
引言
本节开始学习Python爬虫,为什么直接开始学爬虫?因为实用性高啊,
练手项目多(那么多网站可以爬),后面还可以做数据分析等等,还有最终
要的,可以扒很多小姐姐到硬盘里啊。什么是爬虫?我的理解:
模拟用户使用浏览器请求网站,然后通过一些手段获取到想要的信息;
比如在一个小网站上看到了很多漂亮的小姐姐图片,你想把他们都存
到你的硬盘里,每天没事就拿出来把玩一下。
如果你不会爬虫,你只能重复地:
右键图片->图片另存为->选择文件夹->改下图片名->保存
呆得一匹,如果你学会了爬虫,你只需要花几分钟编写爬虫脚本:
然后执行下Py脚本,你可以去玩把跳一跳,回来就可以看到小姐姐
们都乖乖地趟在你的硬盘里了:
对的,就是那么酷炫,程序员就应该做些酷酷的事!
关于Python爬虫,主要由两个部分组成:
- 1.能够拿到正确的目标网站的网页源码
- 2.通过一些技术手段拿到想要的目标信息
依次说下这两个部分吧,先是拿到正确网页源码:
并不是所有的源码都是躺在那里等你直接扒的,很多网站都会有
反爬虫策略,比如:需要点击阅读全文才能加载所有内容;数据
使用Js动态生成(图片站点尤多);这还是不需要登录的情况,有些
站点需要登录后才能访问,模拟登录验证码可以卡死一堆人:
数字图片模糊验证,计算数字运算验证,滑动条验证,滑动图片验证,
滑动坏块完成拼图验证,geetest那种人机验证...
接着是通过技术手段拿到目标信息:
这个倒没什么,最多也就是Js动态生成网页,这个可以通过后面学
的selenium来规避,反正浏览器显示的是什么样,拿到的网页源码
就是怎么样。(还有一种恶心的:把文本数据写到图片上,让你抓到
图片也无可奈何,可以使用ORC的一些库进行文字识别,比如
tesseract-orc但是结果都是有些偏差的,还要自己另外处理...)
有正确的网页源码了,基本上都是找到我们想要的数据的,学习
一些HTML,XML的解析库就可以了,比如:BeautifulSoup,lxml等,
随便掌握一个就好了,笔者学习的是BeautifulSoup(甜汤)。
说下爬虫学习路线吧:
1.先把基础核心库urllib学习一波;
2.接着学习一波BeautifulSoup来解析网页数据;
3.学习正则表达式
4.使用Scrapy框架爬取数据
5.使用Selenium模拟浏览器
6.多线程抓取
等等...
关于爬虫的基础姿势就了解到这里,开始本节内容~
1.urllib模块详解
用于操作URL的模块(库,py3把urllib和urllib2合并到了一起)
爬网页必须掌握的最基础的东东。
1) 爬取网页
import urllib.request
import urllib.parse
import json
# 爬取网页信息
html_url = "http://www.baidu.com"
html_resp = urllib.request.urlopen(html_url)
# 读取全部,读取一行可用readline(),多行返回列表的可用readlines()
html = html_resp.read()
html = html.decode('utf-8') # 解码
print(html)
# 获得其他信息:
html_resp.info() # 获得头相关的信息,HTTPMessage对象
html_resp.getcode() # 获得状态码
html_resp.geturl() # 获取爬取的url
# url中包含汉字是不符合URL标准的,需要进行编码
urllib.request.quote('http://www.baidu.com')
# 编码后:http%3A//www.baidu.com
urllib.request.unquote('http%3A//www.baidu.com')
# 解码后:http://www.baidu.com2) 爬取二进制文件(图片,音频等)
# 下载图片
pic_url = "http://static.zybuluo.com/coder-pig/agr9d5uow8r5ug8iafnl6dlz/1.jpg"
pic_resp = urllib.request.urlopen(pic_url)
pic = pic_resp.read()
with open("LeiMu.jpg", "wb") as f:
f.write(pic)
# 也可以直接调用urlretrieve下载,比如下载音频
music_url = "http://7xl4pr.com2.z0.glb.qiniucdn.com/" \
"%E4%B8%83%E7%94%B0%E7%9C%9F%E4%B8%93%E5%8C%BA%2F%E4%" \
"B8%AD%E6%96%87%E8%AF%BE%2F%E6%83%B3%E8%" \
"B1%A1%E7%82%B9%E5%8D%A1%2F%2B6.mp3"
urllib.request.urlretrieve(music_url, "儿歌.mp3")3) 模拟Get请求与Post请求
PS:下面用到的json模块:用于将Python原始类型与json类型相互转换,使用
如果是读取文件可以用:dump()和load()方法,字符串的话用下述两个:
dumps()编码 [Python -> Json]
dict => object list, tuple => array str => string True => true
int, float, int- & float-derived Enums => number False => false None => null
loads()解码 [Json -> Python]
object => dict array => list string => str number (int) => int
