
前言
Kafka 最佳实践,涉及
- 典型使用场景
- Kafka 使用的最佳实践
Kafka 典型使用场景
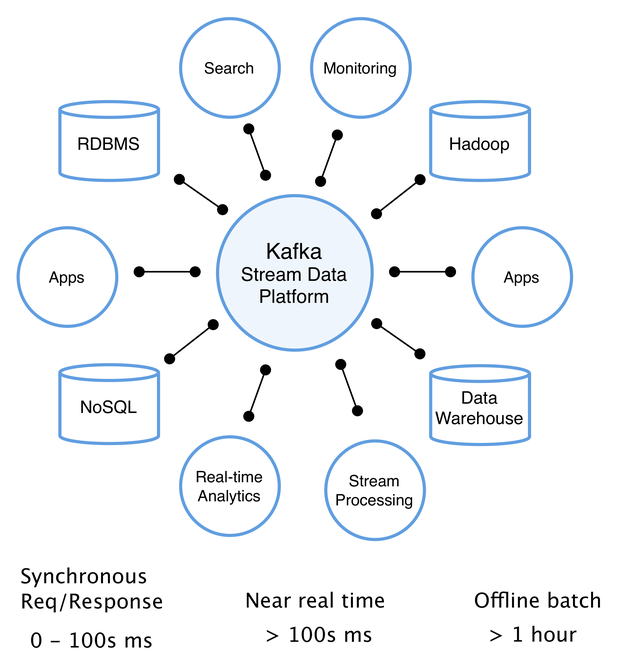
Data Streaming
Kafka 能够对接到 Spark、Flink、Flume 等多个主流的流数据处理技术。利用 Kafka 高吞吐量的特点,客户可以通过 Kafka 建立传输通道,把应用侧的海量数据传输到流数据处理引擎中,数据经过处理分析后,可支持后端大数据分析,AI 模型训练等多种业务。
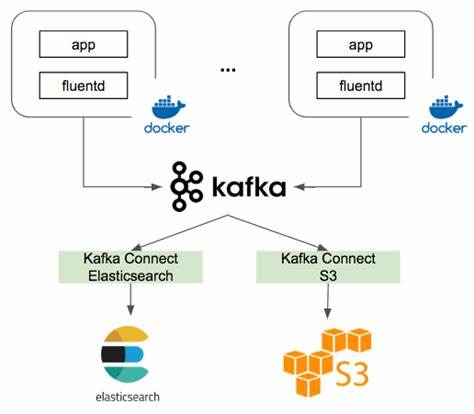
日志平台
Kafka 最常用也是我最熟悉的场景是日志分析系统。典型的实现方式是在客户端部署 日志收集器(如 Fluentd、Filebeat 或者 Logstash 等)进行日志采集,并将数据发送到 Kafka,之后通过后端的 ES 等进行数据运算,再搭建一个展示层如 Kibana 进行统计分析数据的展示。
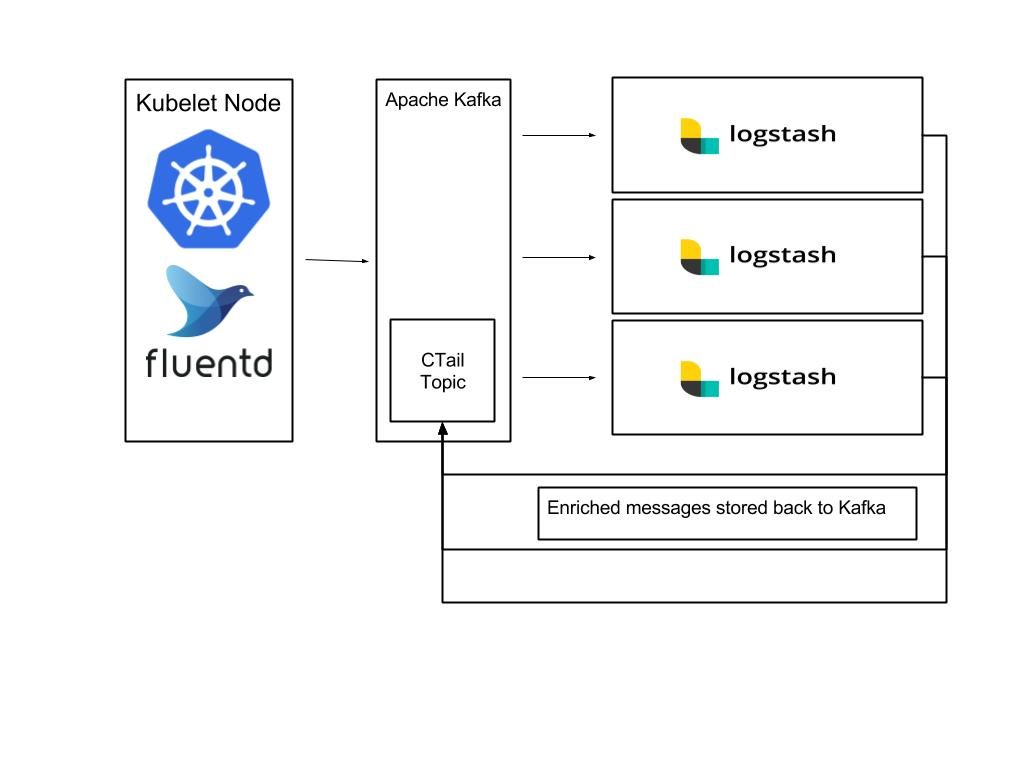
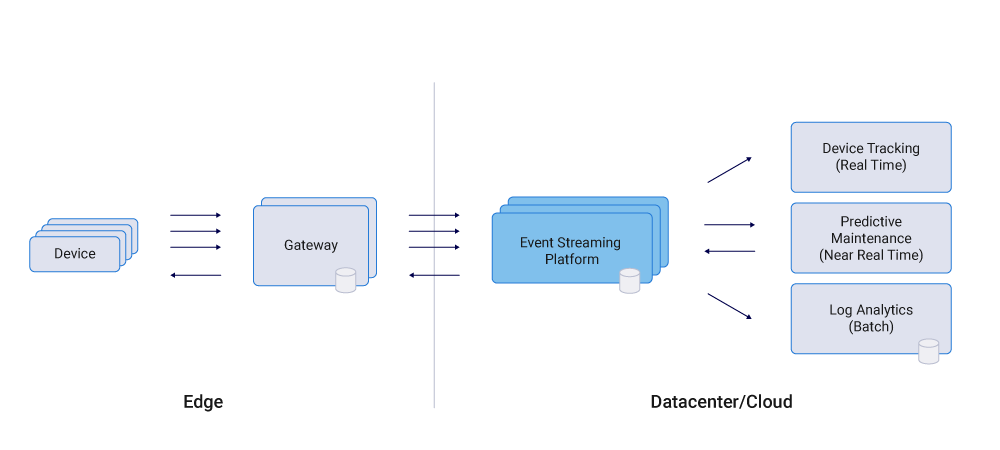
物联网
随着有价值的用例的出现,物联网(IoT)正得到越来越多的关注。然而,一个关键的挑战是整合设备和机器来实时和大规模地处理数据。Apache Kafka®及其周边的生态系统,包括Kafka Connect、Kafka Streams,已经成为集成和处理这类数据集的首选技术。
Kafka 已经被用于许多物联网部署,包括消费者物联网和工业物联网(IIoT)。大多数场景都需要可靠、可伸缩和安全的端到端集成,从而支持实时的双向通信和数据处理。一些具体的用例是:
- 联网的汽车基础设施
- 智能城市和智能家居
- 智能零售和客户360
- 智能制造
具体的实现架构如下图所示:
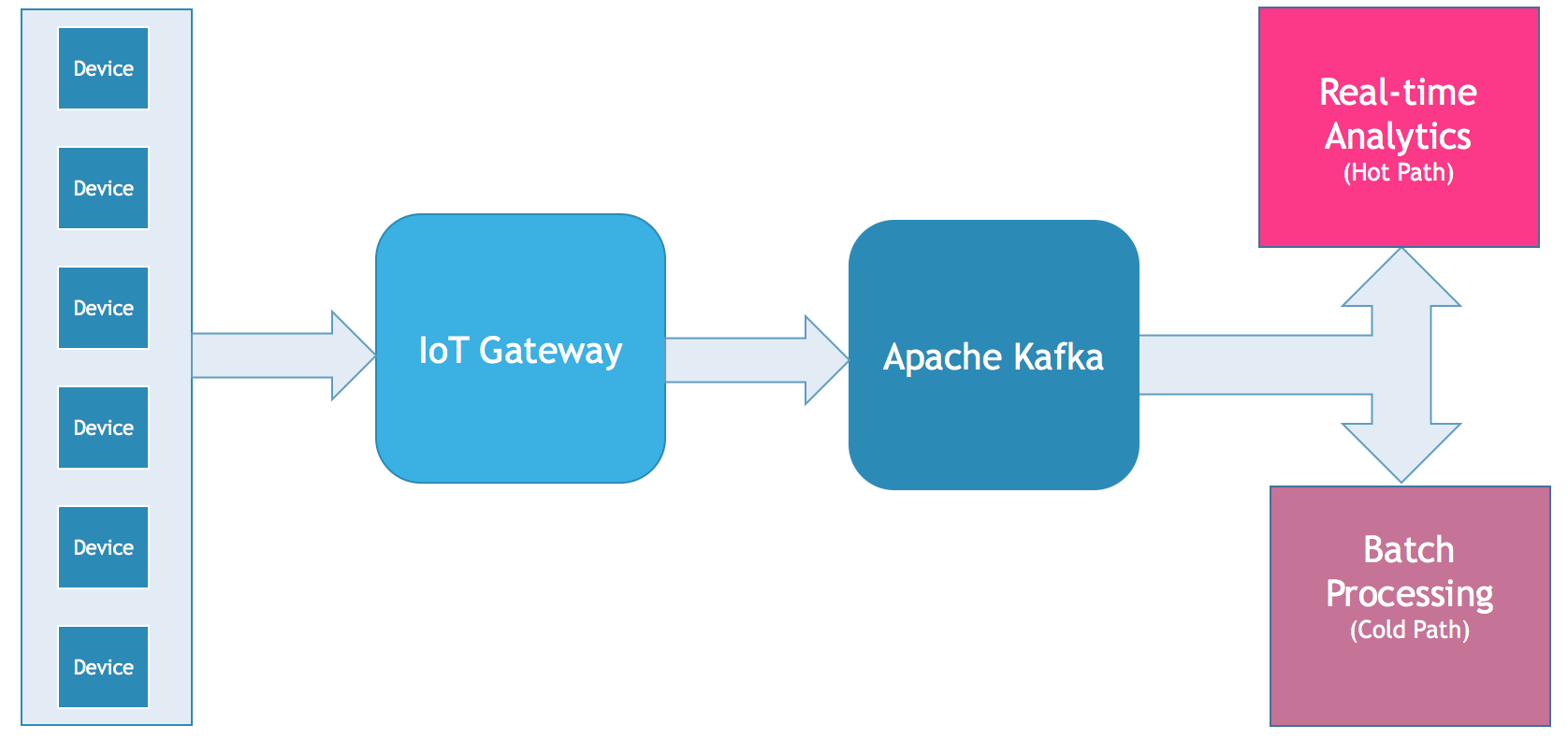
使用的最佳实践
可靠性最佳实践
基于生产者和消费者配置满足不同的可靠性
生产者 At Least Once
生产者需要设置 request.required.acks = ALL,服务端主节点写成功且备节点同步成功才 返回 Response。
消费者 At Least Once
消费者接收消息后,应先进行对应业务操作,随后再进行 commit 标识消息已被处理,通过这种处理方式可以确保一条消息在业务处理失败时,能够重新被消费。注意消费者的 enable.auto.commit 参数需要设置为 False,确保 commit 动作手工控制。
生产者 At Most Once
保障一条消息最多投放一次,需要设置 request.required.acks = 0,同时设置 retries = 0。这里的原理是生产者遇到任何异常都不重试,并且不考虑 broker 是否响应写入成功。
消费者 At Most Once
保障一条消息最多被消费一次,需要消费者在收到消息后先进行 commit 标识消息已被处理,随后再进行对应业务操作。这里的原理是消费者不需要管实际业务的处理结果,拿到消息以后立刻 commit 告诉 broker 消息处理成功。 注意消费者的 enable.auto.commit 参数需要设置为 False,确保 commit 动作手工控制。
生产者 Exactly-once
Kafka 0.11 版本起新增了幂等消息的语义,通过设置 enable.idempotence=true 参数,可以实现单个分区的消息幂等。
如果 Topic 涉及多个分区或者需要多条消息封装成一个事务保障幂等,则需要增加 Transaction 控制,样例如下:
// 开启幂等控制参数
producerProps.put("enbale.idempotence", "true");
// 初始化事务
producer.initTransactions();
// 设置事务 ID
producerProps.put("transactional.id", "id-001");
try{
// 开始事务,并在事务中发送 2 条消息
producer.beginTranscation();
producer.send(record0);
producer.send(record1);
// 提交事务
producer.commitTranscation();
} catch( Exception e ) {
producer.abortTransaction();
producer.close();
}
消费者 Exactly-once
需要设置 isolation.level=read_committed,并设置 enable.auto.commit = false,确保消费者只消费生产者已经提交事务的消息,消费者业务需要确保事务性避免重复处理消息,比如说把消息持久化到数据库,然后向服务端提交 commit。
根据业务场景选用合适的语义
使用 At Least Once 语义支撑可接受少量消息重复的业务
At Least Once 是最常用的语义,可确保消息只多不少的发送和消费,性能和可靠性上有较好的平衡,可以作为默认选用的模式。业务侧也可以通过在消息体加入唯一的业务主键自行保障幂等性,在消费侧确保同一个业务主键的消息只被处理一次。
使用 Exactly Once 语义支撑需要强幂等性业务
Exactly Once 语义一般用绝对不容许重复的关键业务,典型案例是订单和支付相关场景。
使用 At Most Once 语义支撑非关键业务
At Most Once 语义一般用在非关键业务,业务对于消息丢失并不敏感,只需要尽量确保消息成功生产消费即可。典型使用 At Most Once 语义的场景是消息通知,出现少量遗漏消息影响不大,相比之下重复发送通知会造成较坏的用户体验。
性能调优最佳实践
合理设置 Topic 的 partition 数量
以下汇总了通过 partition 调优性能建议考虑的维度,建议您根据理论分析配合压力测试对系统整体性能进行调优。
| 考虑维度 | 说明 |
|---|---|
| 吞吐量 | 增加 partition 的数量可以消息消费的并发度,当系统瓶颈在于消费端,而消费端又可以水平扩展的时候,增加 partition 可以增加系统吞吐量。 在 Kafka 内部每个 Topic 下的每个 partition 都是一个独立的消息处理通道 , 一个 partition 内的消息只能被同时被一个 consumer group 消费,当 consumer group 数量多于partition的数量时,多余的 consumer group 会出现空闲。 |
| 消息顺序 | Kafka 可以保障一个 partition 内的消息顺序性,partition 之间的消息顺序无法保证,增加 partition 的时候需要考虑消息顺序对业务的影响。 |
| 实例 Partition 上限 | Partition 增加会消耗底层更多的内存,IO 和文件句柄等资源。在规划 Topic 的 partition 数量时需要考虑 Kafka 集群能支持的 partition 上限。 |
生产者,消费者与 partition 的关系说明。
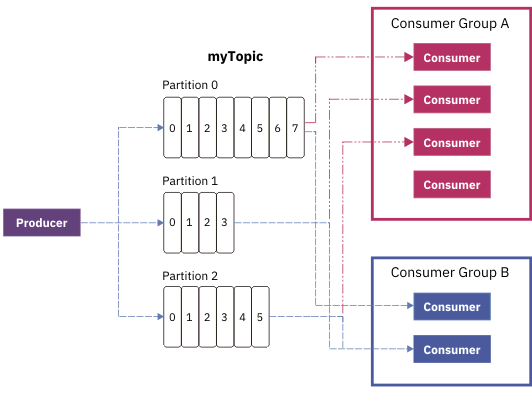
合理设置 batch 大小
如果 Topic 设置了多个分区,生产者发送消息时需要先确认往哪个分区发送。在给同一个分区发送多条消息时,Producer 客户端会将相关消息打包成一个 Batch,批量发送到服务端。一般情况下,小 Batch 会导致 Producer 客户端产生大量请求,造成请求队列在客户端和服务端的排队,从而整体推高了消息发送和消费延迟。
一个合适的 batch 大小,可以减少发送消息时客户端向服务端发起的请求次数,在整体上提高消息发送的吞吐和延迟。
Batch 参数说明如下:
| 参数 | 说明 |
|---|---|
batch.size |
