
正文
大数据下,要解决的两大问题:数据量大,一台机器存不下?怎么办?把数据分开存,存到多台机器里,分布式存储。这么多数据,计算速度慢?怎么办?没事,一台机器计算慢,那就多台机器协同起来算。这就是分布式计算。
Hadoop是什么?
Hadoop是一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop的核心是分布式文件系统(Hadoop Distrubuted File System ,HDFS)和MapReduce。HDFS就是我前面说的分布式存储,MapReduce是分布式计算的一个模型。
HDFS是什么?
HDFS是分布式文件系统,能对数据进行分布式存储。一个大的文件,会被分成一个一个数据块,数据块大小是默认的。而且一个数据块一般会复制成3份,存到不同的机器上,每个数据块都是如此,由此数据就分布到各个机器上。实现了 文件的分布式存储。一个数据块的复制为多份,也称冗余存储,用来解决数据传输出错的问题。
MapReduce是什么?
由前面的介绍,MapReduce起到了分布式计算的作用。它是怎么运作的?可能这是我们关心的,而且下面我们要用它来搞事情啊。所以这里详细的讲讲MapReduce的运行
MapReduce分为map和reduce,一个map处理一个数据块,所以每个机器上会有多个map,用来处理存储在这个机器上的多个数据块,处理的结果形成(key,value)键值对的形式。map处理后的结果由reduce汇总,最后将最终结果进行输出。可能有点抽象,举个简单的例子,计算文本中单词出现的个数(wordcount)

MapReduce的工作模式
首先最左边是一个文件,分成3个数据块(当然这个文件就几个字,太小了,我这里只是做一下演示说明),每个map对应一个数据块,对它进行处理,这里就将每个单词出现次数先置为1。处理之后,就是shuffle(洗牌),sort(排序)。所谓的洗牌就是将key值(这里是单词)相同的放到一起,排序就是按照key进行排序,如四个键值就是按照(h,i,l,y)顺序排好的。可以看到从上到下,him排在前面,you在最后面……reduce就是将key值出现的次数进行汇总,把value值进行相加。这个结果就是这个单词的次数。最后再将总的结果进行输出到文件中。
这就是整个MapReduce的工作模式,讲的还详细不?
下面就动手编程来实现下。
Wordcount程序详解:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
/**
* map函数的输入键、输入值、输出键和输出值 Hadoop本身提供了一套可优化网络序列化传输的基本类型,而不直接使用Java内嵌的类型。这些类型都在org.apache.hadoop.io包中
* Text(相当于java的string类型) IntWritable(相当于java中的Integer)
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) //content用于输出内容的写入
//map()方法的输入是一个键和一个值。我们首先将包含一行输入的Text值转换成java中的string类型
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
//这是一个分割字符串的类,java中默认的分隔符是:"空格","\t"制表符,"\n"换行符,"\r"回车符
while (itr.hasMoreTokens()) { //判断是否还有分隔符
word.set(itr.nextToken()); //下一个字符串转换为Text类型
//String nextToken():返回从当前位置到下一个分隔符的字符串。
context.write(word, one);
}
}
}
public static class IntSumReducer
//同样的,reduce函数也有四个形式参数类型用于指定输入和输出类型.reduce函数的输入类型必须匹配map函数的输出类型:即Text类型和Intwritable
//在这种情况下,reduce的输出也是Text和Intwritable
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.out.println(otherArgs.length);
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
//Job对象指定作业执行规范.用它控制整个作业的运行.在集群上运行这个作业时,要把代码打包成一个JAR文件
//(Hadoop在集群上发布这个文件).不必明确指定JAR文件的名称.在Job对象的setJarByClass()方法中传递一个类即可
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //指定要用的map类型
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class); //指定要用的reduce类型
job.setOutputKeyClass(Text.class); //控制reduce函数的输出类型
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
//定义输入数据的路径,可以是单个文件,也可以是一个目录(此时,将目录下所有文件当做输入)
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
//定义输出路径,指定reduce函数输出文件的写入目录.在运行作业前该目录是不应该存在的,否则Hadoop会报错并拒绝运行作业.
System.exit(job.waitForCompletion(true) ? 0 : 1);
//waitForCompletion()方法提交作业并等待执行完成.该方法唯一的参数是一个标识,指示是否已生成详细输出.当标识为true(成功)时,作业会把其进度信息写到控制台
}
}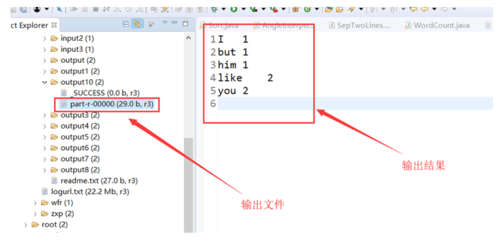
结果
作者:枫雪浅语
链接:https://www.jianshu.com/p/ed8141511b8b





