
网页的结构越来越复杂,简直可以看做一个简单APP,如果还像以前那样把所有的代码都放到一个文件里面会有一些问题:
全局变量互相影响
JavaScript文件变大,影响加载速度
结构混乱、很难维护
和后端(比如Java)比较就可以看出明显的差距。2009年Ryan Dahl创建了node.js项目,将JavaScript用于服务器编程,这标志“JS模块化编程”正式诞生。
基本原理
模块就是一些功能的集合,那么可以将一个大文件分割成一些小文件,在各个文件中定义不同的功能,然后在HTML中引入:
var module1 = new Object({
_count : 0,
m1 : function (){ //...
},
m2 : function (){ //...
}
});这样做的坏处是:把模块中所有的成员都暴露了!我们知道函数的本地变量是没法从外面进行访问的,那么可以用立即执行函数来优化:
var module1 = (function(){ var _count = 0; var m1 = function(){ //...
}; var m2 = function(){ //...
}; return {
m1 : m1, m2 : m2
};
})();大家定义模块的方式可能五花八门,如果都能按照一定的规范来,那好处会非常大:可以互相引用!
模块规范
在node.js中定义math.js模块如下:
function add(a, b){ return a + b;
}
exports.add = add;在其他模块中使用的时候使用全局require函数加载即可:
var math = require('math');
math.add(2,3);在服务器上同步require是没有问题的,但是浏览器在网络环境就不能这么玩了,于是有了异步的AMD规范:
require(['math'], function (math) {// require([module], callback);
math.add(2, 3);
});模块的定义方式如下(模块可以依赖其他的模块):
define(function (){ // define([module], callback);
var add = function (x,y){ return x+y;
}; return { add: add };
});用RequireJS可以加载很多其他资源(看这里),很好很强大!在工作中用的比较多的是SeaJS,所使用的规范称为CMD,推崇(应该是指异步模式):
as lazy as possible!
对于依赖的模块的处理方式和AMD的区别在于:
AMD是提前执行(依赖前置),CMD是延迟执行(依赖就近)。
在CMD中定义模块的方式如下:
define(function(require, exports, module) { var a = require('./a');
a.doSomething(); var b = require('./b');
b.doSomething();
});使用方式直接看文档,这里就不赘述了!
SeaJS源码分析
刚接触模块化的时候感觉这个太简单了,不就是:
创建script标签的时候设置一下onload和src!
事实上是这样的,但也不完全是!下面来开始看SeaJS的代码(sea-debug.js)。一个模块在加载的过程中可能经历下面几种状态:
var STATUS = Module.STATUS = { // 1 - The `module.uri` is being fetched FETCHING: 1, // 2 - The meta data has been saved to cachedMods SAVED: 2, // 3 - The `module.dependencies` are being loaded LOADING: 3, // 4 - The module are ready to execute
LOADED: 4, // 5 - The module is being executed
EXECUTING: 5, // 6 - The `module.exports` is available EXECUTED: 6, // 7 - 404
ERROR: 7}内存中用Modul对象来维护模块的信息:
function Module(uri, deps) { this.uri = uri this.dependencies = deps || [] // 依赖模块ID列表
this.deps = {} // 依赖模块Module对象列表
this.status = 0 // 状态
this._entry = [] // 在模块加载完成之后需要调用callback的模块}在页面上启动模块系统需要使用seajs.use方法:
seajs.use(‘./main’, function(main) {// 依赖及回调方法
main.init();
});加载过程的整体逻辑可以在Module.prototype.load中看到:
Module.prototype.load = function() { var mod = this
if (mod.status >= STATUS.LOADING) { return
}
mod.status = STATUS.LOADING var uris = mod.resolve() // 解析依赖模块的URL地址
emit("load", uris) for (var i = 0, len = uris.length; i < len; i++) {
mod.deps[mod.dependencies[i]] = Module.get(uris[i])// 从缓存取或创建
}
mod.pass(); // 将entry传递给依赖的但还没加载的模块
if (mod._entry.length) {// 本模块加载完成
mod.onload() return
} var requestCache = {}; var m; // 加载依赖的模块
for (i = 0; i < len; i++) {
m = cachedMods[uris[i]] if (m.status < STATUS.FETCHING) {
m.fetch(requestCache)
} else if (m.status === STATUS.SAVED) {
m.load()
}
} for (var requestUri in requestCache) { if (requestCache.hasOwnProperty(requestUri)) {
requestCache[requestUri]()
}
}
}总体上逻辑很顺就不讲了,唯一比较绕的就是_entry数组了。网上没有找到比较通俗易懂的文章,于是看着代码连蒙带猜地大概看懂了,其实只要记住它的目标即可:
当依赖的所有模块加载完成后执行回调函数!
