①课程介绍
课程名称:Python3入门机器学习 经典算法与应用 入行人工智能
课程章节:8-7;8-8
主讲老师:liuyubobobo
内容导读
- 第一部分 岭回归介绍
- 第二部分 岭回归应用场景
- 第三部分 岭回归使用示例
②课程详细
第一部分 岭回归介绍
(Ridge Regression岭回归)模型正则化方式之一
正则化的目的:限制特征系数sita的大小
1 与theta0无关,因为它是截距,与特征无关
2 alpha是超参数,代表系数项占的比例
a越大 特征系数就越小。极端情况下a等于正无穷,则sita必须全为0才可以使J(sita)尽可能的小
加入模型正则化,目标:使得mse + 系数平方和 尽可能小
第二部分 岭回归应用场景
在数据过拟合地情况下,可以使用岭回归的C函数来进行正则化,也就是将某些theta的值进行影响最小化。
第三部分 岭回归使用示例
导入包
import numpy as np
import matplotlib.pyplot as plt
创建数据
np.random.seed(666)
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x +3 +np.random.normal(0, 1, size=100)
数据可视化
plt.scatter(x, y)
plt.show()

封装管道,使用多项式回归来达到过拟合情况,以便于展示岭回归的威力。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
def PolynomialRegression(degree):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler',StandardScaler()),
('lin_reg',LinearRegression())
])
分割数据集,用于展示数据准确率
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=666)
创建对象
from sklearn.metrics import mean_squared_error
poly_reg = PolynomialRegression(degree=30)
poly_reg.fit(X_train, y_train)
y_test_predict = poly_reg.predict(X_test)
#mean_squared_error(y_test, y_test_predict)
定义可视化函数
def plot_model(model):
x_plot = np.linspace(-3,3,100).reshape(100,1)
y_plot = model.predict(x_plot)
plt.scatter(x,y)
plt.plot(x_plot, y_plot, color='r')
plt.axis([-4,4,-1,7])
plt.show()
plot_model(poly_reg)

封装零函数的包,
from sklearn.linear_model import Ridge
def RidgeRegression(degree, alpha):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler',StandardScaler()),
('ridge_reg',Ridge(alpha=alpha))
])
创建对象,定义很小的alpha,查看拟合的情况
redge1_reg = RidgeRegression(30, 0.000001)
redge1_reg.fit(X_train, y_train)
y1_predict = redge1_reg.predict(X_test)
mean_squared_error(y_test,y1_predict)
可视化拟合结果
plot_model(redge1_reg)

创建对象,定义较小的alpha,查看拟合的情况
redge2_reg = RidgeRegression(30, 0.01)
redge2_reg.fit(X_train, y_train)
y2_predict = redge2_reg.predict(X_test)
mean_squared_error(y_test,y2_predict)
plot_model(redge2_reg)

创建对象,定义较大的alpha,查看拟合的情况
redge4_reg = RidgeRegression(30, 100)
redge4_reg.fit(X_train, y_train)
y4_predict = redge4_reg.predict(X_test)
mean_squared_error(y_test,y4_predict)
plot_model(redge4_reg)

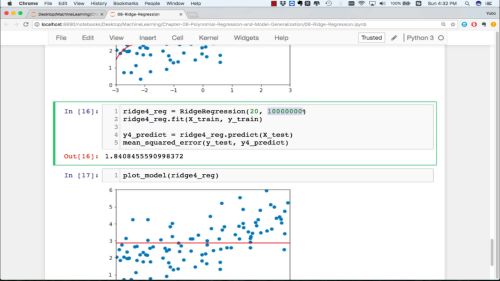
创建对象,定义很大的alpha,查看拟合的情况
redge5_reg = RidgeRegression(30, 1000000)
redge5_reg.fit(X_train, y_train)
y5_predict = redge4_reg.predict(X_test)
mean_squared_error(y_test,y5_predict)
plot_model(redge5_reg)

③课程思考
- 岭回归通过调解alpha的值能很明显地扭转过拟合的趋势,作为一个超参数,是非常合格的,
- 线性回归或者多项式回归,在发生过拟合的情况下,可以优先考虑使用岭回归来进行调解。
④课程截图