
分布式事务
由于我们将单表的数据切片后存储在多个数据库甚至多个数据库实例中,所以依靠数据库本身的事务机制不能满足所有场景的需要。但是,我们推荐在一个数据库实例中的操作尽可能使用本地事务来保证一致性,跨数据库实例的一系列更新操作需要根据事务路由在不同的数据源中完成,各个数据源之间的更新操作需要通过分布式事务处理。
这里只介绍实现分布式操作一致性的几个主流思路,保证分布式事务一致性的具体方法请参考《分布式服务架构:原理、设计与实战》中第2章的内容。
主流的分布式事务解决方案有三种:两阶段提交协议、最大努力保证模式和事务补偿机制。
1
两阶段提交协议
两阶段提交协议将分布式事务分为两个阶段,一个是准备阶段,一个是提交阶段,两个阶段都由事务管理器发起。基于两阶段提交协议,事务管理器能够最大限度地保证跨数据库操作的事务的原子性,是分布式系统环境下最严格的事务实现方法。符合J2EE规范的AppServer(例如:Websphere、Weblogic、
Jboss等)对关系型数据库数据源和消息队列都实现了两阶段提交协议,只需在使用时配置即可。如图3-9所示。
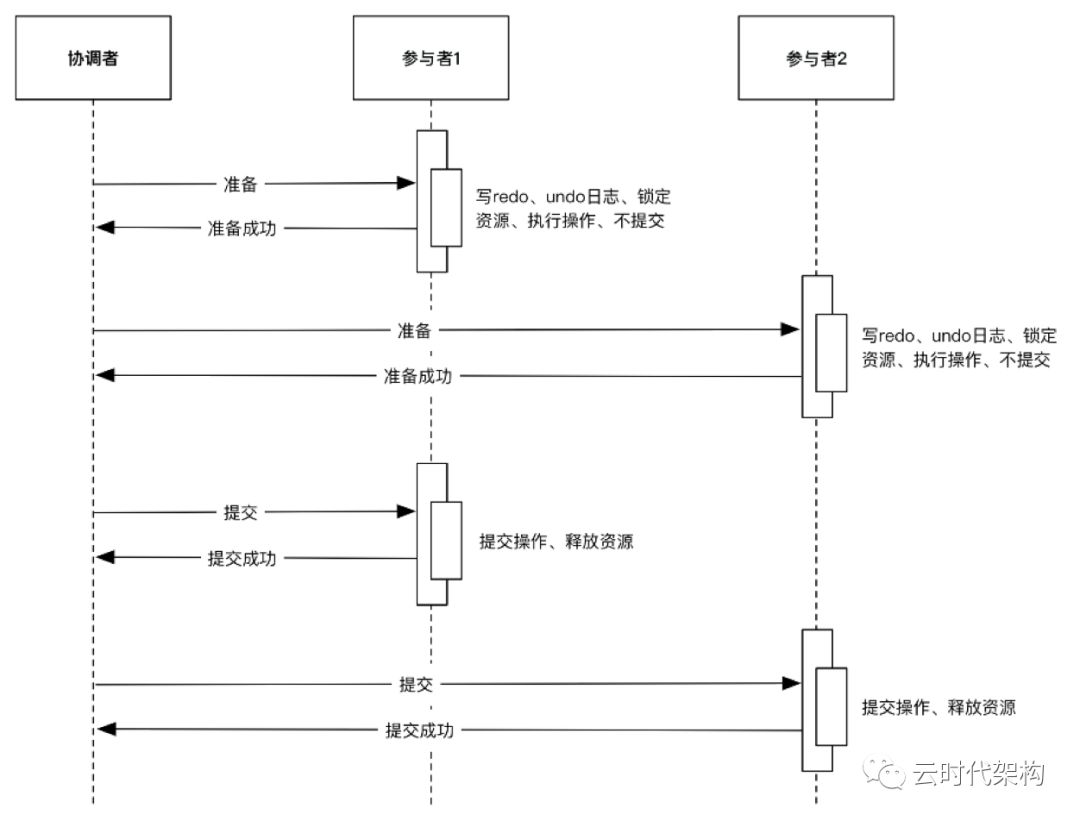
但是,两阶段提交协议也带来了性能方面的问题,难于进行水平伸缩,因为在提交事务的过程中,事务管理器需要和每个参与者进行准备和提交的操作的协调,在准备阶段锁定资源,在提交阶段消费资源,但是由于参与者较多,锁定资源和消费资源之间的时间差被拉长,导致响应速度较慢,在此期间产生死锁或者不确定结果的可能性较大。因此,在互联网行业里,为了追求性能的提升,很少使用两阶段提交协议。
另外,由于两阶段提交协议是阻塞协议,在极端情况下不能快速响应请求方,因此有人提出了三阶段提交协议,解决了两阶段提交协议的阻塞问题,但仍然需要事务管理器在参与者之间协调,才能完成一个分布式事务。
2
最大努力保证模式
这是一种非常通用的保证分布式一致性的模式,很多开发人员一直在使用,但是并未意识到这是一种模式。最大努力保证模式适用于对一致性要求并不十分严格但是对性能要求较高的场景。
具体的实现方法是,在更新多个资源时,将多个资源的提交尽量延后到最后一刻处理,这样的话,如果业务流程出现问题,则所有的资源更新都可以回滚,事务仍然保持一致。唯一可能出现问题的情况是在提交多个资源时发生了系统问题,比如网络问题等,但是这种情况是非常罕见的,一旦出现这种情况,就需要进行实时补偿,将已提交的事务进行回滚,这和我们常说的TCC模式有些类似。
下面是使用最大努力保证模式的一个样例,在该样例中涉及两个操作,一个是从消息队列消费消息,一个是更新数据库,需要保证分布式的一致性。
开始消息事务。
开始数据库事务。
接收消息。
更新数据库。
提交数据库事务。
提交消息事务。
这时,从第1步到第4步并不是很关键,关键的是第5步和第6步,需要将其放在最后一起提交,尽最大努力保证前面的业务处理的一致性。到了第5步和第6步,业务逻辑处理完成,这时只可能发生系统错误,如果第5步失败,则可以将消息队列和数据库事务全部回滚,保持一致。如果第5步成功,第6步遇到了网络超时等问题,则这是唯一可能产生问题的情况,在这种情况下,消息的消费过程并没有被提交到消息队列,消息队列可能会重新发送消息给其他消息处理服务,这会导致消息被重复消费,但是可以通过幂等处理来保证消除重复消息带来的影响。
当然,在使用这种模式时,我们要充分考虑每个资源的提交顺序。我们在生产实践中遇到的一种反模式,就是在数据库事务中嵌套远程调用,而且远程调用是耗时任务,导致数据库事务被拉长,最后拖垮数据库。因此,上面的案例涉及的是消息事务嵌套数据库事务,在这里必须进行充分评估和设计,才可以规避事务风险。
3
事务补偿机制
显然,在对性能要求很高的场景中,两阶段提交协议并不是一种好方案,最大努力保证模式也会使多个分布式操作互相嵌套,有可能互相影响。这里,我们给出事务补偿机制,其性能很高,并且能够尽最大可能地保证事务的最终一致性。
在数据库分库分表后,如果涉及的多个更新操作在某一个数据库范围内完成,则可以使用数据库内的本地事务保证一致性;对于跨库的多个操作,可通过补偿和重试,使其在一定的时间窗口内完成操作,这样就可以实现事务的最终一致性,突破事务遇到问题就滚回的传统思路。
如果采用事务补偿机制,则在遇到问题时,我们需要记录遇到问题的环境、信息、步骤、状态等,后续通过重试机制使其达到最终一致性,详细内容可以参考《分布式服务架构:原理、设计与实战》第2章,彻底理解ACID原理、CAP理论、BASE原理、最终一致性模式等内容。
事务路由
无论使用上面哪种方法实现分布式事务,都需要对分库分表的多个数据源路由事务,一般通过对Spring环境的配置,为不同的数据源配置不同的事务管理器(TransactionManager),这样,如果更新操作在一个数据库实例内发生,便可以使用数据源的事务来处理。对于跨数据源的事务,可通过在应用层使用最大努力保证模式和事务补偿机制来达成事务的一致性。当然,有时我们需要通过编写程序来选择数据库的事务管理器,根据实现方式的不同,可将事务路由具体分为以下三种。
1
自动提交事务路由
自动提交事务通过依赖JDBC数据源的自动提交事务特性,对任何数据库进行更新操作后会自动提交事务,不需要开发人员手工操作事务,也不需要配置事务,实现起来很简单,但是只能满足简单的业务逻辑需求。
在通常情况下,JDBC在连接创建后默认设置自动提交为true,当然,也可以在获取连接后手工修改这个属性,代码如下:
connnection conn = null;
try{
conn = getConnnection();
conn.setAutoCommit(true);
// 数据库操作
