
背景
内涵近段时间迁移了部分API代码到Golang,主要是为了使用Golang中方便的goroutine。但是开发中很多冗余代码需要重复开发(缺少一个组件能够收敛各种RPC调用,复用代码,减少开发量),同时,又不希望组件使用过多的黑魔法,导致结构复杂,开发维护麻烦。
要求
综上,希望开发一个组件: * 能够收敛各种RPC调用,复用代码,减少开发量 * 能够利用Golang的goroutine优势,加快数据获取 * 不要使用太多黑魔法,导致结构复杂难于维护
假设场景
需要实现一个接口,接受一个段子的Content_id,返回如下数据: * 数据a. 段子基本内容Content 调用获取Conent_Info接口 * 数据b. 段子的作者信息User 调用获取User_Info接口 * 数据c. 段子的评论信息Comment 调用获取Comment_Info接口
一、从RPC调用开始
假设场景在golang中的调用顺序就是:
根据段子ID(Content_id),并发调用数据a(基本内容)和数据c(评论信息)
根据a(基本内容)中的作者userid调用数据b(作者用户信息userinfo)
(图1-1)
单独看来,这些操作也没什么,但是我们看看完成这个步骤需要的代码:
ContentTask = NewContentInfoTask(id=123) CommentTask = NewCommentsListTask(ContentId=123) ParallelExec(ContentTask, CommentTask) // 并行调用两个任务 // 判断结果是否正确,一堆代码 user_id = ContentTask.Response.User_id //获取作者ID UserResp = NewUserTask(user_id).Load() // 再获取作者信息 // 判断结果,一堆代码 // 用上面获取的数据打包数据
非常的冗余,而且麻烦在于,这种步骤基本每个接口都会需要进行,完全无法重用。 一旦数据有区别,需要多一点或者少一点数据,又需要重新写一个Load过程。很多Copy的代码。
问题一:那我们能否减少这种重复书写的代码?
二、基本的Dao功能
自然的,我们会想到将RPC调用都收敛到自己所属的实体(Dao),并建立Dao之间的关联关系,每个RPC对应一个方法(在方法中将数据填充到自身),即(图2-1):

