
在分布式架构中,断路器模式的作用也是类似的,当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝),直接切断原来的主逻辑调用。但是,在Hystrix中的断路器除了切断主逻辑的功能之外,还有更复杂的逻辑,下面我们来看看它更为深层次的处理逻辑。
我们来说说断路器的工作原理,当我们把服务提供者eureka-client中加入了模拟的时间延迟之后,在服务消费端的服务降级逻辑因为hystrix命令调用依赖服务超时,触发了降级逻辑,但是即使这样,受限于Hystrix超时时间的问题,我们的调用依然很有可能产生堆积。
这个时候断路器就会发挥作用,那么断路器是在什么情况下开始起作用呢?这里涉及到断路器的三个重要参数:快照时间窗、请求总数下限、错误百分比下限。这个参数的作用分别是:
快照时间窗:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
请求总数下限:在快照时间窗内,必须满足请求总数下限才有资格根据熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用此时不足20次,即时所有的请求都超时或其他原因失败,断路器都不会打开。
错误百分比下限:当请求总数在快照时间窗内超过了下限,比如发生了30次调用,如果在这30次调用中,有16次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%下限情况下,这时候就会将断路器打开。
那么当断路器打开之后会发生什么呢?我们先来说说断路器未打开之前,对于之前那个示例的情况就是每个请求都会在当hystrix超时之后返回fallback,每个请求时间延迟就是近似hystrix的超时时间,如果设置为5秒,那么每个请求就都要延迟5秒才会返回。当熔断器在10秒内发现请求总数超过20,并且错误百分比超过50%,这个时候熔断器打开。打开之后,再有请求调用的时候,将不会调用主逻辑,而是直接调用降级逻辑,这个时候就不会等待5秒之后才返回fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
在断路器打开之后,处理逻辑并没有结束,我们的降级逻辑已经被成了主逻辑,那么原来的主逻辑要如何恢复呢?对于这一问题,hystrix也为我们实现了自动恢复功能。当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,在这个时间窗内,降级逻辑是临时的成为主逻辑,当休眠时间窗到期,断路器将进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
通过上面的一系列机制,hystrix的断路器实现了对依赖资源故障的端口、对降级策略的自动切换以及对主逻辑的自动恢复机制。这使得我们的微服务在依赖外部服务或资源的时候得到了非常好的保护,同时对于一些具备降级逻辑的业务需求可以实现自动化的切换与恢复,相比于设置开关由监控和运维来进行切换的传统实现方式显得更为智能和高效。
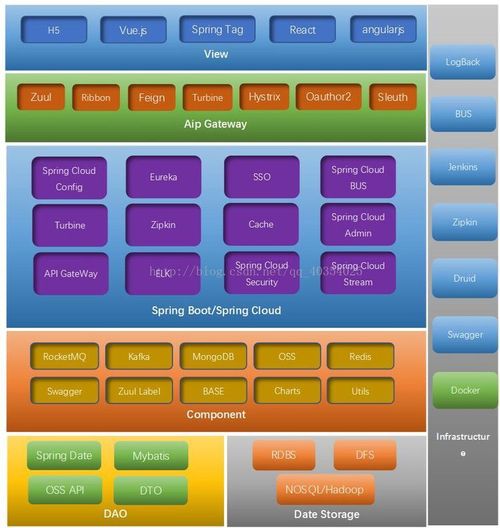
从现在开始,我这边会将近期研发的springcloud微服务云架构的搭建过程和精髓记录下来,帮助更多有兴趣研发spring cloud框架的朋友,希望可以帮助更多的好学者。大家来一起探讨spring cloud架构的搭建过程及如何运用于企业项目。






热门评论
-

qq_IT达人_02018-06-11 0
查看全部评论喜欢文章的可以持续关注更新哦.