……………………………
conn.commit();
}catch(Throwable e){
if(conn!=null){
try {
conn.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
throw new RuntimeException(e);
}finally{
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}我们基本不需要使用原始的JDBC API来改变这些属性,这些操作一般都会被封装在我们使用的框架中。3.6节介绍的开源数据库分库分表框架dbsplit默认使用的就是这种模式。
2
可编程事务路由
我们在应用中通常采用Spring的声明式的事务来管理数据库事务,在分库分表时,事务处理是个问题,在一个需要开启事务的方法中,需要动态地确定开启哪个数据库实例的事务,也就是说在每个开启事务的方法调用前就必须确定开启哪个数据源的事务。下面使用伪代码来说明如何实现一个可编程事务路由的小框架。
首先,通过Spring配置文件展示可编程事务小框架是怎么使用的:
<?xml version="1.0?>
<beans>
<bean id="sharding-db-trx0"class="org.springframework.jdbc.datasource.Data SourceTransactionManager">
<property name="dataSource">
<ref bean="sharding-db0" />
</property>
</bean>
<bean id="sharding-db-trx1"
class="org.springframework.jdbc.datasource.DataSourceTransactionMana ger">
<property name="dataSource">
<ref bean="sharding-db1" />
</property>
</bean>
<bean id="sharding-db-trx2"
class="org.springframework.jdbc.datasource.DataSourceTransactionMana ger">
<property name="dataSource">
<ref bean="sharding-db2" />
</property>
</bean>
<bean id="sharding-db-trx3"
class="org.springframework.jdbc.datasource.DataSourceTransactionMana ger">
<property name="dataSource">
<ref bean="sharding-db3" />
</property>
</bean>
<bean id="shardingTransactionManager" class="com.robert.dbsplit.core. ShardingTransactionManager">
<property name="proxyTransactionManagers">
<map value-type="org.springframework.transaction.PlatformTran sactionManager">
<entry key="sharding0" value-ref="sharding-db-trx0" />
<entry key="sharding1" value-ref="sharding-db-trx1" />
<entry key="sharding2" value-ref="sharding-db-trx2" />
<entry key="sharding3" value-ref="sharding-db-trx3" />
</map>
</property>
</bean>
<aop:config>
<aop:advisor advice-ref="txAdvice" pointcut="execution(* com.robert.biz.*insert(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut="execution(* com.robert.biz.*update(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut="execution(* com.robert.biz.*delete(..))"/>
</aop:config>
<tx:advice id="txAdvice" transaction-manager="shardingTransactionManager">
<tx:attributes>
<tx:method name="*" rollback-for="java.lang.Exception"/>
</tx:attributes>
</tx:advice>
</beans>
这里使用Spring环境的aop和tx标签来拦截com.robert.biz包下的所有插入、更新和删除的方法,当指定的包的方法被调用时,就会使用Spring提供的事务Advice,Spring的事务Advice(tx:advice)会使用事务管理器来控制事务,如果某个方法发生了异常,那么Spring的事务Advice就会使shardingTransactionManager回滚相应的事务。
