
注:
在本文中经常会提到输出数据的维度,为了防止读者产生错误的理解,在本文的开头做一下说明。 
如上图,原始图像大小为5*5,经过一次卷积后,图像变为3*3。那就是5*5的输入,经过一个卷积层后,输出的维度变为3*3,再经过一个卷积层,输出的维度变为1*1,这里的5*5,3*3和1*1即为本文提到的数据的维度。
1、什么是语义分割
图像语义分割可以说是图像理解的基石性技术,在自动驾驶系统(具体为街景识别与理解)、无人机应用(着陆点判断)以及穿戴式设备应用中举足轻重。我们都知道,图像是由许多像素(Pixel)组成,而「语义分割」顾名思义就是将像素按照图像中表达语义含义的不同进行分组(Grouping)/分割(Segmentation)。 
上面的图片就是一个具体的语义分割的例子。左边的实际图片作为输入,我们想要通过一定的算法,得出右边的分割图片。
2、 语义分割算法介绍
2.1 FCNN(全连接卷积神经网络)
2014年,来自UC Berkeley 的Trevor Darrell 组在2014年提出了全连接的卷积神经网络,开启了卷积神经网络应用在语义分割的先河。由于用于图像分类和检测的卷积神经网络关注的是图像级,所以在卷积网络的后面会有全连接层,用于降低网络的维度,输出我们想要的分类信息和位置信息;但是语义分割关注的是图像的像素级(Pixel-level),我们希望输入的是一张图片,输出的仍然是尺寸基本一致的图片,所以在FCNN中,去掉了一般卷积网络后面的全连接层。 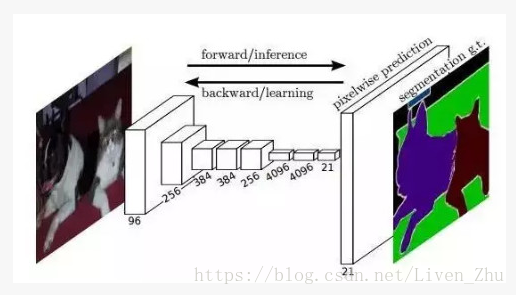
上图就是FCNN的基本架构。在经过一个全卷积的预训练的网络之后,比如说VGG,由于池化操作降低了图像空间维度,特征map仍然需要被上采样。与简单的双线性插值不同,反卷积层可以学习插值。该层也叫上卷积(upconvolution),全卷积(full convolution),转置卷积(transpose convolution)或者分数化卷积(fractionally-strided convolution)。 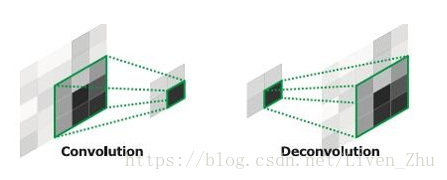
