
日常前言
五月六月,又陷入反反复复的项目 Bug 中了。讲道理,分析日志是越来越熟练了,代码水平其实没有很大提高,毕竟改 Bug 嘛,大多只是在原有代码的基础上,添加或者修改一些业务逻辑。虽然改原生代码的时候能学到很多东西,但是那些部分很少出现问题,绝大部分还是我们自己人加入、修改的逻辑挖出来的坑。填坑的过程真是漫长又令人心烦。
时间有限,这次的翻译也只选了五个短篇,尽量提高内容质量同时也节省出一些业余时间学习一些其它知识。
不过这次翻译对我来说,收获颇丰。在翻译其中两篇文章的时候,我做了详细的笔记,并且在阅读过程中查阅了不少相关资料,学到了很多东西。
其中一篇是数据可视化的艺术,虽然只是以网页性能分析为例,对各种常用图表作了简单的适用场景的介绍,但是这正是我最近需要了解的内容 —— 由于业务原因,我需要经常接入第三方算法,并评测其性能。然而组内一直都是用打印 Log 的方式去分析性能,很不方便,而且经常会忽略掉一些异常变化。我正需要一些方法提高我们的性能分析效率,而这篇文章则给我指明了方向。
另一篇则是关于概率数据结构的介绍。选择翻译这篇文章是因为看到了 Bloom Filter,这让我想起了大学时给老师打工写爬虫的时光……这次顺势重温了 Bloom Filter,并了解了 HyperLogLog 与 Min-Count Sketch 这两个算法。我总觉得在不久的将来我就会用上它们。
这一期文章依旧采纳了四篇:
说到版权问题,我其实不太清楚我这样中英翻译的方式发 Blog 是不是侵了英文原版的版权了。但是如果不是中英翻译的话,发这些 Blog 就是多此一举了。如果侵权了的话,以后再删掉吧~
版权相关
翻译人:StoneDemo,该成员来自云+社区翻译社
原文链接:Fast Data Pipeline Design: Updating Per-Event Decisions by Swapping Tables
原文作者:John Piekos
Fast Data Pipeline Design: Updating Per-Event Decisions by Swapping Tables
题目:(快速数据管道设计:通过交换表更新各个事件决策)
A term used often by VoltDB, fast data pipelines are a new modern breed of applications — applications that combine streaming, or “fast data,” tightly with big data.
在 VoltDB(这是一种数据库) 经常使用到的术语,快速数据管道(Fast data pipeline),这是一种全新的现代应用程序 —— 这种应用程序将流式传输(或者说 “快速数据”) 与大数据紧密结合在了一起。
First, a quick high-level summary of the fast data pipeline architecture:
首先,对快速数据流水线架构进行快速的高度总结:
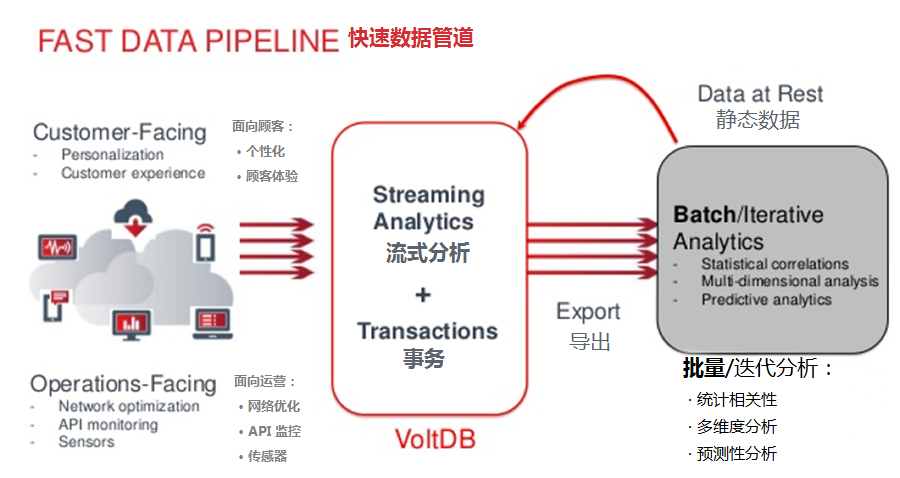
The first thing to notice is that there is a tight coupling of fast and big, although they are separate systems. They have to be, at least at scale. The database system designed to work with millions of event decisions per second is wholly different from the system designed to hold petabytes of data and generate machine learning (ML) models.