number(real) => float true =>True false => False null => None
# 模拟Get
get_url = "http://gank.io/api/data/" + urllib.request.quote("福利") + "/1/1"
get_resp = urllib.request.urlopen(get_url)
get_result = json.loads(get_resp.read().decode('utf-8'))
# 这里后面的参数用于格式化Json输出格式
get_result_format = json.dumps(get_result, indent=2,
sort_keys=True, ensure_ascii=False)
print(get_result_format)
# 模拟Post
post_url = "http://xxx.xxx.login"
phone = "13555555555"
password = "111111"
values = {
'phone': phone,
'password': password
}
data = urllib.parse.urlencode(values).encode(encoding='utf-8')
req = urllib.request.Request(post_url, data)
resp = urllib.request.urlopen(req)
result = json.loads(resp.read()) # Byte结果转Json
print(json.dumps(result, sort_keys=True,
indent=2, ensure_ascii=False)) # 格式化输出Json4) 修改请求头
有些网站为了避免别人使用爬虫恶意采取信息会进行一些反爬虫的操作,
比如通过请求头里的User-Agent,检查访问来源是否为正常的访问途径,
我们可以修改请求头来进行模拟正常的访问。Request中有个headers参数,
有两种方法进行设置:
1.把请求头都塞到字典里,实例化Request对象的时候传入
2.通过Request对象的add_header()方法一个个添加
# 修改头信息
novel_url = "http://www.biqukan.com/1_1496/"
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/63.0.3239.84 Safari/537.36',
'Referer': 'http://www.baidu.com',
'Connection': 'keep-alive'}
novel_req = urllib.request.Request(novel_url, headers=headers)
novel_resp = urllib.request.urlopen(novel_req)
print(novel_resp.read().decode('gbk'))5) 设置连接超时
# urlopen函数时添加timeout参数,单位是秒
urllib.request.urlopen(novel_req, timeout=20)6) 延迟提交数据
一般服务器会对请求的IP进行记录,如果单位时间里访问的次数达到一个阀值,
会认为该IP地址是爬虫,会弹出验证码验证或者直接对IP进行封禁。一个最简单
的方法就是延迟每次提交的时间,直接用time模块的sleep(秒) 函数休眠下。
7) 代理
对应限制ip访问速度的情况我们可以使用延迟提交数据的做法,
但是有些是限制访问次数的,同一个ip只能在一段时间里访问
多少次这样,而且休眠这种方法效率也是挺低的。更好的方案是
使用代理,通过代理ip轮换去访问目标网址。 用法示例如下:
# 使用ip代理
ip_query_url = "http://www.whatismyip.com.tw"
# 1.创建代理处理器,ProxyHandler参数是一个字典{类型:代理ip:端口}
proxy_support = urllib.request.ProxyHandler({'http': '221.214.110.130:8080'})
# 2.定制,创建一个opener
opener = urllib.request.build_opener(proxy_support)
# 3.安装opener
urllib.request.install_opener(opener)
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (X11; Linux x86_64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/63.0.3239.84 Safari/537.36',
'Host': 'www.whatismyip.com.tw'
}
MAX_NUM = 10 # 有时网络堵塞,会报URLError错误,所以加一个循环
request = urllib.request.Request(ip_query_url, headers=headers)
for i in range(MAX_NUM):
try:
response = urllib.request.urlopen(request, timeout=20)
html = response.read()
print(html.decode('utf-8'))
break
except:
if i < MAX_NUM - 1:
continue
else:
print("urllib.error.URLError: <urlopen error timed out>")输出结果:

如图代理成功,这里的网站是用于查询请求ip的,另外,我们一般会弄一个
代理ip的列表,然后每次随机的从里面取出一个来使用。
8) Cookie
Cookie定义:指某些网站为了辨别用户身份、进行 session
跟踪而储存在用户本地终端上的数据(通常经过加密)
比如有些页面你在登录前是无法访问的,你登录成功会给你分配
Cookie,然后你带着Cookie去请求页面才能正常访问。
使用http.cookiejar这个模块可以帮我们获取Cookie,实现模拟登录。
该模块的主要对象(父类->子类):
CookieJar –> FileCookieJar –>MozillaCookieJar与LWPCookieJar
因为暂时没找到合适例子,就只记下关键代码,后续有再改下例子:
# ============ 获得Cookie ============
# 1.实例化CookieJar对象
cookie = cookiejar.CookieJar()
# 2.创建Cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 3.通过CookieHandler创建opener
opener = urllib.request.build_opener(handler)
# 4.打开网页
resp = opener.open("http://www.zhbit.com")
for i in cookie:
print("Name = %s" % i.name)
print("Name = %s" % i.value)
# ============ 保存Cookie到文件 ============
# 1.用于保存cookie的文件
cookie_file = "cookie.txt"
# 2.创建MozillaCookieJar对象保存Cookie
cookie = cookiejar.MozillaCookieJar(cookie_file)
# 3.创建Cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 4.通过CookieHandler创建opener
opener = urllib.request.build_opener(handler)
# 5.打开网页
resp = opener.open("http://www.baidu.com")
# 6.保存Cookie到文件中,参数依次是:
# ignore_discard:即使cookies将被丢弃也将它保存下来
# ignore_expires:如果在该文件中cookies已存在,覆盖原文件写入
cookie.save(ignore_discard=True, ignore_expires=True)
# ============ 读取Cookie文件 ============
cookie_file = "cookie.txt"
# 1.创建MozillaCookieJar对象保存Cookie
cookie = cookiejar.MozillaCookieJar(cookie_file)
# 2.从文件中读取cookie内容
cookie.load(cookie_file, ignore_expires=True, ignore_discard=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
resp = opener.open("http://www.baidu.com")
print(resp.read().decode('utf-8'))
9) URL编解码
对于url有时我们需要进行编解码,比如带有中文的url,可以调用:
urllib.request.quote(xxx) # 编码
urllib.request.unquote(xxx) # 解码2.Beautiful Soup 库详解
1) 官方介绍:
一个可以从 HTML 或 XML 文件中提取数据的 Python库,它能够通过
你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式。
Beautiful Soup 会帮你节省数小时甚至数天的工作时间。
简单点说就是 爬取HTML和XML的利器
2) 安装库
PyCharm直接安装:
File -> Default Settings -> Project Interpreter 选择Python 3的版本
-> 点+号 -> 搜索beautifulsoup4 安装即可
pip方法安装的自己行百度,或者看上一节的内容~
3) 实例化BeautifulSoup对象
简单点说这一步就是把html丢到BeautifulSoup对象里,可以是请求后的网站,
也可以是本地的HTML文件,第二个参数是指定解析器,html.parser是内置的
html解析器,你还可以用lxml.parser,不过要另外导库。
网站:soup = BeautifulSoup(resp.read(), 'html.parser')
本地:soup = BeautifulSoup(open('index.html'),'html.parser')
另外还可以调用soup.prettify()格式化输出HTML
4) 四大对象
一.Tag(标签)
查找的是:在所有内容中第一个符合要求的标签,最常用的两个东东:
tag.name:获得tag的名字,比如body
tag.attrs:获取标签内所有属性,返回一个字典,可以根据键取值,也可以
直接调用get('xxx')拿到属性。
还有个玩法是:可以soup.body.div.div.a 这样玩,同过加标签名的形式
轻松获取标签的内容,不过查找的只是第一个!基本没什么卵用...
二.NavigableString(内部文字)