此时,我们获取数据只需要如下代码:
content = NewContentDao(id=123) // 段子信息 comments = NewCommentList(ContentId=123) // 段子评论信息 // 第一层Load: 获取Content和comments的信息 ParallelExec(content.Content_Info(), comments.Comment_Info()) # 并行两个任务 // 第二层Load: 获取user的属性 user = NewUser(id=content.UserId) user.User_Info() // 使用上面对象的属性,进行数据的打包。
python中可以将方法作为property,即使用某个属性的时候,才进行需要的RPC调用,使用更加的方便。但是也就不方便进行并行处理
显然的,此时代码已经省略了很多:将RPC调用收敛到了一个实体中。 更进一步,我们可以利用已经包含在了Dao关联关系之中的相互关系:即,获取用户和评论信息,是可以通过Dao来调用的。
content = NewContentDao(id=123) ParallelExec(content.Content_Info(),content.Comments.Comment_Info()) // 并发获取content基本信息和Comment信息 content.User.User_Info() //获取作者信息
至此,已经实现了基本的Dao功能。即:
收敛所有RPC、DB、Cache等跨服务调用
并建立他们之间的关联关系
收敛冗余代码,只要实现一套Dao(收敛属于该实体的所有调用)
此时要实现新一个接口将是相对轻松的工作!只需要聚合各种Dao之后打包数据即可。
但是此时,代码就会是一个套路:加载第一层、加载第二层、、、、加载第N层。加载完所有数据之后,再进行打包。
问题二:那么我们能否让这种套路自动化?
三、自动构建调用树
再次回顾我们的Dao的关联关系对应的对象图,可以明显的看到是一个树结构(全树) (图3-1):
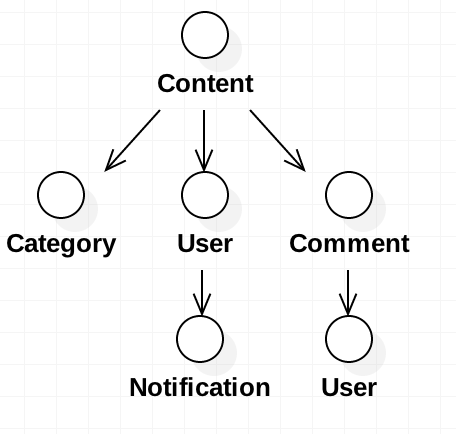
而我们需要的是这些属性:Content、User、Comment,即树中的某些节点 (图3-2):
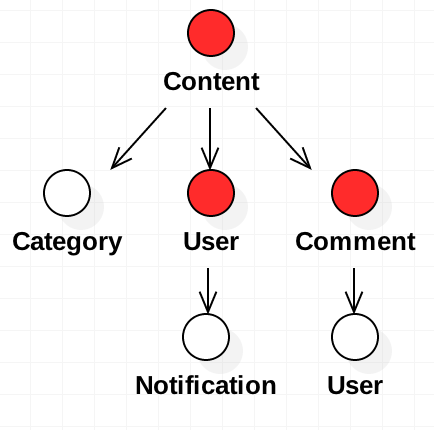
所以,我们需要有某个组件(称之为Loader组件),使用DAO的调用方提供需要的属性(即上图中的红色部分),该组件将上图3-2和图3-1的全树进行match,一旦需要,则进行RPC调用,将结果数据放到Dao对象中。最终返回一个已经Load好数据的Dao的struct就可以啦!
问题三:
Dao之间有一些复杂的依赖关系,同时一个Dao内的属性又有依赖关系, 这个组件如何组织调用和对应的先后关系?
如何实现调用中的并发获取?
如何(何种形式)告诉这个组件你需要的数据的路径?
四、自动并发加载:
问题1:
组件如何组织调用和对应的先后关系?
在上一节自动构建调用树中我们已经知道Dao之间的关系。现在我们再将Dao拆开,以RPC调用为最小的单元,再来看下这个树(图4-1):
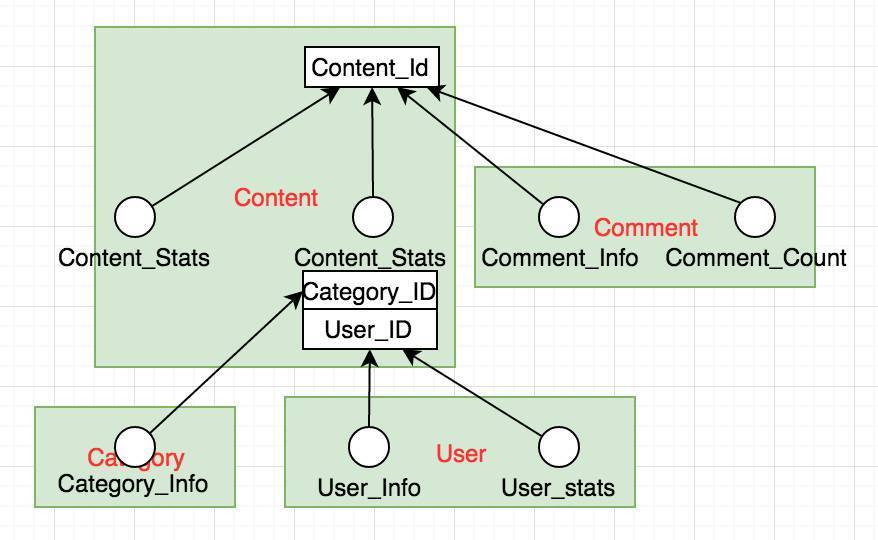
白圆圈是每个需要RPC调用的代码块,白方块表示属性(部分表示由RPC调用获取到的属性)。
有没有发现什么?
我们单独拿Content来看,他的属性结构如下(图4-2):

再结合图4-1,可以看到,
一些基本属性如Text、UserId、DiggCount仅仅依赖于主键ID;
另外一些属性如:User、Category等,是依赖于1中的基本属性
此时,将一个DAO中的所有属性分成两种:
Basic:依赖于主键ID,即获取这个属性,仅仅依赖于主键。
Sub:依赖于Basic中的某个属性。
如此划分之后,就可以将Dao拆分成两层调用: 第一层Basic调用基本的;完成之后,Sub依赖的属性都具备了,再调用第二层;
至此该Dao的数据加载完成
划分之后,每个DAO的属性如下(图4-3):
如content则存在一个属性和RPC调用关联关系的map:
// 基本属性和RPC调用方法的映射
BASIC_LOADER_MAP = map[string]Loader{
"basic": {Loader: duanziBasicLoader}, // 获取段子的基本属性(依赖于content_id)
"commentStats": {Loader: commentstatsLoader}, // content的评论数据(依赖于content_id)
}
// Sub属性和RPC调用方法的映射
SUB_LOADER_MAP = map[string]Loader{
"User": {Loader: userLoader,}, // 作者信息(依赖于段子信息中的user_id)
}再建立他们之间的联系(图4-4):