换种说法:
数组_entry中保存了当前模块加载完成之后、哪些模块的依赖可能加载完成的列表(依赖的反向关系)!
举个例子,模块A依赖于模块B、C、D,那么经过pass之后的状态如下:
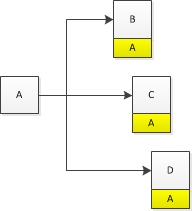
此时A中的remain为3,也就是说它还有三个依赖的模块没有加载完成!而如果模块B依赖模块E、F,那么在它load的时候会将A也传递出去:
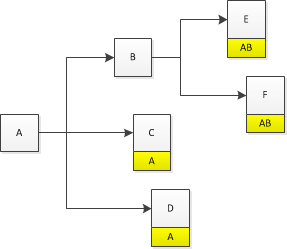
有几个细节:
已经加载完成的模块不会被传播;
已经传播过一次的模块不会再次传播;
如果依赖的模块正在加载那么会递归传播;
维护好依赖关系之后就可以通过Module.prototype.fetch来加载模块,有两种sendRequest的实现方式:
importScripts
script
然后根据结果执行load或者error方法。依赖的所有模块都加载完成后就会执行onload方法:
Module.prototype.onload = function() { var mod = this
mod.status = STATUS.LOADED for (var i = 0, len = (mod._entry || []).length; i < len; i++) { var entry = mod._entry[i] if (--entry.remain === 0) {
entry.callback()
}
} delete mod._entry
}其中--entry.remain就相当于告诉entry对应的模块:你的依赖列表里面已经有一个完成了!而entry.remain === 0则说明它所依赖的所有的模块都已经加载完成了!那么此时将执行回调函数:
for (var i = 0, len = uris.length; i < len; i++) { exports[i] = cachedMods[uris[i]].exec();
}if (callback) {
callback.apply(global, exports)// 执行回调函数}脚本下载完成之后会马上执行define方法来维护模块的信息:
没有显式地指定dependencies时会用parseDependencies来用正则匹配方法中的require()片段(指定依赖列表是个好习惯)。
接着执行factory方法来生成模块的数据:
var exports = isFunction(factory) ?
factory.call(mod.exports = {}, require, mod.exports, mod) :
factory然后执行你在seajs.use中定义的callback方法:
if (callback) {
callback.apply(global, exports)
}当你写的模块代码中require时,每次都会执行factory方法:
function require(id) { var m = mod.deps[id] || Module.get(require.resolve(id)) if (m.status == STATUS.ERROR) { throw new Error('module was broken: ' + m.uri)
} return m.exec()
}到这里核心的逻辑基本上讲完了,补一张状态的转换图:
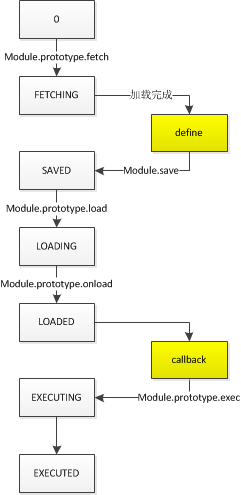
以后在用的时候就可以解释一些诡异的问题了!
总结
模块化非常好用,因此在ECMAScript 6中也开始支持,但是浏览器支持还是比较堪忧的~~