获取标签内部的文字,直接调用.string
三.BeautifulSoup(文档的全部内容)
当做一个Tag对象就好,只是可以分别获取它的类型,名称,一级属性而已
四.Comment(特殊的NavigableString)
这种对象调用.string来输出内容会把注释符号去掉,直接把注释里的内容
打出来,需要加一波判断:
if type(soup.a.string)==bs4.element.Comment:
print soup.a.string 5) 各种节点
PS:就是找到了目标节点附近的节点,然后顺藤摸瓜找到目标节点。
子节点与子孙节点:
contents:把标签下的所有子标签存入到列表,返回列表
children:和contents一样,但是返回的不是一个列表而是
一个迭代器,只能通过循环的方式获取信息,类型是:list_iterator
前两者仅包含tag的直接子节点,如果是想扒出子孙节点,可以使用descendants
会把所有节点都剥离出来,生成一个生成器对象<class 'generator'>
父节点与祖先节点
parent:返回父节点Tag
parents:返回祖先节点,返回一个生成器对象
兄弟结点:
处于同一层级的结点,next_sibling下一个,previous_sibling
上一个,结点不存在返回None
所有兄弟节点:next_siblings,previous_sibling,返回一个生成器对象
前后结点:next_element,previous_element
所有前后结点:next_elements,previous_elements 返回一个生成器对象
6) 文档树搜索
最常用的方法:
-
find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None, kwargs):**-
name参数:通过html标签名直接搜索,会自动忽略字符串对象,
参数可以是:字符串,正则表达式,列表,True或者自定义方法 -
keyword参数:通过html标签的id,href(a标签)和title,class要写成class_,
可以同时过滤多个,对于不能用的tags属性,可以直接用一个attrs字典包着,
比如:find_all(attrs={'data-foo': 'value'} -
text:搜索文档中的字符串内容
-
limit:限制返回的结果数量
- recursive:是否递归检索所有子孙节点
-
其他方法:
find(self, name=None, attrs={}, recursive=True, text=None, kwargs):**
和find_all作用一样,只是返回的不是列表,而是直接返回结果。find_parents()和find_parent():
find_all() 和 find() 只搜索当前节点的所有子节点,孙子节点等.
find_parents() 和 find_parent()用来搜索当前节点的父辈节点,
搜索方法与普通tag的搜索方法相同,搜索文档搜索文档包含的内容。find_next_sibling()和find_next_siblings():
这2个方法通过 .next_siblings 属性对当 tag 的所有后面解析的兄弟
tag 节点进行迭代, find_next_siblings() 方法返回所有符合条件的后面
的兄弟节点,find_next_sibling() 只返回符合条件的后面的第一个tag节点。find_previous_siblings()和find_previous_sibling():
这2个方法通过 .previous_siblings 属性对当前 tag 的前面解析的兄弟
tag 节点进行迭代, find_previous_siblings()方法返回所有符合条件的前面的
兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点。find_all_next()和find_next():
这2个方法通过 .next_elements 属性对当前 tag 的之后的 tag 和字符串进行
迭代, find_all_next() 方法返回所有符合条件的节点, find_next() 方法返回
第一个符合条件的节点。find_all_previous()和find_previous()
这2个方法通过 .previous_elements 属性对当前节点前面的 tag 和字符串
进行迭代, find_all_previous() 方法返回所有符合条件的节点,
find_previous()方法返回第一个符合条件的节点
3.爬虫实战
1) 小说网站数据抓取下载txt到本地
上一节学习了基础知识,这节又学了简单的爬虫姿势:urllib和Beautiful Soup库,
肯定是要来个实战练练手的,选了个最简单的而且有点卵用的小东西玩玩。
相信各位大佬平时都有看网络小说的习惯吧,应该很少有老司机去会起点
付费看,一般都有些盗版小说网站,比如:笔趣看:http://www.biqukan.com/
手机在线看,广告是可怕的,想想你在挤满人的地跌上,突然蹦出一对
柰子,你的第一反应肯定是关掉,然而还是naive,点X直接弹一个新的
网页什么壮阳延时...尴尬得一匹。学了Python爬虫的东西了,写个小爬虫
爬爬小说顺道练练手岂不美滋滋。不说那么多,开搞:
我最近在看的小说:唐家三少的《斗罗大陆3-龙王传说》
http://www.biqukan.com/1_1496/
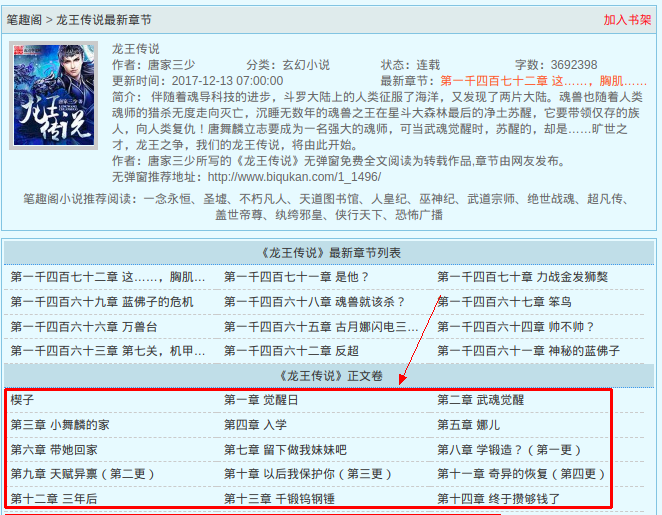
图中圈住的部分就是小说的章节,F12打开chrome的开发者工具,切到Network选项卡
(或者直接看Elements也行),选Response,刷新一波可以看到这样的HTML结构:

当然我们要找的内容不在这里,继续往下翻:

listmain这个全局搜了下,是唯一的(好吧,找这个真的太没难度了...)
直接find_all(attrs={'class': 'listmain'}) 就可以拿到这段东西了
find_all返回一个bs4.element.ResultSet 对象,for循环遍历一波
这个对象,(迭代对象的类型是:bs4.element.Tag)打印一波可以看到:
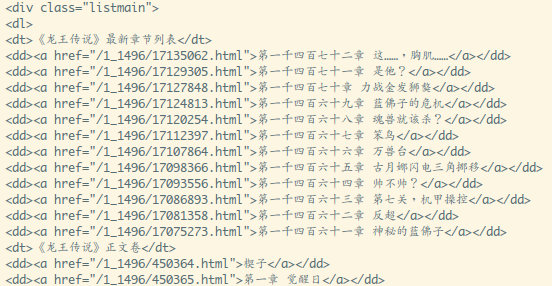
我们要留下的只是<a>xxx</a>这种东西,可以在循环的时候顺带把
无关的筛选掉:
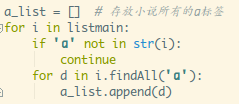
可以打印下这个a_list,剩下的全是<a>xxx</a>

因为最新章节列表那里默认有12个,我们应该从楔子那里开始,
所以把把a_list列表分下片:result_list = a_list[12:]
过滤掉前面的最新章节部分~
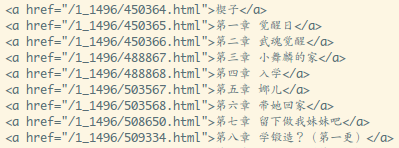
章节部分的数据就处理完毕了,有章节内容的url,以及章节的名称,
接着我们来看看章节页面的内容结构,随便打开一个:
比如:http://www.biqukan.com/1_1496/450364.html

就不说了,class="showtxt"又是唯一的,直接:
showtxt = chapter_soup.find_all(attrs={'class': 'showtxt'})
把showtxt循环打印一波,里面的东西就是我们想要的东东了~

url有了,章节名有了,内容有了,是时候写入到文件里了,这个
过于简单就不用多说了,strip=True代表删除字符前后的所有空格:

到此我们爬区小说的小爬虫就写完了,不过有个小问题是,批量
快速访问的时候,会报503异常,因为服务器一般会对限制ip在
一段时间里访问的频次,上面也讲了要么休眠,要么搞ip代理,
肯定是搞ip代理嗨一些,接着我们来写一个爬虫来抓取西刺
代理的ip,并校验是否可用,然后存到本地,我们的代理ip池,
哈哈~

