
大家好,我是皮皮。
一、前言
前几天在Python铂金交流群【红色基因代代传】问了一个Python网络爬虫的问题,提问截图如下:
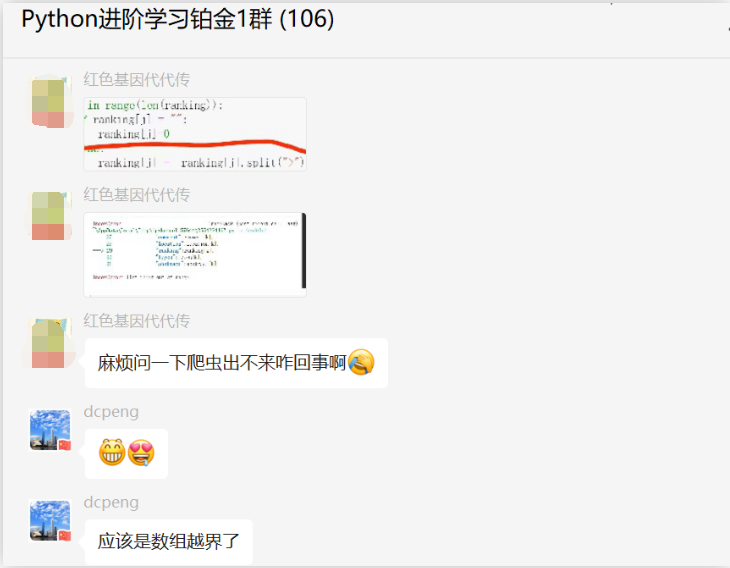
代码截图如下:
报错截图如下:

要么就是原始网页没那么多数据,要么就是你自己取到的数据没那么多,有的有排名,有的没有,可以考虑加个try异常处理。
首先这里有个基础的报错,判断字符串是否相等的话,需要使用双引号。
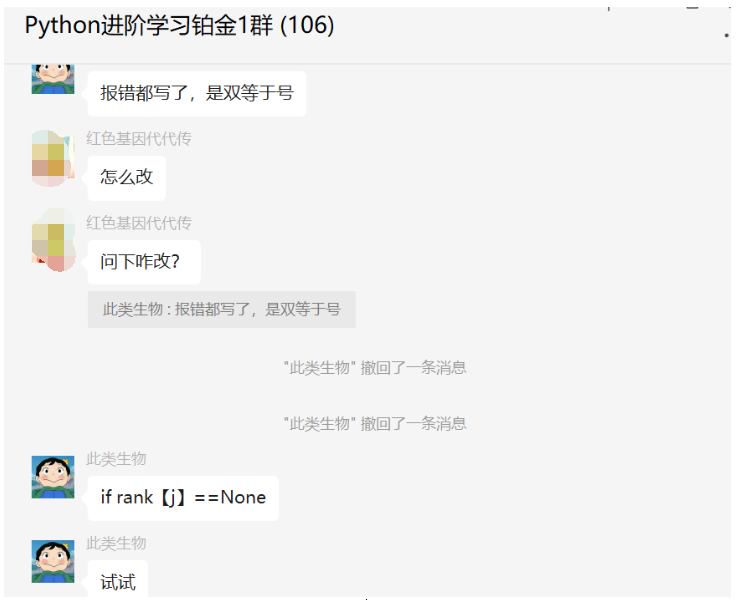
二、实现过程
这里很多大佬其实给了思路,针对这个问题,方法也还是蛮多的。
这里【甯同学】给了一个代码,如下所示:
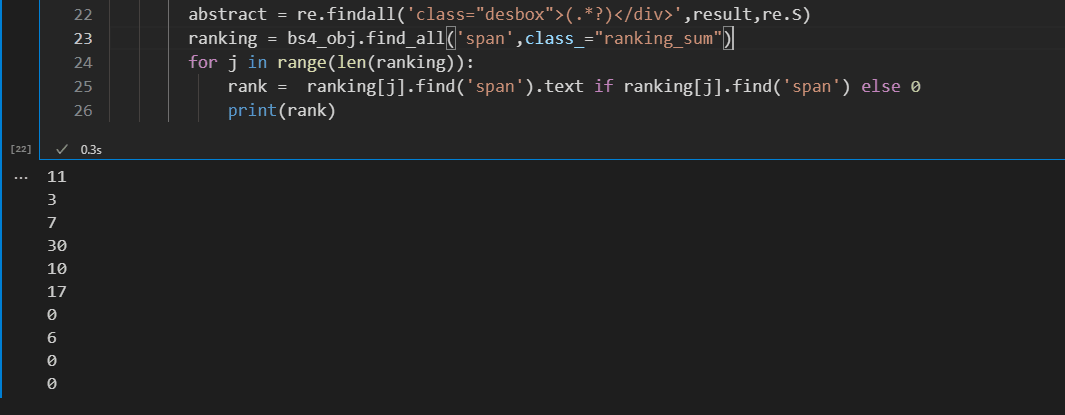
核心代码如下:
bs4_obj = BeautifulSoup(result, 'lxml')
ranking = bs4_obj.find_all('span', class_="ranking_sum")
for j in range(len(ranking)):
rank = ranking[j].find('span').text if ranking[j].find('span') else 0
print(rank)
顺利地解决了粉丝的问题。
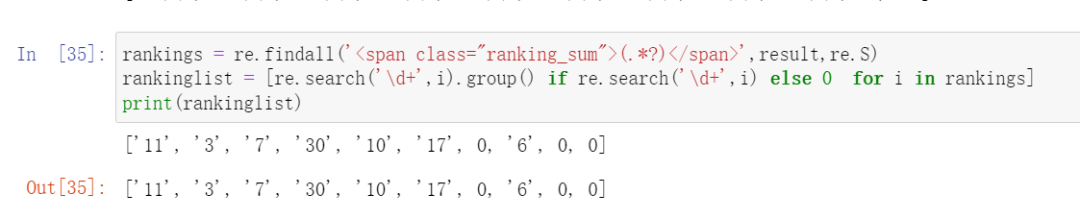
这里粉丝和【甯同学】后来还给了一个代码,在粉丝代码的基础上进行了修改,也可以得到预期的结果,代码如下图所示:
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫处理的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【红色基因代代传】提问,感谢【dcpeng】、【此类生物】、【猫药师Kelly】、【甯同学】给出的思路和代码解析,感谢【dcpeng】、【冫马讠成】等人参与学习交流。