然而,上采样(即反卷积层)产生粗糙的分割图,是因为在池化过程中信息的丢失。因此,跳转连接能够产生分辨率更高的特征对应图。 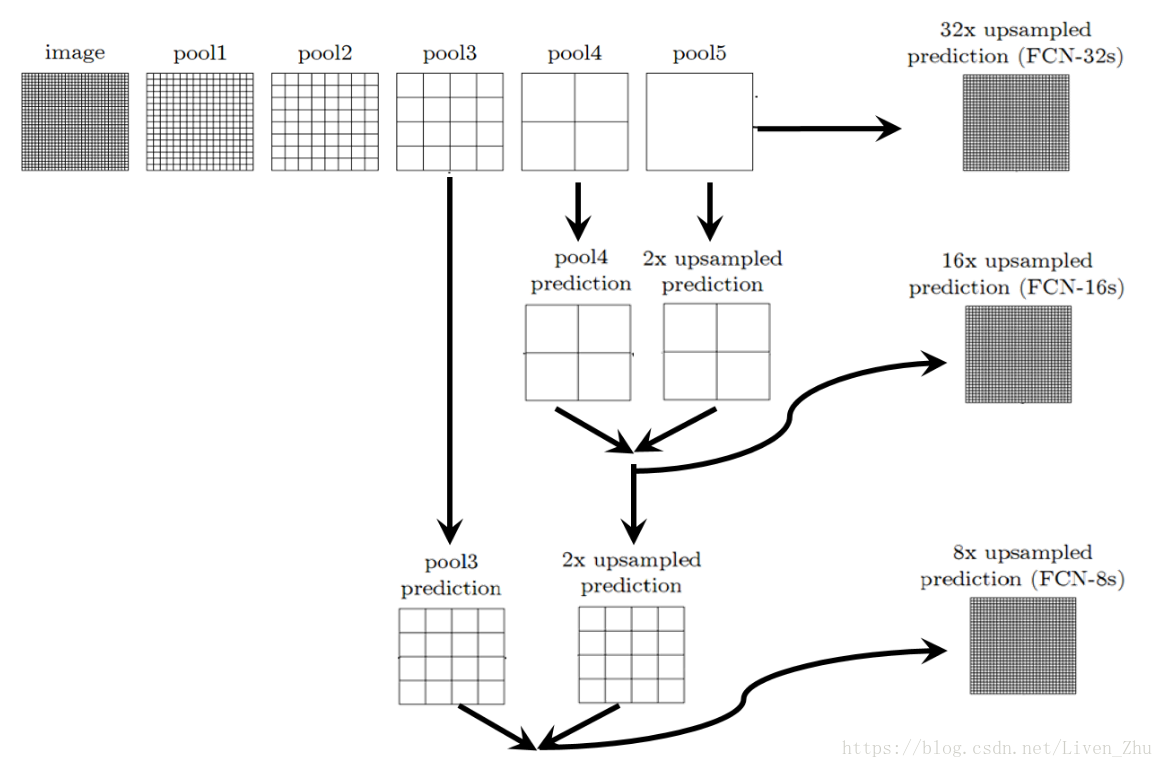
跳转连接如上图。我们不再仅仅用最后的池化层的输出的来进行反卷积,而是利用前面的池化层的输出为我们提供更多的原始图片的信息。原文的作者对这种方案进行了对比:
1、用pool5的输出作为上采样(反卷积)的输入,由于经过了5个池化层,图像被缩小到原始图像的1/32,所以使用上采样将pool5的输出放大32倍,得到一个32倍放大的分割图。
2、用pool5的输出采用上采样2倍放大,与pool4的输出叠加后,再经过上采样16倍放大,得到一个输出16倍放大的分割图。
3、将pool5和pool4的叠加和2倍放大后,再叠加pool3的输出,然后呢进行上采样8倍放大,最后得到一个8倍放大的分割图。 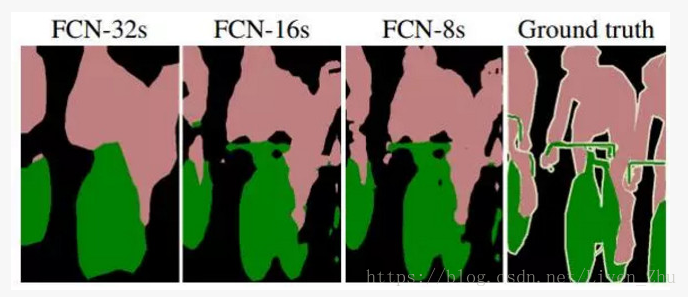
上图就是三种分割方案与真实分割的对比,显然,采用第三种分割方案的分辨率更高。这是由于,仅采用pool5的输出做上采样进行32倍放大,由于pool5输出的每一个元素的感受域更大,导致原始图像中很多细节的特征丢失,所以得到的分割图就相对比较粗糙。而后面的两种方案,分别加进了前面池化层的输出,由于前面池化层的输出数据的每一个元素的感受域相对较小,所以很多原始图像的细节特征得以保留,得到的分割图的分辨率就更高。
下面简单说一下什么是感受域? 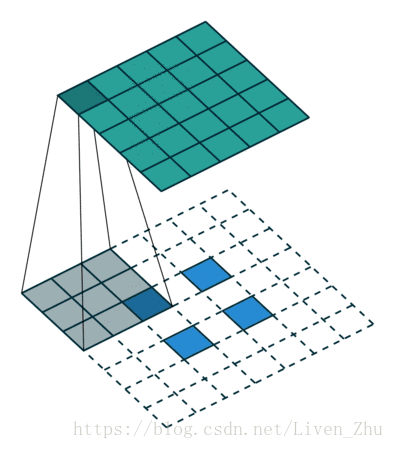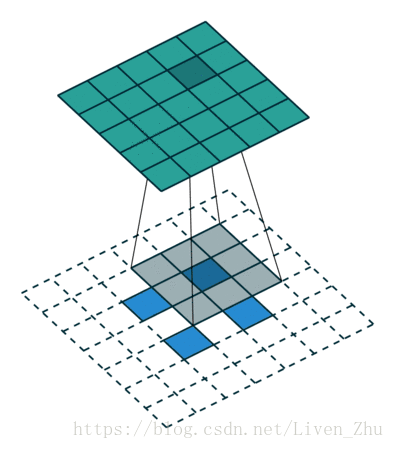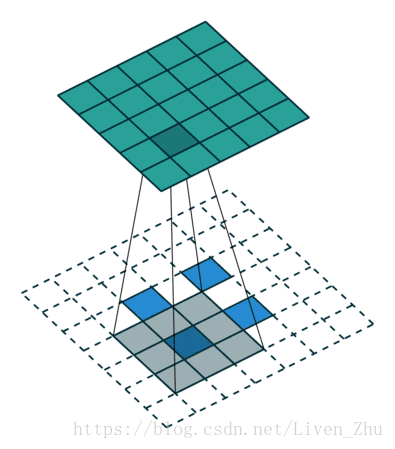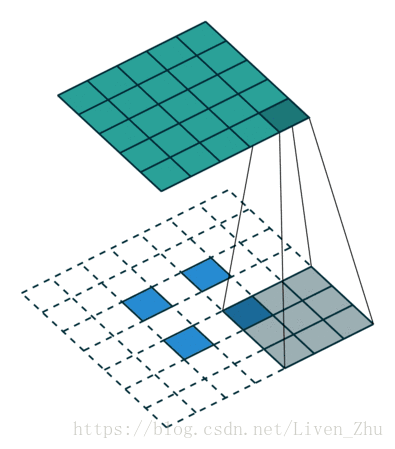
感受域主要取决于卷积和池化的kernel和stride的大小。如上动图,在kernel大小为3*3,stride为1时,经过一个卷积层后,每一个像素的感受域即为9。所以在经过更多层卷积和池化后,图片的维度越来越小,每个元素的感受域也就会越来越大。
2.2 SegNet