至于下层的Dao的调用,则交给下层的Dao来完成,当前层不再介入,此时,我们的调用结构如下(图4-5):

问题2:
如何实现调用中的并发获取?
我们只需要在调用过程中,将同一个层的Basic或者Sub进行并发调用,就可以了,如(图4-6):

即调用顺序如下(每行表示一个RPC调用,并列的行,并行调用):
1\. 设置Content_Id 2\. 开启Goroutine,并发调用Content的Basic层: * a. RPC获取段子基本信息 * b. RPC获取段子Stats * c. 评论Dao, * 1\. 评论Dao调用自身的Basic层 * a. RPC获取评论基本信息 * d. RPC获取评论相关数据stats 3\. 开启Goroutine,并发调用Content的Sub层: * a. CategoryDao * 2\. Basic层: * a. RPC获取Category信息 * b. UserDao * 1\. Basic层: * a. RPC获取用户基本信息 * 2\. Sub层: * .......
问题3:
最后,我们讨论一下问题三的3:如何告诉这个组件你需要的数据的路径?
其实上面的结构梳理清楚了,那么这个问题就好解决了, 我们无非是提供一个你需要的属性的树,让Dao的结构一层层遍历的过程中,将该树传递下去, 如果match,则mark一下这个RPC会进行调用,mark完成当前Dao的basic层和sub层之后,统一并发调用。 而下一级的Dao的Load则在sub层中做,下一级的Dao又去match提供的树,构建自身的Load任务。如此一层层进行下去,直到Load完所有你需要的属性!
比如你需要Contentinfo和Content中的UserInfo和Content中的Comment,就构造一棵树:
Content_Info User_Info \ Comment_Info
然后传递给该组件,他就能够只Load这几个需要的属性,match和构造以及并发调用的过程如下:
// paramLoaderMap、subLoaderMap是basic和sub属性和Rpc调用关系的map
func DaoLoad(needParamsTree, daoList, paramLoaderMap, subLoaderMap) error {
var basicParamTaskList // Basic打包任务列表
var subDaoTaskList // Sub打包任务列表
// 遍历用户需要的属性,构造当前Dao的Basic和Sub任务结构
for _, sonTree := range needParamsTree {
if basic属性需要Load {
// put to basicParamTaskList
} else if sub属性需要load{
// put to subDaoTaskList
}
}
// 并发执行Basic Load
// 并发执行Sub Load
}优化:
组件来帮助调用方建立needParamsTree,只需要提供几个个字符串,:
[]string{"Content_Info", "Content.User_Info", "Content.Comment_Info"},组件帮你填充Sub依赖的基本属性,Sub属性依赖的Basic属性是确定的,可以交给Dao自己来填充,此部分也可以省略。
此时我们的代码如下:
dao = LoadDao([1,2,3], []string{"User_Info", "Comment_Info"}).Exec()
// 用dao去打包数据吧!多个不同类型的Dao的Load就多构建几个并行执行Exec即可
此时该组件减少了很多冗余的代码,而且能够并发加快Load数据的过程。以后还能够方便的使用!
问题:
问:以上面的模型来说,这样显然会带来更多的rpc调用(比如链条a.获取
段子的用户信息;链条b.段子的评论的用户信息无法进行聚合之后再调用):答:开始考虑过合并减少RPC调用,但是这种方式有时候是有损的,即可能链条a更长,为了等待链条b拿到用户ID,导致了总耗时的增加。所以选择了两者区分开。
此时就耗时来说,相对最开始的模型并没有增长,都是取最长路径。无非是相同的RPC调用会增多,但是这个是可以容忍的。因为:
使用Go,消耗有限,只是多开了一些goruntine而已;
根据业务的情况来看,这种增长有限,在忍受范围内;
结论:
至此,整个Go_Dao的Load完成(version 1.0),再回到最开始的背景要求,算是完成基本的要求:
该组件能够实现基本的Dao的功能(收敛所有RPC、DB、Cache等跨服务调用,并建立他们之间的关联关系,收敛冗余代码,减少开发者的工作量)
同时能够利用Golang的并行优势加快数据获取
没有使用Golang中的一些相对复杂的特性(比如反射等)
就功能来说,这个组件最好的使用场景在于需要很多跨服务调用的地方,能够极大的节省开发量。当前还只是第一个版本,还需要持续的迭代。
原文地址:https://techblog.toutiao.com/2018/05/23/dai-ding-nei-han-golang-dao/





