即大数据(large datasets)下的机器学习。
large scale下的机器学习一个显著问题就是computationally expensive。最简单的解决办法就是采样(比如取10,000个样本),但是这个办法有风险,我们需要用bias-variance tradeoff来探查是否能用采样的方法(比如以采样大小为X轴,画出CV 数据集和训练集的cost function J, 观察趋势判断)。
1. Gradient Descent with Large Datasets
1.1 Batch Gradient Descent
当我们的gradient descent遍历训练集所有数据时(及时数据量巨大),我们称之为batch gradient descent.
1.2 随机梯度下降(Stochastic Gradient Descent)
随机梯度下降的思想类比batch梯度下降,非常好理解。从下图公式对比可知,batch梯度下降就相当于一直憋憋憋,憋一个大招KO敌人(在这之前敌人的HP一直不变);随机梯度下降相当于一直光速平A敌人,直到敌人HP为0(或者说你认为敌人HP为0了)(敌人的HP一直在掉,流行的话就是“进一步有进一步的欢喜??啥的,记不清了”)。

也因为两者的本质相同,但是作用原理不同,我们可以理解为大招KO更稳健一些,平A获胜还是有风险的。如下图所示,左边batch可以较好地找到最优解;而stochastic可能会走很多弯路,看起来不那么make sense,而且很可能最终θ只能落在一个范围里(如右图红色部分)。

对于如何判断随机梯度下降收敛了,我们依然需要以迭代次数为横坐标对cost function画图。这里的cost function因为只用到了单个例子,所以不会一直是减小的。如果cost function只增不减,说明代码有问题或者学习率太大,需要调节。如果cost function十分颠簸不好判断收敛,我们需要增加使用的样本数量重新画图观察。
这里有一个设置学习率的小技巧,理论上学习率一直是一个常数,但是它是可变的。我们都知道,学习率越小,取得的值越接近最优解,但是耗时也越长。我们可以将学习率与迭代次数的反比建立关系,从而使学习率有一定规律的以微小变化减少,这样,越接近最优解,学习率越小,得到的结果越好。
1.3 Mini-Batch Gradient Descent
相比stochastic,Mini-batch可以更快。这里我们需要选择一个mini-batch的值b。b的范围一般在[2,100], 吴恩达男神通常用10~~Mini-Batch用到了系统抽样的思想。在传统的梯度下降里,cost function需要遍历每一个数据然后求和,梯度下降需要等待求和完毕才能进行;在随机梯度下降里,cost function只包含一个数据,每一次梯度下降的迭代只用到一个数据;在Mini-batch中,cost function依然只包含一个数据,但是每一次梯度下降都会用到b个数据。如下图示例,取m=1000, b=10. 那么使用系统抽样思想,每一次梯度下降都使用到各组里面编号为某一数值的b个样本。

mini-batch比传统梯度下降快很好理解——他只用了一部分。那么为什么mini-batch会比随机梯度下降快呢?——因为向量化,长度为b的向量和长度为1的向量计算起来并没有什么太多消耗,而且我们能够使用更多数据更快速找到最优解。
2. Online Learning Algorithms
多用于搜索引擎和询价系统,一次只需要这一个人的数据,用完即扔。很有意思,但是这门课没有细讲,感觉回头可以自己补一下。
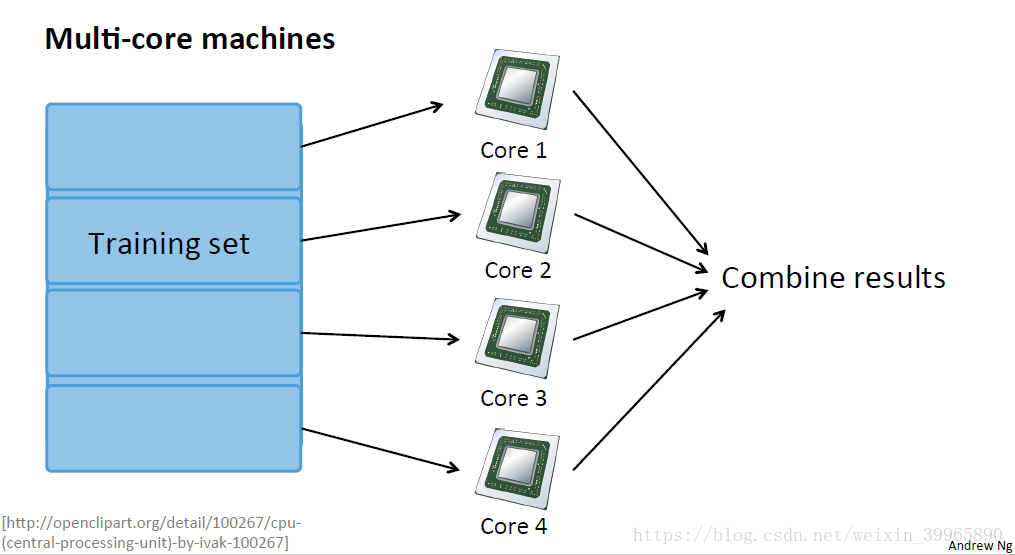
3. Map-Reduce and Data Parallelism
就是简单的分布式系统的思想。先使用Map把任务分配出去,然后用Reduce将得到的结果合并起来。这里的核心问题就是你的算法的核心部分能不能用某种求和的形式表现(能不能把任务分配出去)。