发往每个分区(Partition)的消息缓存量(消息内容的字节数之和,不是条数)。达到设置的数值时,就会触发一次网络请求,然后 Producer 客户端把消息批量发往服务器。 |
linger.ms |
每条消息在缓存中的最长时间。若超过这个时间,Producer 客户端就会忽略 batch.size 的限制,立即把消息发往服务器。 |
buffer.memory |
所有缓存消息的总体大小超过这个数值后,就会触发把消息发往服务器,此时会忽略 batch.size 和 linger.ms 的限制。buffer.memory 的默认数值是 32MB,对于单个 Producer 而言,可以保证足够的性能。 |
Batch 相关参数值的选择并没有通用的方法,建议针对性能敏感的业务场景进行压测调优。
使用粘性分区处理大批量发送
Kafka 生产者与服务端发送消息时有批量发送的机制,只有发送到相同 Partition 的消息才会被放到同一个 Batch 中。在大批量发送场景,如果消息散落到多个 Partition 当中就可能会形成多个小 Batch,导致批量发送机制失效而降低性能。
Kafka 默认选择分区的策略如下
| 场景 | 策略 |
|---|---|
| 消息指定 Key | 对消息的 Key 进行哈希,然后根据哈希结果选择分区,保证相同 Key 的消息会发送到同一个分区。 |
| 消息没有指定 Key | 默认策略是循环使用主题的所有分区,将消息以轮询的方式发送到每一个分区上。 |
从默认机制可见 partition 的选择随机性很强,因此在大批量传输的场景下,推荐设置 partitioner.class参数,指定自定义的分区选择算法实现 粘性分区。
其中一种实现方法是在固定的时间段内使用同一个 partition,过一段时间切换到下一个分区,避免数据散落到多个不同 partition。
通用最佳实践
Kafka 对消息顺序的保障
Kafka 会在同一个 partition 内保障消息顺序,如果 Topic 存在多个 partition 则无法确保全局顺序。如果需要保障全局顺序,则需要控制 partition 数量为 1 个。
对消息设置唯一的 Key
消息队列 Kafka 的消息有 Key(消息标识)和 Value(消息内容)两个字段。为了便于追踪,建议为消息设置一个唯一的 Key。之后可以通过 Key 追踪某消息,打印发送日志和消费日志,了解该消息的生产和消费情况。
合理设置队列的重试策略
分布式环境下,由于网络等原因,消息偶尔会出现发送失败的情况,其原因可能是消息已经发送成功但是 ACK 机制失败或者消息确实没有发送成功。默认的参数能满足大部分场景,但可以根据业务需求,按需设置以下重试参数:
| 参数 | 说明 |
|---|---|
retries |
重试次数,默认值为 3,但对于数据丢失零容忍的应用而言,请考虑设置为 Integer.MAX_VALUE(有效且最大)。 |
retry.backoff.ms |
重试间隔,建议设置为 1000。 |
❗️ 注意:
如果希望实现 At Most Once 语义,重试需要关闭。
接入最佳实践
Spark Streaming 接入 Kafka
Spark Streaming 是 Spark Core 的一个扩展,用于高吞吐且容错地处理持续性的数据,目前支持的外部输入有 Kafka、Flume、HDFS/S3、Kinesis、Twitter 和 TCP socket。
Spark Streaming 将连续数据抽象成 DStream(Discretized Stream),而 DStream 由一系列连续的 RDD(弹性分布式数据集)组成,每个 RDD 是一定时间间隔内产生的数据。使用函数对 DStream 进行处理其实即为对这些 RDD 进行处理。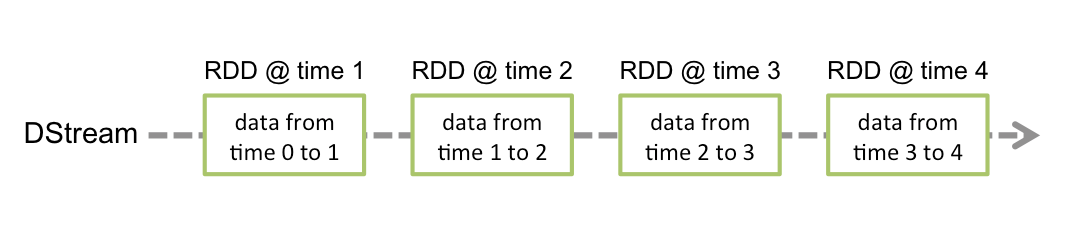
使用 Spark Streaming 作为 Kafka 的数据输入时,可支持 Kafka 稳定版本与实验版本:
| Kafka Version | spark-streaming-kafka-0.8 | spark-streaming-kafka-0.10 |
|---|---|---|
| Broker Version | 0.8.2.1 or higher | 0.10.0 or higher |
| Api Maturity | Deprecated | Stable |
| Language Support | Scala、Java、Python | Scala、Java |
| Receiver DStream | Yes | No |
| Direct DStream | Yes | Yes |
| SSL / TLS Support | No | Yes |
| Offset Commit Api | No | Yes |
| Dynamic Topic Subscription | No | Yes |
本次实践使用 0.10.2.1 版本的 Kafka 依赖。
操作步骤
步骤1:创建 Kafka 集群及 Topic
创建 Kafka 集群的步骤略,再创建一个名为 test 的 Topic。
步骤2:准备服务器环境
Centos6.8 系统
| package | version |
|---|---|
| sbt | 0.13.16 |
| hadoop | 2.7.3 |
| spark | 2.1.0 |
| protobuf | 2.5.0 |
| ssh | CentOS 默认安装 |
| Java | 1.8 |
具体安装步骤略,包括以下步骤:
- 安装 sbt
- 安装 protobuf
- 安装 Hadoop
- 安装 Spark
步骤3:对接 Kafka
向 Kafka 中生产消息
这里使用 0.10.2.1 版本的 Kafka 依赖。
- 在
build.sbt添加依赖:
name := "Producer Example"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.kafka" % "kafka-clients" % "0.10.2.1"
-
配置
producer_example.scala:import java.util.Properties import org.apache.kafka.clients.producer._ object ProducerExample extends App { val props = new Properties() props.put("bootstrap.servers", "172.0.0.1:9092") //实例信息中的内网 IP 与端口 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer") val producer = new KafkaProducer[String, String](props) val TOPIC="test" //指定要生产的 Topic for(i<- 1 to 50){ val record = new ProducerRecord(TOPIC, "key", s"hello $i") //生产 key 是"key",value 是 hello i 的消息 producer.send(record) } val record = new ProducerRecord(TOPIC, "key", "the end "+new java.util.Date) producer.send(record) producer.close() //最后要断开 }
更多有关 ProducerRecord 的用法请参考 ProducerRecord 文档。
从 Kafka 消费消息
DirectStream
- 在
build.sbt添加依赖:
name := "Consumer Example"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "2.1.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "2.1.0"
- 配置
DirectStream_example.scala:
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.OffsetRange
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import collection.JavaConversions._
import Array._
object Kafka {
def main(args: Array[String]) {
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "172.0.0.1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark_stream_test1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> "false"
)
val sparkConf = new SparkConf()
sparkConf.setMaster("local")
sparkConf.setAppName("Kafka")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topics = Array("spark_test")
val offsets : Map[TopicPartition, Long] = Map()
for (i <- 0 until 3){
val tp = new TopicPartition("spark_test", i)
offsets.updated(tp , 0L)
}
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
println("directStream")
stream.foreachRDD{ rdd=>
//输出获得的消息
rdd.foreach{iter =>
val i = iter.value
println(s"${i}")
}
//获得offset
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition { iter =>
val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
}
}
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
RDD
- 配置
build.sbt(配置同上,单击查看)。 - 配置
RDD_example:
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.OffsetRange
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import collection.JavaConversions._
import Array._
object Kafka {
def main(args: Array[String]) {
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "172.0.0.1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark_stream",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val sc = new SparkContext("local", "Kafka", new SparkConf())
val java_kafkaParams : java.util.Map[String, Object] = kafkaParams
//按顺序向 parition 拉取相应 offset 范围的消息,如果拉取不到则阻塞直到超过等待时间或者新生产消息达到拉取的数量
val offsetRanges = Array[OffsetRange](
OffsetRange("spark_test", 0, 0, 5),
OffsetRange("spark_test", 1, 0, 5),
OffsetRange("spark_test", 2, 0, 5)
)
val range = KafkaUtils.createRDD[String, String](
sc,
java_kafkaParams,
offsetRanges,
PreferConsistent
)
range.foreach(rdd=>println(rdd.value))
sc.stop()
}
}
更多 kafkaParams 用法参考 kafkaParams 文档。
Flume接入 Kafka
Apache Flume 是一个分布式、可靠、高可用的日志收集系统,支持各种各样的数据来源(如 HTTP、Log 文件、JMS、监听端口数据等),能将这些数据源的海量日志数据进行高效收集、聚合、移动,最后存储到指定存储系统中(如 Kafka、分布式文件系统、Solr 搜索服务器等)。
Flume 基本结构如下: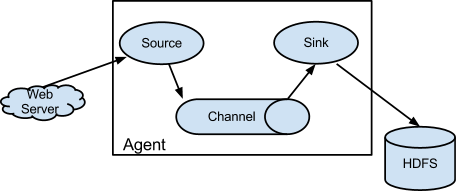
Flume 以 agent 为最小的独立运行单位。一个 agent 就是一个 JVM,单个 agent 由 Source、Sink 和 Channel 三大组件构成。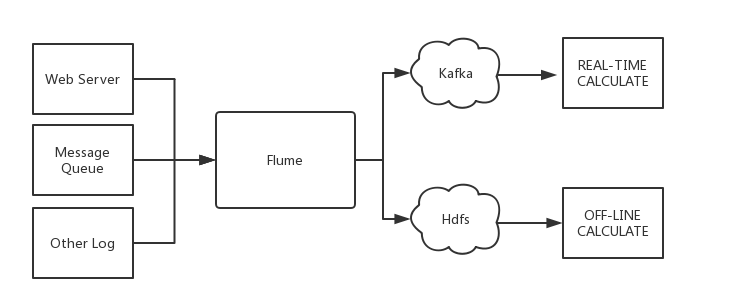
Flume 与 Kafka
把数据存储到 HDFS 或者 HBase 等下游存储模块或者计算模块时需要考虑各种复杂的场景,例如并发写入的量以及系统承载压力、网络延迟等问题。Flume 作为灵活的分布式系统具有多种接口,同时提供可定制化的管道。
在生产处理环节中,当生产与处理速度不一致时,Kafka 可以充当缓存角色。Kafka 拥有 partition 结构以及采用 append 追加数据,使 Kafka 具有优秀的吞吐能力;同时其拥有 replication 结构,使 Kafka 具有很高的容错性。
所以将 Flume 和 Kafka 结合起来,可以满足生产环境中绝大多数要求。
准备工作
- 下载 Apache Flume (1.6.0以上版本兼容 Kafka)
- 下载 Kafka工具包 (0.9.x以上版本,0.8已经不支持)
- 确认 Kafka 的 Source、 Sink 组件已经在 Flume 中。
接入方式
Kafka 可作为 Source 或者 Sink 端对消息进行导入或者导出。
Kafka Source
配置 kafka 作为消息来源,即将自己作为消费者,从 Kafka 中拉取数据传入到指定 Sink 中。主要配置选项如下:
| 配置项 | 说明 |
|---|---|
channels |
自己配置的 Channel |
type |
必须为:org.apache.flume.source.kafka.KafkaSource |
kafka.bootstrap.servers |
Kafka Broker 的服务器地址 |
kafka.consumer.group.id |
作为 Kafka 消费端的 Group ID |
kafka.topics |
Kafka 中数据来源 Topic |
batchSize |
每次写入 Channel 的大小 |
batchDurationMillis |
每次写入最大间隔时间 |
示例:
tier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.batchSize = 5000
tier1.sources.source1.batchDurationMillis = 2000
tier1.sources.source1.kafka.bootstrap.servers = localhost:9092
tier1.sources.source1.kafka.topics = test1, test2
tier1.sources.source1.kafka.consumer.group.id = custom.g.id
更多内容请参考 Apache Flume 官网。
Kafka Sink
配置 Kafka 作为内容接收方,即将自己作为生产者,推到 Kafka Server 中等待后续操作。主要配置选项如下:
| 配置项 | 说明 |
|---|---|
channel |
自己配置的 Channel |
type |
必须为:org.apache.flume.sink.kafka.KafkaSink |
kafka.bootstrap.servers |
Kafka Broker 的服务器 |
kafka.topics |
Kafka 中数据来源 Topic |
kafka.flumeBatchSize |
每次写入的 Bacth 大小 |
kafka.producer.acks |
Kafka 生产者的生产策略 |
示例:
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
更多内容请参考 Apache Flume 官网。
Storm 接入 Kafka
Storm 是一个分布式实时计算框架,能够对数据进行流式处理和提供通用性分布式 RPC 调用,可以实现处理事件亚秒级的延迟,适用于对延迟要求比较高的实时数据处理场景。
Storm 工作原理
在 Storm 的集群中有两种节点,控制节点Master Node和工作节点Worker Node。Master Node上运行Nimbus进程,用于资源分配与状态监控。Worker Node上运行Supervisor进程,监听工作任务,启动executor执行。整个 Storm 集群依赖zookeeper负责公共数据存放、集群状态监听、任务分配等功能。
用户提交给 Storm 的数据处理程序称为topology,它处理的最小消息单位是tuple,一个任意对象的数组。topology由spout和bolt构成,spout是产生tuple的源头,bolt可以订阅任意spout或bolt发出的tuple进行处理。
Storm with Kafka
Storm 可以把 Kafka 作为spout,消费数据进行处理;也可以作为bolt,存放经过处理后的数据提供给其它组件消费。
Centos6.8系统
| package | version |
|---|---|
| maven | 3.5.0 |
| storm | 2.1.0 |
| ssh | 5.3 |
| Java | 1.8 |
前提条件
- 下载并安装 JDK 8。具体操作,请参见 Download JDK 8。
- 下载并安装 Storm,参考 Apache Storm downloads。
- 已创建 Kafka 集群。
操作步骤
步骤1:创建 Topic
步骤2:添加 Maven 依赖
pom.xml 配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>storm</groupId>
<artifactId>storm</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>storm</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.2.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>ExclamationTopology</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
步骤3:生产消息
使用 spout/bolt
topology 代码:
//TopologyKafkaProducerSpout.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.bolt.KafkaBolt;
import org.apache.storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;
import org.apache.storm.kafka.bolt.selector.DefaultTopicSelector;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.utils.Utils;
import java.util.Properties;
public class TopologyKafkaProducerSpout {
//申请的kafka实例ip:port
private final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";
//指定要将消息写入的topic
private final static String TOPIC = "storm_test";
public static void main(String[] args) throws Exception {
//设置producer属性
//函数参考:https://kafka.apache.org/0100/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
//属性参考:http://kafka.apache.org/0102/documentation.html
Properties properties = new Properties();
properties.put("bootstrap.servers", BOOTSTRAP_SERVERS);
properties.put("acks", "1");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建写入kafka的bolt,默认使用fields("key" "message")作为生产消息的key和message,也可以在FieldNameBasedTupleToKafkaMapper()中指定
KafkaBolt kafkaBolt = new KafkaBolt()
.withProducerProperties(properties)
.withTopicSelector(new DefaultTopicSelector(TOPIC))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper());
TopologyBuilder builder = new TopologyBuilder();
//一个顺序生成消息的spout类,输出field是sentence
SerialSentenceSpout spout = new SerialSentenceSpout();
AddMessageKeyBolt bolt = new AddMessageKeyBolt();
builder.setSpout("kafka-spout", spout, 1);
//为tuple加上生产到kafka所需要的fields
builder.setBolt("add-key", bolt, 1).shuffleGrouping("kafka-spout");
//写入kafka
builder.setBolt("sendToKafka", kafkaBolt, 8).shuffleGrouping("add-key");
Config config = new Config();