附上小说抓取这部分的代码:
from bs4 import BeautifulSoup
import urllib.request
from urllib import error
novel_url = "http://www.biqukan.com/1_1496/" # 小说页面地址
base_url = "http://www.biqukan.com" # 根地址,用于拼接
save_dir = "Novel/" # 下载小说的存放路径
# 保存小说到本地
def save_chapter(txt, path):
try:
with open(path, "a+") as f:
f.write(txt.get_text(strip=True))
except (error.HTTPError, OSError) as reason:
print(str(reason))
else:
print("下载完成:" + path)
# 获得所有章节的url
def get_chapter_url():
chapter_req = urllib.request.Request(novel_url)
chapter_resp = urllib.request.urlopen(chapter_req, timeout=20)
chapter_content = chapter_resp.read()
chapter_soup = BeautifulSoup(chapter_content, 'html.parser')
# 取出章节部分
listmain = chapter_soup.find_all(attrs={'class': 'listmain'})
a_list = [] # 存放小说所有的a标签
# 过滤掉不是a标签的数据
for i in listmain:
if 'a' not in str(i):
continue
for d in i.findAll('a'):
a_list.append(d)
# 过滤掉前面"最新章节列表"部分
result_list = a_list[12:]
return result_list
# 获取章节内容并下载
def get_chapter_content(c):
chapter_url = base_url + c.attrs.get('href') # 获取url
chapter_name = c.string # 获取章节名称
chapter_req = urllib.request.Request(chapter_url)
chapter_resp = urllib.request.urlopen(chapter_req, timeout=20)
chapter_content = chapter_resp.read()
chapter_soup = BeautifulSoup(chapter_content, 'html.parser')
# 查找章节部分内容
showtxt = chapter_soup.find_all(attrs={'class': 'showtxt'})
for txt in showtxt:
save_chapter(txt, save_dir + chapter_name + ".txt")
if __name__ == '__main__':
novel_list = get_chapter_url()
for chapter in novel_list:
get_chapter_content(chapter)
2) 抓取西刺代理ip并校验是否可用
之前就说过了,很多服务器都会限制ip访问的频度或者次数,可以通过设置代理
ip的方式来解决这个问题,代理ip百度一搜一堆,最出名的应该是西刺代理了:
http://www.xicidaili.com/
爬虫中代理ip使用得非常频繁,每次都打开这个页面粘贴复制,感觉
过于低端,而且还有个问题,代理ip是会过期失效的,而且不一定
一直可以用:要不来个这样的骚操作:
写个爬虫爬取代理ip列表,然后校验是否可用,把可用的存在本地,
下次需要代理的时候,读取这个文件中的ip,放到一个列表中,然后
轮流切换ip或者通过random模块随机取出一个,去访问目标地址。
抓取的网页是:http://www.xicidaili.com/nn/1
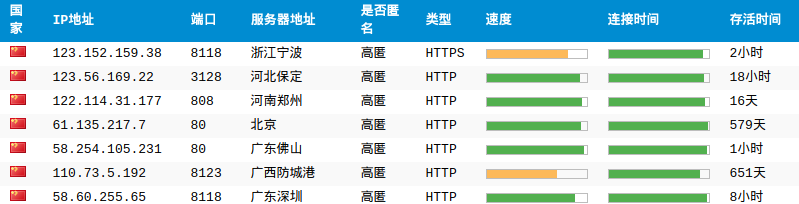
Network选项卡,Response看下页面结构,这里我喜欢在PyCharm上
新建一个HTML文件,结点可折叠,找关键位置代码很方便:
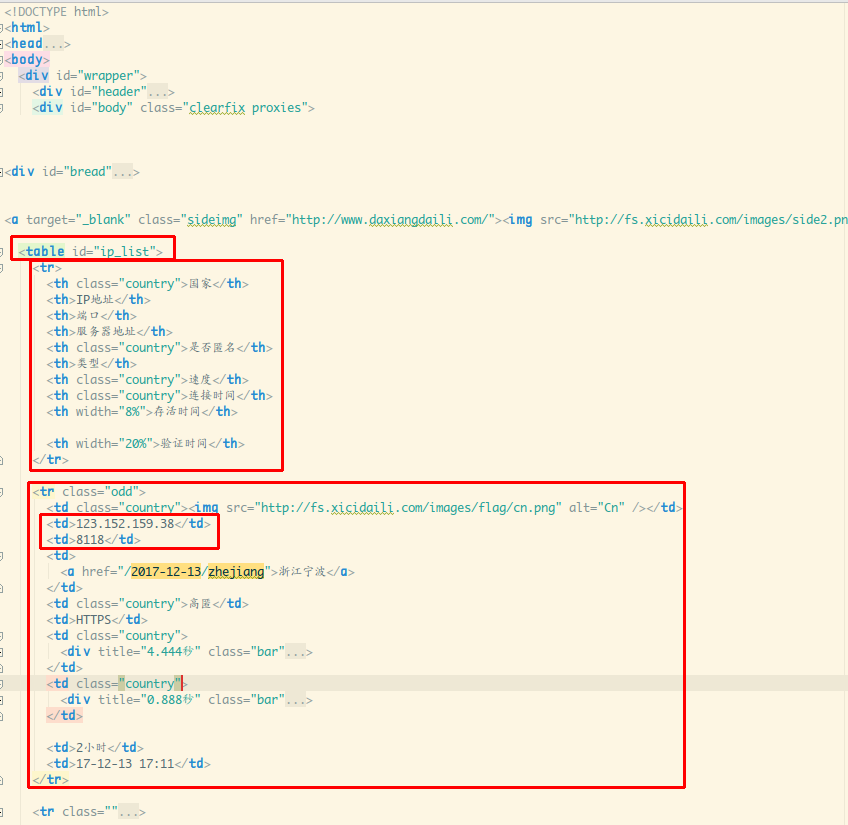
如图,不难发现就是我们要找的内容,可以从 find_all(attrs={'id': 'ip_list'})
这里入手,或者find_all('tr'),这里有个小细节的地方首项是类似于表头
的东西,我们可以通过列表分片去掉第一个:find_all('tr')[1:]
此时的列表:
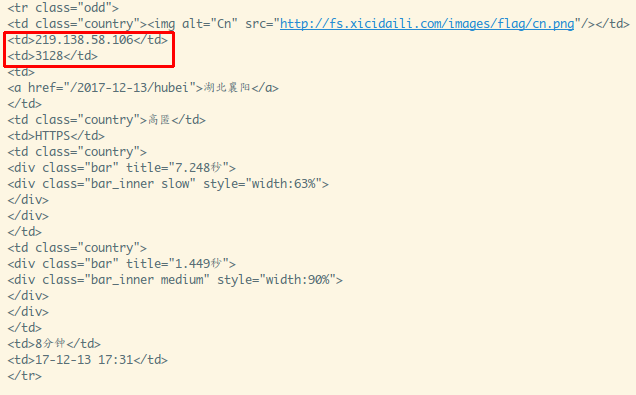
接着就是要拿出ip和端口了,遍历,先拿td,然后根据游标拿数据:

数据都拼接成"ip:端口号"的形式了,然后就是验证这个列表里的代理
是否都可以用了,验证方法也很简单,直接设置代理然后访问百度,
淘宝之类的网站,看返回码是否为200,是的话就代表代理可用,追加
到可用列表中,最后再把可用列表写入到文件中:

然后你就有自己的代理ip池了,要用的时候读取下文件就好,没事更新一波文件~
有了代理ip池,和上面扒小说的程序可用结合一波,应该就不会出现503的问题了,
具体有兴趣的自行去完善吧(我懒...)
附上完整代码:
from bs4 import BeautifulSoup
import urllib.request
from urllib import error
test_url = "https://www.baidu.com/" # 测试ip是否可用
proxy_url = "http://www.xicidaili.com/nn/1" # ip抓取源
ip_file = "availableIP.txt"
# 把ip写入到文件中
def write_file(available_list):
try:
with open(ip_file, "w+") as f:
for available_ip in available_list:
f.write(available_ip + "\n")
except OSError as reason:
print(str(reason))
# 检测代理ip是否可用,返回可用代理ip列表
def test_ip(test_list):
available_ip_list = []
for test in test_list:
proxy = {'http': test}
try:
handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(handler)
urllib.request.install_opener(opener)
test_resp = urllib.request.urlopen(test_url)
if test_resp.getcode() == 200:
available_ip_list.append(test)
except error.HTTPError as reason:
print(str(reason))
return available_ip_list
# 抓取西刺代理ip
def catch_ip():
ip_list = []
try:
# 要设置请求头,不然503
headers = {
'Host': 'www.xicidaili.com',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
req = urllib.request.Request(proxy_url, headers=headers)
resp = urllib.request.urlopen(req, timeout=20)
content = resp.read()
soup = BeautifulSoup(content, 'html.parser')
catch_list = soup.find_all('tr')[1:]
# 保存代理ip
for i in catch_list:
td = i.find_all('td')
ip_list.append(td[1].get_text() + ":" + td[2].get_text())
return ip_list
except urllib.error.URLError as reason:
print(str(reason))
if __name__ == "__main__":
xici_ip_list = catch_ip()
available_ip_list = test_ip(xici_ip_list)
write_file(available_ip_list)
结语:
本节学习了urllib库与Beautiful Soup,并通过两个非常简单的程序体验了
一波爬虫的编写,顺道温习了下上节的基础知识,美滋滋,比起Android
天天写界面,有趣太多,本节的东西还是小儿科,下节我们来啃硬骨头
正则表达式!敬请期待~

本节参考文献:






热门评论
-

chillco2019-01-30 0
查看全部评论这一条全是乱码啊哥想看