首先需要注意的事情是,快(Fast) 与 大(Big) 是紧密耦合的,即使他们是独立的系统。他们必须是紧密耦合的,至少是在规模上。设计用于每秒处理数百万次事件决策的数据库系统,与设计用于容纳数 PB 数据并生成机器学习(ML,Machine Learning)模型的系统完全不同。
There are a number of critical requirements to get the most out of a fast data pipeline. These include the ability to:
Ingest/interact with the data feed in real-time.
Make decisions on each event in the feed in real-time.
Provide visibility into fast-moving data with real-time analytics.
Seamlessly integrate into the systems designed to store big data.
Ability to deliver analytic results (mined “knowledge”) from the big data systems quickly to the decision engine, closing the data loop. This mined knowledge can be used to inform per event decisions.
要充分利用快速数据管道,有许多关键需求。这包括以下列出的能力:
实时地摄取流入(Feed)的数据、与数据进行交互。
实时地对流入的每个事件做出决策。
通过实时分析,为快速移动的数据提供可视性(Visibility)。
无缝集成到旨在存储大数据的系统中。
能够将大数据系统的分析结果(挖掘到的 “知识”)迅速提供给决策引擎,从而关闭数据循环(Data loop)。这些挖掘到的知识可用于告知每个事件决策。
Hundreds of fast data pipeline applications have been built and deployed using VoltDB as the fast operational database (the glue) between fast and big. These applications provide real-time decisioning engines in financial fraud detection, digital ad tech optimization, electric smart grid, mobile gaming and IoT industries, among others.
有数百个快速管道应用程序已经被构建与部署,它们使用 VoltDB 作为 “快” 与 ”大“ 之间的快速操作数据库(正如胶水)。这些应用程序为金融欺诈检测、数字广告技术优化、智能电网、手机游戏,以及物联网等行业提供实时决策引擎。
This blog is going to drill into how to implement a specific portion of this fast data pipeline, namely the last bullet: The ability to close the data loop, taking knowledge from a big data system and applying this knowledge, online, to the real-time decision engine (VoltDB).
本篇博客将深入探讨如何实现这一快速数据管道的特定部分,也就是最后一个重点:关闭数据循环,从大数据系统获取知识,并将这些知识在线应用于实时决策引擎(VoltDB)的能力。
Closing the Data Loop
(关闭数据循环)
“Per-event decisioning” means that an action is computed for each incoming event (each transaction). Usually, some set of facts informs the decision, often computed from historical data. These “facts” could be captured in machine learning models or consist of a set of generated rules to be executed on each incoming event. Or, these facts could be represented as rows in a database table and used to filter and generate optimized decisions for each event. This blog post will focus on the latter: storing and updating facts represented in database tables.
“每一事件的决策” 意味着为每个传入事件(即每次事务)进行计算操作。通常,一些事实的集合会告知我们决策,而这些事实一般是从历史数据中计算而来的。我们可以在机器学习模型中捕获到这些 “事实(Fact)”,或者用一组生成的规则来组成 “事实”,从而在每个进入的事件上执行。或者,这些事实可以表示为数据库表中的行,并用于为每个事件进行过滤,并生成优化的决策。这篇博文将重点介绍后者:存储与更新数据库表中的事实。
When storing facts in database tables, each row corresponds to some bit of intelligence for a particular value or set of values. For example, the facts might be a pricing table for airline flights, where each row corresponds to a route and service level. Or the values might be a list of demographic segmentation buckets (median income, marital status, etc.) for browser cookies or device IDs, used to serve up demographic-specific ads.
将事实存储在数据库表中时,每一行对应着某特定值或一组值的一些情报。举个例子,航空公司航班的定价表,表中每一行对应于航线以及服务等级。或者,这些值可能是为浏览器 Cookie、设备 ID 而准备的人口统计分段列表(Demographic segmentation buckets)(其中内容包括收入中位数、婚姻状况等等),用于给特定人群提供针对性的广告。
Fact tables are application-specific, can be simple or sophisticated, and are often computed from a historical “big data” data set such as Spark, Hadoop, or commercial data warehouse, etc. Fact tables can often be quite large and can be frequently recomputed, perhaps weekly, daily, or even hourly.