if (args != null && args.length > 0) {
//集群模式,用于打包jar,并放到storm运行
config.setNumWorkers(1);
StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.createTopology());
} else {
//本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", config, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}
创建一个顺序生成消息的 spout 类:
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
import java.util.UUID;
public class SerialSentenceSpout extends BaseRichSpout {
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
Utils.sleep(1000);
//生产一个UUID字符串发送给下一个组件
spoutOutputCollector.emit(new Values(UUID.randomUUID().toString()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence"));
}
}
为 tuple 加上 key、message 两个字段,当 key 为 null 时,生产的消息均匀分配到各个 partition,指定了 key 后将按照 key 值 hash 到特定 partition 上:
//AddMessageKeyBolt.java
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class AddMessageKeyBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
//取出第一个filed值
String messae = tuple.getString(0);
//System.out.println(messae);
//发送给下一个组件
basicOutputCollector.emit(new Values(null, messae));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//创建发送给下一个组件的schema
outputFieldsDeclarer.declare(new Fields("key", "message"));
}
}
使用 trident
使用 trident 类生成 topology:
//TopologyKafkaProducerTrident.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.trident.TridentKafkaStateFactory;
import org.apache.storm.kafka.trident.TridentKafkaStateUpdater;
import org.apache.storm.kafka.trident.mapper.FieldNameBasedTupleToKafkaMapper;
import org.apache.storm.kafka.trident.selector.DefaultTopicSelector;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Properties;
public class TopologyKafkaProducerTrident {
//申请的kafka实例ip:port
private final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";
//指定要将消息写入的topic
private final static String TOPIC = "storm_test";
public static void main(String[] args) throws Exception {
//设置producer属性
//函数参考:https://kafka.apache.org/0100/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
//属性参考:http://kafka.apache.org/0102/documentation.html
Properties properties = new Properties();
properties.put("bootstrap.servers", BOOTSTRAP_SERVERS);
properties.put("acks", "1");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//设置Trident
TridentKafkaStateFactory stateFactory = new TridentKafkaStateFactory()
.withProducerProperties(properties)
.withKafkaTopicSelector(new DefaultTopicSelector(TOPIC))
//设置使用fields("key", "value")作为消息写入 不像FieldNameBasedTupleToKafkaMapper有默认值
.withTridentTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper("key", "value"));
TridentTopology builder = new TridentTopology();
//一个批量产生句子的spout,输出field为sentence
builder.newStream("kafka-spout", new TridentSerialSentenceSpout(5))
.each(new Fields("sentence"), new AddMessageKey(), new Fields("key", "value"))
.partitionPersist(stateFactory, new Fields("key", "value"), new TridentKafkaStateUpdater(), new Fields());
Config config = new Config();
if (args != null && args.length > 0) {
//集群模式,用于打包jar,并放到storm运行
config.setNumWorkers(1);
StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.build());
} else {
//本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", config, builder.build());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
private static class AddMessageKey extends BaseFunction {
@Override
public void execute(TridentTuple tridentTuple, TridentCollector tridentCollector) {
//取出第一个filed值