SegNet是基于FCNN的架构提出的。下面先来看一下SegNet的结构: 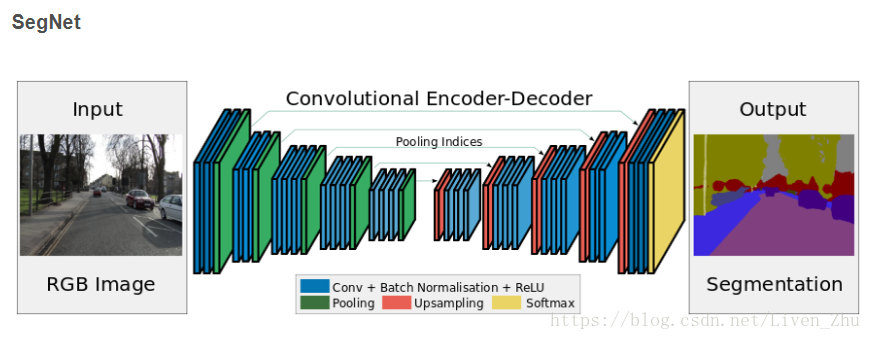
FCNN的缺点就是得到的分割图的分辨率较低,因此SegNet在FCNN的基础上增加了上池化层。 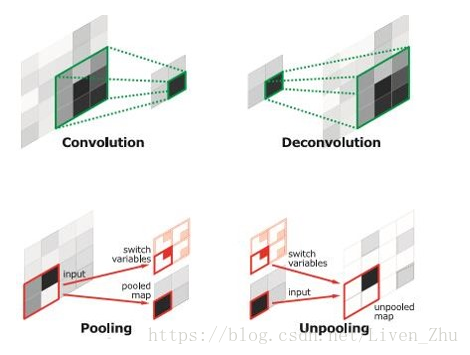
上池化层相对于池化层与反卷积相对于卷积层类似,也是将低维数据扩展到高维。在SegNet前半段进行池化时,记住每一个池化输出在池化输入中的位置,然后在上池化时,将该输出周围相应的位置填0,即完成了数据维度的放大。
SegNet采用了一种完全对称的结构,卷积与反卷积对称,池化和上池化对称,由此构成了一个encoder-decoder的结构。
2.3 Dilated Convolutions
在利用CNN进行图像分类时,pooling可以通过增加感受域的大小,从而对图像的宏观特征有更好的描述,有助于进行分类。而在进行图像分割任务时,我们关注的是图像的像素级,使用pooling增加了感受域的大小,但是却使图像的很多细小特征丢失了,这样导致分割出来的图像分辨率很低,于是有学者就提出了基于稀疏卷积核的卷积网络。
那么什么是基于稀疏卷积核的卷积呢?我们用下面的图来简单介绍一下: 
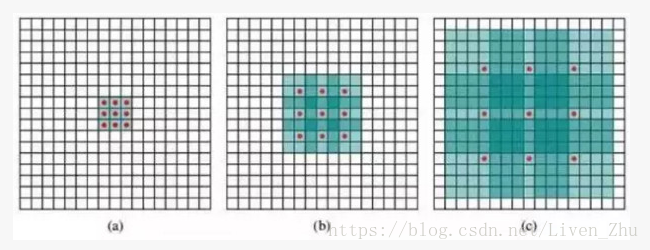
红点表示卷积核的元素,绿色表示感受域,黑线框表示输入图像。
(a) 为原始卷积核计算时覆盖的感受域,(b)和(c) 为当卷积核覆盖的元素间距离增大的情况,不再在连续的空间内去做卷积,跳着做,当这个距离增加的越大时,单次计算覆盖的感受域面积越大。
这种卷积的好处就是,在不增加训练参数的情况下(中间的空格用0填入,不需训练,但是也要参与计算,因此会增加计算量,后文会提到),增大了输出图像中每一个元素的感受域。
Dilated Convolutions的思路就是将用于分类的神经网络(论文里为VGG)的最后两个池化层去掉,用这种基于稀疏卷积核的卷积网络代替。这样,我们在不降低感受域大小的同时,使输出的数据的维度更大,保留了更多的原始图像的细小特征,避免了池化层降低数据维度造成的细小特征丢失的问题。





