
最近需要实现获取个人京东订单信息的功能,利用了requests+beautifulsoup来实现。
requests是python的第三方库,相比之前常用的python标准库中的urllib2,requests简直不要好用太多,具体实现思路是,首先使用firefox+firebug找到京东登陆所需要的信息,利用requests的get获取需要模拟登陆的信息,post之后获取cookie,然后带着cookie访问相应订单的网页就可以得到订单信息了。
打开京东登陆的网页,使用账户登陆京东,在firebug上查看传递的参数
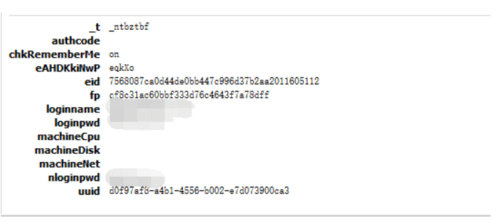
loginname是登陆的用户名,loginpwd和nloginpwd都是登陆的密码。以machine开头的三个参数传递参数为空,authcode是验证码,如果京东检测到你登陆状态有异常就会提示输入验证码。
经过测试,我们需要获取的参数有uuid、-t、和eAHDKkiNwP三个参数
回到京东登陆界面寻找这三个参数,在登陆界面的源代码中可以看到有个id名称为formlogin的form标签

正好全部包含了登陆需要传递的参数,利用Beautifulsoup将对于name的value提取出来,放在构造post信息的字典中,将构造好的字典通过requests的post方法获取到登陆的cookie。这样,得到订单信息我们已经完成了一大半了。
下面是具体实现的部分源码
import requestsfrom bs4 import BeautifulSoup
header= {'Host':'order.jd.com','Upgrade-Insecure-Requests':'1','Connection':'keep-alive','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2700.0 Safari/537.36','Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Encoding':'gzip, deflate, sdch','Accept-Language':'zh-CN,zh;q=0.8','Cache-Control':'max-age=0'}导入相应的包之后,需要构造header,网站服务器通过host来确定访问的网页,User-Agent是用户使用浏览器版本,系统的标签。许多网站会检查header中的host和User-Agent信息是否正确合理,不会处理未带正确header的请求,header可以在firebug上查看,这里我直接粘贴firebug上的,如果是大型的爬虫可以构造一个header池,每隔一段时间变更header中的User-Agent,简单的爬虫就不需要做的这么麻烦啦。
sessions = requests.session()
login_page=sessions.get('https://passport.jd.com/new/login.aspx',headers = header)
login_soup = BeautifulSoup(login_page.text,'lxml')
login_postinfo = login_soup.find_all('form',attrs = {'id' : 'formlogin'})[0].find_all('input')先构造一个sessions来帮助我们处理获取到的cookie,session可以自动处理cookie字符。
获取到登陆界面的text之后,先转换为beautiful可以处理的格式,login_postinfo为上文提到的formlogin下的所有input标签信息
uuid = login_soup.find_all('input',attrs = {'id' : 'uuid'})[0]['value']
_t = login_soup.find_all('input',attrs = {'name' : '_t'})[0]['value']利用beautifulsoup获取到uuid和_t
for input_info in login_postinfo: if len(input_info['value']) == 5: str1 = input_info['name'] str2 = input_info['value']
在提取最后一个关键key时和之前的不一样,它的key名是input标签中的name,value是标签中的value,所以我们无法按照name或id来提取,它们是一直在变化的,但是可以观察到一个规律,value值都是5个英文字母组成的,而input标签其他的value要不为空,要不有下划线或是一串很长的字符串,所以可以根据value的字符长度来定位到我们所需要的input
post_info = {
'uuid':uuid,
'loginname':'XXXXX',
'loginpwd':'XXXX',
'machineCpu':'',
'machineDisk':'',
'machineNet':'',
'nloginpwd':'XXXX',
str1:str2,
'_t':_t,
'authcode':''}
content = sessions.post('http://passport.jd.com/uc/loginService',data=post_info,headers = header)构造post信息的字典,通过sessions发送带着post字典的请求,可以得到success的信息

Paste_Image.png
然后我们就可以访问相应的界面获取想要的信息了
作者:芝士改变力量
链接:https://www.jianshu.com/p/368286617b13