String messae = tridentTuple.getString(0);
//System.out.println(messae);
//发送给下一个组件
//tridentCollector.emit(new Values(Integer.toString(messae.hashCode()), messae));
tridentCollector.emit(new Values(null, messae));
}
}
}
创建一个批量生成消息的 spout 类:
//TridentSerialSentenceSpout.java
import org.apache.storm.Config;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.spout.IBatchSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
import java.util.UUID;
public class TridentSerialSentenceSpout implements IBatchSpout {
private final int batchCount;
public TridentSerialSentenceSpout(int batchCount) {
this.batchCount = batchCount;
}
@Override
public void open(Map map, TopologyContext topologyContext) {
}
@Override
public void emitBatch(long l, TridentCollector tridentCollector) {
Utils.sleep(1000);
for(int i = 0; i < batchCount; i++){
tridentCollector.emit(new Values(UUID.randomUUID().toString()));
}
}
@Override
public void ack(long l) {
}
@Override
public void close() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config conf = new Config();
conf.setMaxTaskParallelism(1);
return conf;
}
@Override
public Fields getOutputFields() {
return new Fields("sentence");
}
}
步骤4:消费消息
使用 spout/bolt
//TopologyKafkaConsumerSpout.java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.kafka.spout.*;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.HashMap;
import java.util.Map;
import static org.apache.storm.kafka.spout.FirstPollOffsetStrategy.LATEST;
public class TopologyKafkaConsumerSpout {
//申请的kafka实例ip:port
private final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";
//指定要将消息写入的topic
private final static String TOPIC = "storm_test";
public static void main(String[] args) throws Exception {
//设置重试策略
KafkaSpoutRetryService kafkaSpoutRetryService = new KafkaSpoutRetryExponentialBackoff(
KafkaSpoutRetryExponentialBackoff.TimeInterval.microSeconds(500),
KafkaSpoutRetryExponentialBackoff.TimeInterval.milliSeconds(2),
Integer.MAX_VALUE,
KafkaSpoutRetryExponentialBackoff.TimeInterval.seconds(10)
);
ByTopicRecordTranslator<String, String> trans = new ByTopicRecordTranslator<>(
(r) -> new Values(r.topic(), r.partition(), r.offset(), r.key(), r.value()),
new Fields("topic", "partition", "offset", "key", "value"));
//设置consumer参数
//函数参考http://storm.apache.org/releases/1.1.0/javadocs/org/apache/storm/kafka/spout/KafkaSpoutConfig.Builder.html
//参数参考http://kafka.apache.org/0102/documentation.html
KafkaSpoutConfig spoutConfig = KafkaSpoutConfig.builder(BOOTSTRAP_SERVERS, TOPIC)
.setProp(new HashMap<String, Object>(){{
put(ConsumerConfig.GROUP_ID_CONFIG, "test-group1"); //设置group
put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "50000"); //设置session超时
put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "60000"); //设置请求超时
}})
.setOffsetCommitPeriodMs(10_000) //设置自动确认时间
.setFirstPollOffsetStrategy(LATEST) //设置拉取最新消息
.setRetry(kafkaSpoutRetryService)
.setRecordTranslator(trans)
.build();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(spoutConfig), 1);
builder.setBolt("bolt", new BaseRichBolt(){
private OutputCollector outputCollector;
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.outputCollector = outputCollector;
}
@Override
public void execute(Tuple tuple) {
System.out.println(tuple.getStringByField("value"));
outputCollector.ack(tuple);
}
}, 1).shuffleGrouping("kafka-spout");
Config config = new Config();
config.setMaxSpoutPending(20);
if (args != null && args.length > 0) {
config.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], config, builder.createTopology());
}
else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", config, builder.createTopology());
Utils.sleep(20000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}
使用 trident
//TopologyKafkaConsumerTrident.java
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.spout.ByTopicRecordTranslator;
import org.apache.storm.kafka.spout.trident.KafkaTridentSpoutConfig;
import org.apache.storm.kafka.spout.trident.KafkaTridentSpoutOpaque;
import org.apache.storm.trident.Stream;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.HashMap;
import static org.apache.storm.kafka.spout.FirstPollOffsetStrategy.LATEST;
public class TopologyKafkaConsumerTrident {
//申请的kafka实例ip:port
private final static String BOOTSTRAP_SERVERS = "xx.xx.xx.xx:xxxx";
//指定要将消息写入的topic
private final static String TOPIC = "storm_test";
public static void main(String[] args) throws Exception {
ByTopicRecordTranslator<String, String> trans = new ByTopicRecordTranslator<>(
(r) -> new Values(r.topic(), r.partition(), r.offset(), r.key(), r.value()),
new Fields("topic", "partition", "offset", "key", "value"));
//设置consumer参数
//函数参考http://storm.apache.org/releases/1.1.0/javadocs/org/apache/storm/kafka/spout/KafkaSpoutConfig.Builder.html
//参数参考http://kafka.apache.org/0102/documentation.html
KafkaTridentSpoutConfig spoutConfig = KafkaTridentSpoutConfig.builder(BOOTSTRAP_SERVERS, TOPIC)
.setProp(new HashMap<String, Object>(){{
put(ConsumerConfig.GROUP_ID_CONFIG, "test-group1"); //设置group
put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); //设置自动确认
put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "50000"); //设置session超时
put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, "60000"); //设置请求超时
}})
.setFirstPollOffsetStrategy(LATEST) //设置拉取最新消息
.setRecordTranslator(trans)
.build();
TridentTopology builder = new TridentTopology();
// Stream spoutStream = builder.newStream("spout", new KafkaTridentSpoutTransactional(spoutConfig)); //事务型
Stream spoutStream = builder.newStream("spout", new KafkaTridentSpoutOpaque(spoutConfig));
spoutStream.each(spoutStream.getOutputFields(), new BaseFunction(){
@Override
public void execute(TridentTuple tridentTuple, TridentCollector tridentCollector) {
System.out.println(tridentTuple.getStringByField("value"));
tridentCollector.emit(new Values(tridentTuple.getStringByField("value")));
}
}, new Fields("message"));
Config conf = new Config();
conf.setMaxSpoutPending(20);conf.setNumWorkers(1);
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.build());
}
else {
StormTopology stormTopology = builder.build();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, stormTopology);
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();stormTopology.clear();
}
}
}
步骤5:提交 Storm
使用 mvn package 编译后,可以提交到本地集群进行 debug 测试,也可以提交到正式集群进行运行。
storm jar your_jar_name.jar topology_name
storm jar your_jar_name.jar topology_name tast_name
Logstash 接入 Kafka
Logstash 是一个开源的日志处理工具,可以从多个源头收集数据、过滤收集的数据并对数据进行存储作为其他用途。
Logstash 灵活性强,拥有强大的语法分析功能,插件丰富,支持多种输入和输出源。Logstash 作为水平可伸缩的数据管道,与 Elasticsearch 和 Kibana 配合,在日志收集检索方面功能强大。
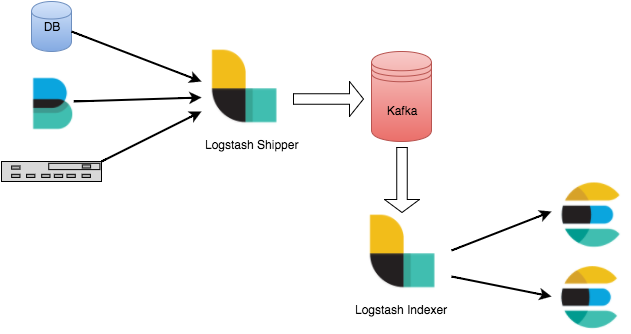
Logstash 工作原理
Logstash 数据处理可以分为三个阶段:inputs → filters → outputs。
- inputs:产生数据来源,例如文件、syslog、redis 和 beats 此类来源。
- filters:修改过滤数据, 在 Logstash 数据管道中属于中间环节,可以根据条件去对事件进行更改。一些常见的过滤器包括:grok、mutate、drop 和 clone 等。
- outputs:将数据传输到其他地方,一个事件可以传输到多个 outputs,当传输完成后这个事件就结束。Elasticsearch 就是最常见的 outputs。
同时 Logstash 支持编码解码,可以在 inputs 和 outputs 端指定格式。
Logstash 接入 Kafka 的优势
- 可以异步处理数据:防止突发流量。
- 解耦:当 Elasticsearch 异常的时候不会影响上游工作。
❗️ 注意:
Logstash 过滤消耗资源,如果部署在生产 server 上会影响其性能。
操作步骤
准备工作
- 下载并安装 Logstash,参考 Download Logstash。
- 下载并安装 JDK 8,参考 Download JDK 8。
- 已创建 Kafka 集群。
步骤1:创建 Topic
创建一个名为 logstash_test的 Topic。
步骤2:接入 Kafka
作为 inputs 接入
-
执行
bin/logstash-plugin list,查看已经支持的插件是否含有logstash-input-kafka。
-
在
.bin/目录下编写配置文件input.conf。
此处将标准输出作为数据终点,将 Kafka 作为数据来源。input { kafka { bootstrap_servers => "xx.xx.xx.xx:xxxx" // kafka 实例接入地址 group_id => "logstash_group" // kafka groupid 名称 topics => ["logstash_test"] // kafka topic 名称 consumer_threads => 3 // 消费线程数,一般与 kafka 分区数一致 auto_offset_reset => "earliest" } } output { stdout{codec=>rubydebug} } -
执行以下命令启动 Logstash,进行消息消费。
./logstash -f input.conf会看到刚才 Topic 中的数据被消费出来。

作为 outputs 接入
-
执行
bin/logstash-plugin list,查看已经支持的插件是否含有logstash-output-kafka。 -
在.
bin/目录下编写配置文件output.conf。
此处将标准输入作为数据来源,将 Kafka 作为数据目的地。input { input { stdin{} } } output { kafka { bootstrap_servers => "xx.xx.xx.xx:xxxx" // ckafka 实例接入地址 topic_id => "logstash_test" // ckafka topic 名称 } } -
执行如下命令启动 Logstash,向创建的 Topic 发送消息。
./logstash -f output.conf -
启动 Kafka 消费者,检验上一步的生产数据。
./kafka-console-consumer.sh --bootstrap-server 172.0.0.1:9092 --topic logstash_test --from-begging --new-consumer
Filebeats 接入 Kafka
Beats 平台 集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向目标发送采集数据。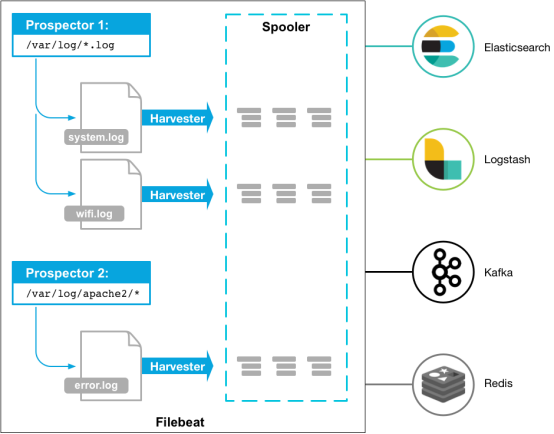
Beats 有多种采集器,您可以根据自身的需求下载对应的采集器。本文以 Filebeat(轻量型日志采集器)为例,向您介绍 Filebeat 接入 Kafka 的操作指方法,及接入后常见问题的解决方法。
前提条件
- 下载并安装 Filebeat(参见 Download Filebeat)
- 下载并安装JDK 8(参见 Download JDK 8)
- 已 创建 Kafka 集群
操作步骤
步骤1:创建 Topic
创建一个名为 test的 Topic。
步骤2:准备配置文件
进入 Filebeat 的安装目录,创建配置监控文件 filebeat.yml。
#======= Filebeat prospectors ==========
filebeat.prospectors:
- input_type: log
# 此处为监听文件路径
paths:
- /var/log/messages
#======= Outputs =========
#------------------ kafka -------------------------------------
output.kafka:
version:0.10.2 // 根据不同 Kafka 集群版本配置
# 设置为Kafka实例的接入地址
hosts: ["xx.xx.xx.xx:xxxx"]
# 设置目标topic的名称
topic: 'test'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: none
max_message_bytes: 1000000
# SASL 需要配置下列信息,如果不需要则下面两个选项可不配置
username: "yourinstance#yourusername" //username 需要拼接实例ID和用户名
password: "yourpassword"
步骤4:Filebeat 发送消息
-
执行如下命令启动客户端。
sudo ./filebeat -e -c filebeat.yml -
为监控文件增加数据(示例为写入监听的 testlog 文件)。
echo ckafka1 >> testlog echo ckafka2 >> testlog echo ckafka3 >> testlog -
开启 Consumer 消费对应的 Topic,获得以下数据。
{"@timestamp":"2017-09-29T10:01:27.936Z","beat":{"hostname":"10.193.9.26","name":"10.193.9.26","version":"5.6.2"},"input_type":"log","message":"ckafka1","offset":500,"source":"/data/ryanyyang/hcmq/beats/filebeat-5.6.2-linux-x86_64/testlog","type":"log"} {"@timestamp":"2017-09-29T10:01:30.936Z","beat":{"hostname":"10.193.9.26","name":"10.193.9.26","version":"5.6.2"},"input_type":"log","message":"ckafka2","offset":508,"source":"/data/ryanyyang/hcmq/beats/filebeat-5.6.2-linux-x86_64/testlog","type":"log"} {"@timestamp":"2017-09-29T10:01:33.937Z","beat":{"hostname":"10.193.9.26","name":"10.193.9.26","version":"5.6.2"},"input_type":"log","message":"ckafka3","offset":516,"source":"/data/ryanyyang/hcmq/beats/filebeat-5.6.2-linux-x86_64/testlog","type":"log"}
SASL/PLAINTEXT 模式
如果您需要进行 SALS/PLAINTEXT 配置,则需要配置用户名与密码。 在 Kafka 配置区域新增加 username 和 password 配置即可。
参考链接
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.





