注意这里也出现了改动
url = div.a.get('href')
r = s.get(url)
soup = BeautifulSoup(r.text, 'lxml')
target_div = soup.find('div', class_='resourceworkaround')
target_url = target_div.a.get('href')
print(target_url)现在将我在这里提供的代码复制到你的代码前面:
def download(url, s):
import urllib, os
file_name = urllib.parse.unquote(url)
file_name = file_name[file_name.rfind('/') + 1:] try:
r = s.get(url, stream=True, timeout = 2)
chunk_size = 1000
timer = 0
length = int(r.headers['Content-Length'])
print('downloading {}'.format(file_name)) if os.path.isfile('./' + file_name):
print(' file already exist, skipped') return
with open('./' + file_name, 'wb') as f: for chunk in r.iter_content(chunk_size):
timer += chunk_size
percent = round(timer/length, 4) * 100
print('\r {:4f}'.format((percent)), end = '')
f.write(chunk)
print('\r finished ') except requests.exceptions.ReadTimeout:
print('read time out, this file failed to download') return
except requests.exceptions.ConnectionError:
print('ConnectionError, this file failed to download') return然后在你循环的末尾加上
download(target_url, s)
注意,现在整个代码看起来是这样的:
import requestsfrom bs4 import BeautifulSoup
data = { 'username': 'guest', 'password': 'guest',
}def download(url, s):
import urllib, os
file_name = urllib.parse.unquote(url)
file_name = file_name[file_name.rfind('/') + 1:] try:
r = s.get(url, stream=True, timeout = 2)
chunk_size = 1000
timer = 0
length = int(r.headers['Content-Length'])
print('downloading {}'.format(file_name)) if os.path.isfile('./' + file_name):
print(' file already exist, skipped') return
with open('./' + file_name, 'wb') as f: for chunk in r.iter_content(chunk_size):
timer += chunk_size
percent = round(timer/length, 4) * 100
print('\r {:4f}'.format((percent)), end = '')
f.write(chunk)
print('\r finished ') except requests.exceptions.ReadTimeout:
print('read time out, this file failed to download') return
except requests.exceptions.ConnectionError:
print('ConnectionError, this file failed to download') returns = requests.Session()
r = s.post('http://moodle.tipdm.com/login/index.php', data)
r = s.get('http://moodle.tipdm.com/course/view.php?id=16')
soup = BeautifulSoup(r.text, 'lxml')
divs = soup.find_all("div", class_='activityinstance')for div in divs[1:]:
url = div.a.get('href')
r = s.get(url)
soup = BeautifulSoup(r.text, 'lxml')
target_div = soup.find('div', class_='resourceworkaround')
target_url = target_div.a.get('href')
download(target_url, s)运行一下,

视频已经开始下载了

下载好的文件
恭喜你,你已经成功学会了如何模拟登陆一个网站,并且学会了如何从网站上面下载一个文件。
你的进展非常的迅速,并且做的也非常好。你可以四处走动走动,休息一下。
如果你的精力还非常充沛,你可以试着分析一下我给出的download函数是怎么构成的。
爬虫其实很简单,对吗?
Bonus
未完待续~
本篇教程代码文件业已上传Github,点击这里访问
作者:BorisChen
链接:https://www.jianshu.com/p/e3444c52c043