事实表是面向具体应用(Application-specific)的,它可以是简单的,也可以是复杂的,并且通常是从诸如 Spark,Hadoop 或商业数据仓库等,这般历史 “大数据” 数据集计算而来的。事实表通常可以非常大,并且可以频繁地重新计算(也许周期是一周、一天,甚至一个小时)。
It is often important that the set of facts changes atomically. In other words, if airline prices are changing for ten’s of thousands of flights, all the prices should change all at once, instantly. It is unacceptable that some transactions reference older prices and some newer prices during the period of time it takes to load millions of rows of new data. This problem can be challenging when dealing with large fact tables, as transactionally changing millions of values in can be a slow, blocking operation. Locking a table, thus blocking ongoing operations, is unacceptable when your application is processing hundreds of thousands of transactions per second.
对这些事实集合来说,其变化是原子性(Atomically)的,这一点通常很重要。换句话说,如果成千上万的航班的航线价格发生了变化,则所有的价格都应该即刻进行变化。某些事务在加载数百万行新数据所需的时间段内引用到较旧的价格和一些较新的价格,这种情况是不可接受的。在处理大型事实表时,这个问题极具挑战性,因为事务性地改变数百万个值可能是一个缓慢的阻塞操作。当您的应用程序正每秒处理数十万个事务时,锁住表格以阻止正在进行的操作是无法接受的。
VoltDB solves this challenge in a very simple and efficient manner. VoltDB has the ability to transactionally swap tables in a single operation. How this works is as follows:
1. Create an exact copy of your fact table schema, giving it a different name — perhaps Facts_Table and Facts_Table_2.
2. Make sure the schemas are indeed identical (and neither is the source of a view).
3. While your application is running (and consulting rows in Facts_Table to make decisions), populate Facts_Table_2with your new set of data that you wish future transactions to consult. This table can be populated as slowly (or as quickly) as you like, perhaps over the course of a day.
4. When your Facts_Table_2 is populated and you are ready to make it “live” in your application, call the VoltDB system procedure @SwapTables. This operation essentially switches the data for the table by swapping internal memory pointers. As such, it executes in single to a sub-millisecond range.
5. At this point, all the data that was in Facts_Table_2 is now in Facts_Table, and the old data in Facts_Table now resides in Facts_Table_2. You may consider truncating Facts_Table_2 in preparation for your next refresh of facts (and to reduce your memory footprint).
VoltDB 以非常简单和高效的方式解决了这一挑战。VoltDB 能够在单个操作中事务性地交换表。其工作逻辑如下所示:
为你的事实表模式(Schema)创建一个精确的副本,并给它起一个不同的名字 —— 例如
Facts_Table与Facts_Table_2。确保模式确确实实是相同的(并且两者不是同一视图的来源)。
当您的应用程序正在运行(并查询
Facts_Table中的行来做决策)时,用你想给未来的事务进行查询的新数据集合来填充Facts_Table_2。这张表格可以按照你喜欢的方式慢慢(或者快速)地填充,也许是在一天之内。当您的
Facts_Table_2已被填充,并准备好使其在应用程序中 “实时(Live)” 时,请调用 VoltDB 的系统程序@SwapTables。该操作实质上通过交换内部存储器指针来切换表的数据。因此,它的执行时间在单毫秒范围之内。此时,所有
Facts_Table_2的数据都已经在Facts_Table中,并且Facts_Table的旧数据现在驻留在Facts_Table_2中。您可以考虑截断Facts_Table_2,以准备下一次刷新事实表(同时减少内存占用)。
Let’s look at a contrived example using the VoltDB Voter sample application, a simple simulation of an American Idol voting system. Let’s assume that each day, you are going to feature different contestants for whom callers can vote. Voting needs to occur 24×7, each day, with new contestants. The contestants change every day at midnight. We don’t want any downtime — no maintenance window, for example — when changing our contestant list.
让我们来看一个特定的例子:使用 VoltDB 的选民示例应用。这是一个对美国偶像投票系统的简单模拟。我们假设每天都会有不同的参赛者,调用者可以对他们进行投票。投票需要每天(24 × 7 不间断地)进行。参赛者在每天午夜时分发生变化。我们不希望出现任何停机时间 —— 例如,当更改我们的参赛者名单时,不需要使用维护窗口。
Here’s what we need to do to the Voter sample to effect this behavior:
以下是我们需要对选民示例执行此操作的方法:
1.First, we create an exact copy of our CONTESTANTS table, calling it CONTESTANTS_2:
1.首先,创建一个我们的 CONTESTANTS 表的精确副本,并将其命名为 CONTESTANTS_2 :
-- contestants_2 table holds the next day's contestants numbers -- (for voting) and namesCREATE TABLE contestants_2 ( contestant_number integer NOT NULL, contestant_name varchar(50) NOT NULL, CONSTRAINT PK_contestants_2 PRIMARY KEY ( contestant_number ) );12345678910
2.The schemas are identical, and this table is not the source of a materialized view.
