正则表达式的定义
正则表达式(re)(Regular Expression)。正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
在python中,可以通过内置的re模块引用。
功能:
可以为想要匹配的 相应字符串集指定规则
该字符串集可能包含英文语句,e-amil地址,命令或者任何你想要的东西。
正则表达式——元字符
1. [ ]
常用来指定一个字符集:[abc]; [a-z]
元字符在字符集中不起作用:[akm$]
补集匹配不在区间范围内的字符:[^5]
2. ^
匹配行首。除非设置MULTILINE标志,它只是匹配字符串的开始。在MULTILINE模式里,它也可以直接匹配字符串中的每个换行。
3. &
重复的使用
*
指定前一个字符可以被匹配零次,或更多次,而不是只有一次,匹配引擎会试着重复尽可能多的次数 (不会超过整数的界定范围,20亿) 例如: a[bcd]*b ----- "abcbd"
匹配行尾,行尾被定义为要么是字符串,要么是一个换行字符后面的任何位置。
* +*
表示匹配一或更多次。
注意: 和——之间的不同;匹配零或更多次,所以可以根本就不出现,而+则要求至少出现一次。
?**
匹配一次或零次;可以认为它用于标识某事物是可选的。
{m,n}
其中m和n是十进制整数。该限定符的意思是至少有m个重复,至多到n个重复。a/{1,3}b
忽略m会认为下边界是0,而忽略n的结果将是上边界为无穷大(实际上是20亿)
{0,}等同于,{1,}等同于+,而{0,1}则与?相同。如果可以的话,最好使用*,+,或?
转义字符 \ 的使用
可以用 \ 取消所有的元字符:[ \
\d 匹配任何十进制数,它相当于类 [0-9]
\D 匹配任何非数字字符,它相当于类[^0-9]
\s 匹配任何空白字符,它相当于类[\t\n\r\f\v]
\S 匹配任何非空白字符,它相当于类[^\t\n\r\f\v]
\w 匹配任何字母数字字符,它相当于类[a-z A-Z 0-9]
\W 匹配任何非字母数字字符,它相当于类[^a-z A-Z 0-9]
python中re模块的使用
在Python中使用正则表达式,python提供了re模块,包含所有正则表达式的功能。
由于python的字符串本身也用 \ 转义,所以要注意,例如:
s = 'ABC\-001' # Python的字符串
对应的正则表达式字符串变成:
'ABC-001'
因此,为了避免冲突,建议使用Python中的 r 前缀,就不用考虑转义的问题了!python中自带了re模块,可以通过
import re来使用这个模块,re模块有许多方法,下图给出了所有的方法,在ipython中可以查看具体每个方法的具体含义。
以下列出了一些常用的方法:1.re.findall(pattern,string,flags=0) :返回一个包含所有不重复匹配字符串的元组。
例1: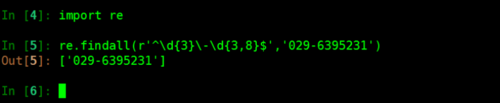
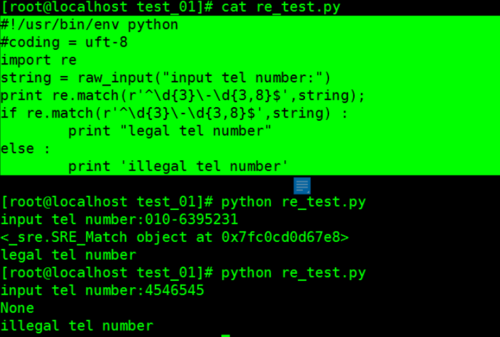
re.match(pattern, string, flags=0) : 从字符串开头匹配正则表达式,如果匹配返回一个匹配的对象,如果没有匹配返回None,常结合if判断语句使用
例2: