
这次文章是记录一下数据恢复。
上周五在调试Spark数据的时候发现了一个问题,就是一直显示No lease的问题,我们的实时处理程序升级之后,处理的数据量在一个小时内暴增1T。我们的小时程序Spark,有的单个key数据重复导致value值增大,程序运行卡住,根据网上查的参数进行调整。
Hadoop
在调整前,将Hadoop进行关闭 .
stop-all.sh 进行关闭
我们在第一步进行关闭的时候这里就出现问题。。。关闭hadoop.sh 出现异常,关闭失败。只好使用linux 上的kill 强制杀死所有的关于hadoop有关的进程。
重新启动出现错误,一直启动不起来。这个错误应该是同步数据 的问题。hadoop 在线上没有停止的时候就出现错误了
解决上面的问题 ,查阅资料 。。重点,
*网上给的方案是./hadoop namenode format*,我当时都没细看。。原谅我这个渣渣。执行之后我的一个主节点的namenode 里面存储的数据删除了。好吧当时心凉了。给运维打电话联系,说恢复不了。在这里心更凉。
5.最终没有棒法开始从网上找方案恢复。网上说到 namenode数据是可以恢复的。因为是集群 有两个namenode,可以做同步进行操作。
现在开始说下怎么弄,当然这个方案会丢失一部分数据,这也是没有办法的事情。幸好丢失的数据还可以通过原先的数据跑回来。万幸。
数据恢复。
在Hadoop中,我们可以看到有三个关注的地方
数据存储目录下的VERSION ,里面的namespaceID,clusterID与其他两个VERVION保持一致,有多少个数据目录都要统一一致,集群上的其他节点上在修复的时候也要与其一致,这样才能在集群关联的时候关联起来。关联上之后节点会在图示上 展示。关联不上的,可以去datanode节点日志查看原因,一般是namespaceID没有一致导致关联不上。修改数据目录下的VERSION下的namespaceID 保持一致即可。
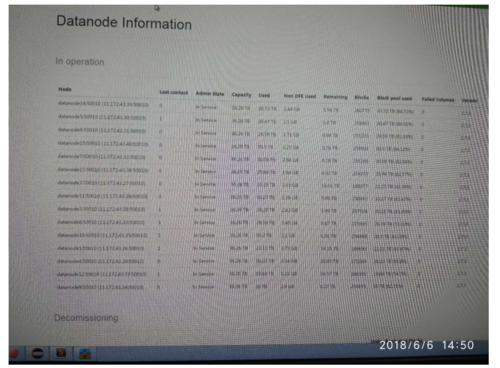
节点关联
Hadoop中的journalnode下的VERSION 里面的namespaceID ,clusterID 与其他的保持一致
主磁盘下的name目录下有一个VERSION 里面也有版本号要保持一致跟上面两个操作一致。
三步操作,把集群中这三个 namespaceID还有ClusterID 保持一致,这个一致时建立在namenode节点上的,并且 是有数据的namenode,否则设置错误会导致数据全部丢失。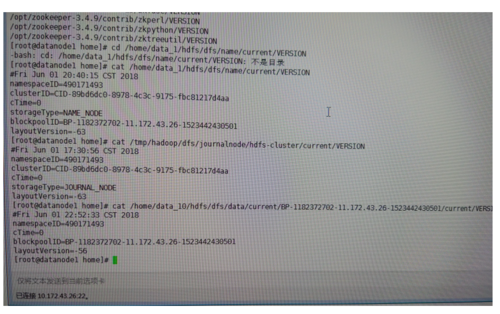
三个修改的文件
上面三个都修改完之后 ,开始进行数据的操作,我们知道在集群出问题之后可能出现两个namenode里面保存的不一致的情况,那么我们需要把这部分数据进行一致操作。
在数据盘里面的name版本文件里面 存在edit 信息,这个是保存的数据节点目录,上面修改完毕后,直接启动hadoop会出现
org.apache.hadoop.hdfs.server.namenode.NameNode: Exception in namenode join java.io.IOException: There appears to be a gap in the edit log. We expected txid 1, but got txid 52. at org.apache.hadoop.hdfs.server.namenode.MetaRecoveryContext.editLogLoaderPrompt(MetaRecoveryContext.java:94) at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadEditRecords(FSEditLogLoader.java:184) at org.apache.hadoop.hdfs.server.namenode.FSEditLogLoader.loadFSEdits(FSEditLogLoader.java:112) at org.apache.hadoop.hdfs.server.namenode.FSImage.loadEdits(FSImage.java:733) at org.apache.hadoop.hdfs.server.namenode.FSImage.loadFSImage(FSImage.java:647) at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:264) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:787) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:568) at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:443) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:491) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:684) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:669) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1254) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1320)
这样的错误,我们根据不需要的edit 其实就是损坏的数据删掉即可就能恢复系统了
总结
从上面步骤就可以把误操作的format 数据恢复过来,但是前提是两个namenode 其中一个没有被格式化。还保存着最新的数据留存。如果两个都被格式化了。。。基本无解了
作者:super糖
链接:https://www.jianshu.com/p/81a8ca2c6e08