2.模式是相同的,并且该表不是一个实体化视图的来源。
3.The voter application pre-loads the CONTESTANTS table at the start of the benchmark with the following contestants:
3.在基准测试开始时,选民应用预先加载的 CONTESTANTS 表为以下列内容:
>;; select * from contestants; CONTESTANT_NUMBER CONTESTANT_NAME ------------------ ---------------- 1 Edwina Burnam 2 Tabatha Gehling 3 Kelly Clauss 4 Jessie Alloway 5 Alana Bregman 6 Jessie Eichman $ cat contestants_2.csv1, Tom Brady2, Matt Ryan3, Aaron Rodgers4, Drew Brees5, Andrew Luck6, Kirk Cousins $ csvloader contestants_2 -f contestants_2.csvRead 6 rows from file and successfully inserted 6 rows (final) Elapsed time: 0.905 seconds $ sqlcmd SQL Command :: localhost:212121>;; select * from contestants_2; CONTESTANT_NUMBER CONTESTANT_NAME ------------------ ---------------- 1 Tom Brady 2 Matt Ryan 3 Aaron Rodgers 4 Drew Brees 5 Andrew Luck 6 Kirk Cousins(Returned 6 rows in 0.01s)
4.Now that we have the new contestants (fact table) loaded and staged, when we’re ready (at midnight!) we’ll swap the two tables, making the new set of contestants immediately available for voting without interrupting the application. We’ll do this by calling the @SwapTables system procedure as follows:
4.现在我们已经加载并展示了新的参赛者(事实表),当我们准备好(即在午夜)时,我们将交换这两个表,使得新的参赛者立即可用于投票而不中断应用。我们将通过调用系统程序来完成此操作,如下所示:
$ sqlcmd SQL Command :: localhost:21212 1>;; exec @SwapTables contestants_2 contestants; modified_tuples ---------------- 12(Returned 1 rows in 0.02s) 2>;; select * from contestants; CONTESTANT_NUMBER CONTESTANT_NAME ------------------ ---------------- 6 Kirk Cousins 5 Andrew Luck 4 Drew Brees 3 Aaron Rodgers 2 Matt Ryan 1 Tom Brady (Returned 6 rows in 0.01s)
5.Finally, we’ll truncate the CONTESTANTS_2 table, initializing it once again so it’s ready to be loaded with the next day’s contestants:
5.最后,我们将截断 CONTESTANTS_2 表,并再次初始化它,以便它可以继续加载第二天的参赛者:
$ sqlcmd SQL Command :: localhost:21212 1>;; truncate table contestants_2; (Returned 6 rows in 0.03s) 2>;; select * from contestants_2; CONTESTANT_NUMBER CONTESTANT_NAME ------------------ ----------------(Returned 0 rows in 0.00s)12345678
Note that steps 3-5 — loading, swapping, and truncating the new fact table — can all be done in an automated fashion, not manually as I have demonstrated with this simple example. Running the Voter sample and arbitrarily invoking @SwapTables during the middle of the run yielded the following results:
请注意,第 3 至第 5 步 —— 加载,交换和截断新事实表,都可以以自动方式完成,而不是像我在这个简单示例中演示的那样手动完成。运行选民示例并在运行过程中任意调用 @SwapTables,可得出以下结果:
A total of 15,294,976 votes were received during the benchmark... - 15,142,056 Accepted - 152,857 Rejected (Invalid Contestant) - 63 Rejected (Maximum Vote Count Reached) - 0 Failed (Transaction Error)Contestant Name Votes Received Tom Brady 4,472,147 Kirk Cousins 3,036,647 Andrew Luck 2,193,442 Matt Ryan 1,986,615 Drew Brees 1,963,903 Aaron Rodgers 1,937,391 The Winner is: Tom Brady
Apologies to those not New England-based! As you might have guessed, VoltDB’s headquarters are based just outside of Boston, Massachusetts!
对那些非新英格兰的人道一声抱歉!正如您可能已经猜到的那样,VoltDB 的总部位于波士顿的马萨诸塞州之外!





