
课程名称:构建数据分析工程师能力模型,实战八大企业级项目
课程章节:2-5 数据探索工具-Pandas
课程讲师:fish
课程内容:
Pandas的功能概述:
- Pandas是构造于Numpy基础之上,兼具Numpy高性能的数组计算功能以及电子表格和关系型数据的灵活处理能力。
- Pandas提供了复杂精细的索引功能,可以更为便捷的完成索引、切片、组合以及选取数字子集等数据处理的操作。
- Pandas包含了Services序列和DataFrame(数据框或数据帧)两种最为常用的数据结构类型,使得Python进行数据处理变得非常快速和简单。
Pandas最核心的结构就是对DataFrame的处理。
DataFrame结构:
- DataFrame是一种二维的结构,可以将其想象为一种excel工作表,如下图所示:

Series结构
- Series是带索引的一维数组。
- Series对象的两个重要属性:index(索引)和values(数据值)。
- DataFrame 的任意一行或任意一列就是一个Series 对象。


DataFrame包含Series对象。
数据合并
1.轴向连接:
- pd.concat(), axis = 0 横向轴
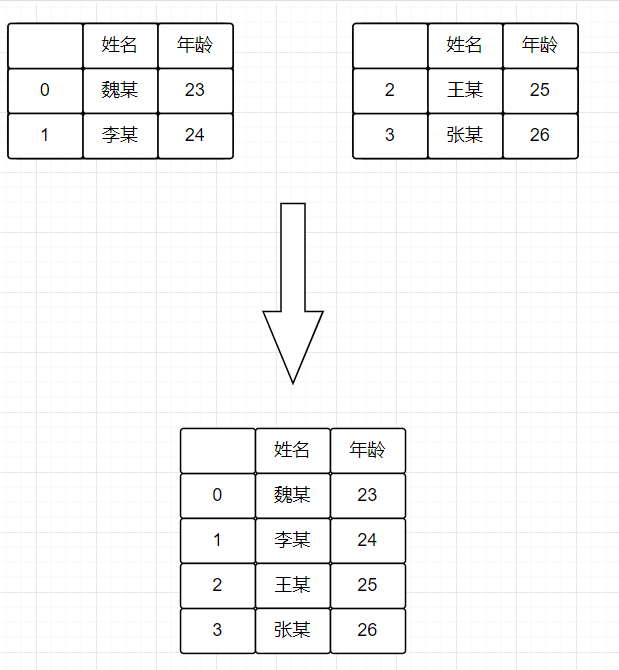

pd.concat(), axis=1 横向轴
pd.concat()函数的常用参数
- axis:默认值为0,轴向连接所沿的轴。
- objs:需要连接的对象的列表。
- ignore_index:布尔值,默认为False,为True则不适用连接轴上的索引值,生成的轴被标记为:0,…,n-1
- keys:序列,默认为None。使用该序列构建层次化索引,且该索引在最外层。
- join:{‘inner’,‘outer’},默认为outer,指定处理其他轴上的索引,‘outer’ 表示取并集,'inner’表示取交集。
数据融合——pd.merge()
也是将多个表进行连接,拼接融合的一种方式,这种拼接方式和之前的拼接方式有所不同,concat是将数据A,B拼接到一起,merge需要考虑数据融合。

pd.merge()中包含的常用参数:
- left:参与合并的左侧的DataFrame。
- right:参与合并的右侧的DataFrame。
- how:{‘left’,‘right’,‘outer’,’inner‘},默认为inner。
- on:用于连接的别名,必须包含在左右两个DataFrame中。
- left_on:左侧DataFrame中作为连接键的列。
- right_on:右侧DataFrame中作为连接键的列。
- left_index:{True,False},将左侧的行索引用作其连接键。
- right_index:{True,False},将右侧的行索引用作其连接键。
- suffiex:字符串值元组,用于追加到重叠列名的末尾,默认(’_x‘,’_y’)。
数据转换
- 利用函数或映射进行数据转换。
- 可以将自己定义的或其他包提供的函数用在Pandas对象上以实现批量修改。
- 实现数据转换的常用方法:applymap和map实例方法。
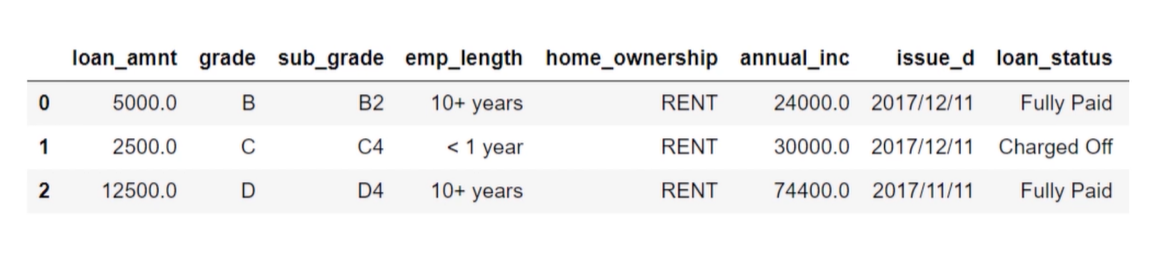
例:生成一个指标变量indicator,如果取值为0,表示“load_status=Fully Paid”,如果取值为1,表示“load_status = Charged Off”

如果我们需要将数据按照一定的映射关系进行替换,则可以选择使用replace方法,将工作年限中的“10+years”替换为high

课程收获
在昨天学习Python的高级用法以及Numpy之后,今天又接触到了新的数据处理工具——Pandas,帮助我提升了对二维数组创建,导出的能力,解决了openpyxl在excel表导入导出时复杂的逻辑,精简代码结构,提升代码处理效率,收获颇多,感谢老师带来的对Pandas系统的讲解。