我们看到shardingTransactionManager的类型是ShardingTransactionManager,这个类型是我们开发的一个组合的事务管理器,这个事务管理器聚合了所有分片数据库的事务管理器对象,然后根据某个标记来路由到不同的事务管理器中,这些事务管理器用来控制各个分片的数据源的事务。
这里的标记是什么呢?我们在调用方法时,会提前把分片的标记放进ThreadLocal中,然后在ShardingTransactionManager的getTransaction方法被调用时,取得ThreadLocal中存的标记,最后根据标记来判断使用哪个分片数据库的事务管理器对象。
为了通过标记路由到不同的事务管理器,我们设计了一个专门的ShardingContextHolder类,在该类的内部使用了一个ThreadLocal类来指定分片数据库的关键字,在ShardingTransaction Manager中通过取得这个标记来选择具体的分片数据库的事务管理器对象。因此,这个类提供了setShard和getShard的方法,setShard用于使用者编程指定使用哪个分片数据库的事务管理器,而getShard用于ShardingTransactionManager获取标记并取得分片数据库的事务管理器对象。相关代码如下:
public class ShardingContextHolder<T> {
private static final ThreadLocal shardHolder = new ThreadLocal();
public static <T> void setShard(T shard) {
Validate.notNull(shard, "请指定某个分片数据库!");
shardHolder.set(shard);
}
public static <T> T getShard() {
return (T) shardHolder.get();
}
}有了ShardingContextHolder类后,我们就可以在ShardingTransactionManager中根据给定的分片配置将事务操控权路由到不同分片的数据库的事务管理器上,实现很简单,如果在ThreadLocal中存储了某个分片数据库的事务管理器的关键字,就使用那个分片的数据库的事务管理器:
public class ShardingTransactionManager implements PlatformTransactionManager {
private Map<Object, PlatformTransactionManager> proxyTransactionManagers =
new HashMap<Object, PlatformTransactionManager>();
protected PlatformTransactionManager getTargetTransactionManager() {
Object shard = ShardingContextHolder.getShard();
Validate.notNull(shard, "必须指定一个路由的shard!");
return targetTransactionManagers.get(shard);
}
public void setProxyTransactionManagers(Map<Object, PlatformTransaction Manager> targetTransactionManagers) {
this.targetTransactionManagers = targetTransactionManagers;
}
public void commit(TransactionStatus status) throws TransactionException {
getProxyTransactionManager().commit(status);
}
public TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException {
return getProxyTransactionManager().getTransaction(definition);
}
public void rollback(TransactionStatus status) throws TransactionException
{
getProxyTransactionManager().rollback(status);
}
}有了这些使用类,我们的可编程事务路由小框架就实现了,这样在某个具体的服务开始之前,我们就可以使用如下代码来控制使用某个分片的数据库的事务管理器了:
RoutingContextHolder.setShard("sharding0");
return userService.create(user);3
声明式事务路由
在上一小节实现了可编程事务路由的小框架,这个小框架通过让开发人员在ThreadLocal中指定数据库分片并编程实现。大多数分库分表框架会实现声明式事务路由,也就是在实现的服务方法上直接声明事务的处理注解,注解包含使用哪个数据库分片的事务管理器的信息,这样,开发人员就可以专注于业务逻辑的实现,把事务处理交给框架来实现。
下面是笔者在实际的线上项目中实现的声明式事务路由的一个使用实例:
@TransactionHint(table = "INVOICE", keyPath = "0.accountId")
public void persistInvoice(Invoice invoice) {
// Save invoice to DB
this.createInvoice(invoice);
for (InvoiceItem invoiceItem : invoice.getItems()) {
invoiceItem.setInvId(invoice.getId());
invoiceItemService.createInvoiceItem(invoice.getAccountId(), invoiceItem);
}
// Save invoice to cache
invoiceCacheService.set(invoice.getAccountId(), invoice.getInvPeriodStart().getTime(), invoice.getInvPeriodEnd().getTime(),
invoice);
// Update last invoice date to Account
Account account = new Account();
account.setId(invoice.getAccountId());
account.setLstInvDate(invoice.getInvPeriodEnd());
accountService.updateAccount(account);
}在这个实例中,我们开发了一个持久发票的服务方法。持久发票的服务方法用来保存发票信息和发票项的详情信息,这里,发票与发票项这两个领域对象具有父子结构关系。由于在设计过程中通过账户ID对这个父子表进行分库分表,因此在进行事务路由时,也需要通过账户ID控制使用哪个数据库分片的事务管理器。在这个实例中,我们配置了 TransactionHint,TransactionHint的声明如下:
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface TransactionHint {
String table() default "";
String keyPath() default "";
}可以看到,TransactionHint包含了两个属性,第1个属性table指定这次操作涉及分片的数据库表,第2个属性指定这次操作根据哪个参数的哪个字段进行分片路由。该实例通过table指定了INVOICE表,并通过keyPath指定了使用第1个参数的字段accountId作为路由的关键字。
这里的实现与可编程事务路由的小框架实现类似,在方法persistInvoice被调用时,根据TransactionHint提供的操作的数据库表名称,在Spring环境的配置中找到这个表的分库分表的配置信息,例如:一共分了多少个数据库实例、数据库和表。
下面是在Spring环境中配置的INVOICE表和INVOICE_ITEM表的具体信息,我们看到它们一共使用了两个数据库实例,每个实例有两个库,每个库有8个表,使用水平下标策略。配置如下:
<bean name="billingInvSplitTable" class="com.robert.dbsplit.core.Split Table"init-method="init">
<property name="dbNamePrefix" value="billing_inv"/>
<property name="tableNamePrefix" value="INVOICE"/>
<property name="dbNum" value="2"/>
<property name="tableNum" value="8"/>
<property name="splitStrategyType" value="HORIZONTAL"/>
<property name="splitNodes">
<list>
<ref bean="splitNode0"/>
<ref bean="splitNode1"/>
</list>
</property>
<property name="readWriteSeparate" value="true"/>
</bean>
<bean name="billingInvItemSplitTable" class="com.robert.dbsplit.core.SplitTable"
init-method="init">
<property name="dbNamePrefix" value="billing_inv"/>
<property name="tableNamePrefix" value="INVOICE_ITEM"/>
<property name="dbNum" value="2"/>
<property name="tableNum" value="8"/>
<property name="splitStrategyType" value="HORIZONTAL"/>
<property name="splitNodes">
<list>
<ref bean="splitNode0"/>
<ref bean="splitNode1"/>
</list>
</property>
<property name="readWriteSeparate" value="true"/>
</bean>然后,在方法被调用时通过AOP进行拦截,根据TransactionHint配置的路由的主键信息keyPath ="0.accountId",得知这次根据第0个参数Invoice的accountID字段来路由,根据Invoice的accountID的值来计算这次持久发票表具体涉及哪个数据库分片,然后把这个数据库分片的信息保存到ThreadLocal中。具体的实现代码如下:
SimpleSplitJdbcTemplate simpleSplitJdbcTemplate =
(SimpleSplitJdbcTemplate) ReflectionUtil.getFieldValue(field SimpleSplitJdbcTemplate, invocation.getThis());
Method method = invocation.getMethod();
// Convert to th method of implementation class
method = targetClass.getMethod(method.getName(), method.getParameter Types());
TransactionHint[] transactionHints = method.getAnnotationsByType (TransactionHint.class);
if (transactionHints == null || transactionHints.length < 1)
throw new IllegalArgumentException("The method " + method + " includes illegal transaction hint.");
TransactionHint transactionHint = transactionHints[0];
String tableName = transactionHint.table();
String keyPath = transactionHint.keyPath();
String[] parts = keyPath.split("\\.");
int paramIndex = Integer.valueOf(parts[0]);
Object[] params = invocation.getArguments();
Object splitKey = params[paramIndex];
if (parts.length > 1) {
String[] paths = Arrays.copyOfRange(parts, 1, parts.length);
splitKey = ReflectionUtil.getFieldValueByPath(splitKey, paths);
}
SplitNode splitNode = simpleSplitJdbcTemplate.decideSplitNode(tableName, splitKey);
ThreadContextHolder.INST.setContext(splitNode);ThreadContextHolder是一个单例的对象,在该对象里封装了一个ThreadLocal,用来存储某个方法在某个线程下关联的分片信息:
public class ThreadContextHolder<T> {
public static final ThreadContextHolder<SplitNode> INST = new ThreadContextHolder<SplitNode>();
private ThreadLocal<T> contextHolder = new ThreadLocal<T>();
public T getContext() {
return contextHolder.get();
}
public void setContext(T context) {
contextHolder.set(context);
}
}接下来与可编程式事务路由类似,实现一个定制化的事务管理器,在获取目标事务管理器时,通过我们在ThreadLocal中保存的数据库分片信息,获得这个分片数据库的事务管理器,然后返回:
public class RoutingTransactionManager implements PlatformTransactionManager {
protected PlatformTransactionManager getTargetTransactionManager() {
SplitNode splitNode = ThreadContextHolder.INST.getContext();
return splitNode.getPlatformTransactionManager();
}
public void commit(TransactionStatus status) throws TransactionException {
getTargetTransactionManager().commit(status);
}
public TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException {
return getTargetTransactionManager().getTransaction(definition);
}
public void rollback(TransactionStatus status) throws TransactionException
{
getTargetTransactionManager().rollback(status);
}
}本节介绍的开源数据库分库分表框架dbsplit是一个分库分表的简单示例实现,在笔者所工作的公司内部有内部版本,在内部版本中实现了声明式事务路由,但是这部分功能并没有开源到dbsplit项目,原因是有些与业务结合的逻辑无法分离。如果感兴趣,则可以加入我们的开源项目开发中。
END




