
第一模块
课程名称:Spark3大数据实时处理-Streaming+Structured Streaming 实战
章节名称:4-1 ~ 4-6
讲师姓名:Michael_PK
第二模块
内容概述:
4-1 ~ 4-6小节主要讲述了采集和收集的区别,已经Flume框架产生的背景,很好的交代了Flume框架产生之前的一个行业痛点,随后引出了Flume框架,交代了Flume框架解决了啥问题,已经Flume框架的3大核心组件。
第三模块
学习心得:
通过4-1 ~ 4-6小节的学习使我了解到了Flume框架产生的原因,以及Flume框架的版本迭代历史,对Flume有了基本的认识,知道了其所处的生态位,和其所要解决的问题,这些知识的增量使我之前很多没想明白的地方都豁然开朗,下面附上学习笔记:
4-1 章节目录:
基于Flume构建分布式日志收集系统
产生背景
Flume概述
体系架构与核心组件
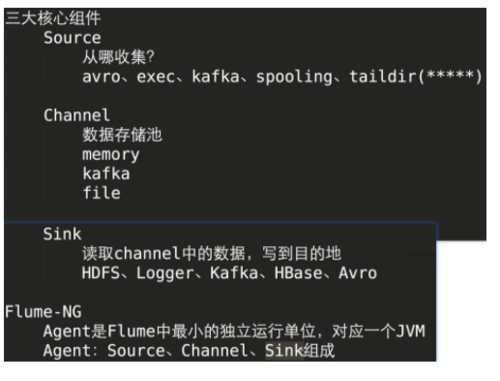
Flume常用三大件(sourc【数据源】、channel【渠道】、sink【下发】)
业界数据收集框架对比
Flume部署与前置要求
Flume经典部署案例
Flume案例实战
Flume拦截器二次开发(基于Flume的定制开发)
Flume收集客户端上报的日志数据
4-2 产生背景:
日志数据存在于n台日志服务器上,数据是分散的,需要将分散的数据进行收集,收集到HDFS上(大数据平台),海量数据进入到大数据平台后就可以使用大数据技术对海量数据进行处理。
也就是说,日志的收集十分重要,是大数据计算的基石。
两种收集日志的方式:
自开发一套日志收集系统,需要处理容错、性能、安全性等问题
借助框架的力量,直接站在巨人的肩膀上
Flume也就孕育而生了!!!
补充:
网关:就是网络的入口,有网关就表示网络是通的,可以通过网络请求到远程资源
4-3 采集和收集的区别:
大数据处理的一个通用过程:
数据收集 ==》情况1: HDFS(离线) ==》分布式数据处理
==》情况1:kafka(实时)
数据来源:
业务数据(关系型数据库)
爬虫数据(爬取公开的数据是可以的)
购买合作的数据
采集数据(用户的行为数据)
采集 VS 收集
采集:数据的生成 最终产物是一个logFile
收集:数据的移动 收集到HDFS/Kafka中
对不同的数据源,需要采取不同的数据收集方案:
对mysql做数据收集:取binlog日志
对Oracle做数据收集:sqoop(离线)、OPG(实时)
从服务器的服务中收集:Flume
4-4 Flume入门:
一张图看懂Flume:

针对日志数据进行收集工具
把日志从A地收集到B地
Flume ==》 HDFS ==》离线处理
Fluem ==》Kafka ==》实时处理
实时处理的框架:
storm
Spark Streaming
flink
市面上的实时处理框架都是支持整合kafka的,尤其是flink,还实现了kafka的消费者API(在kafka消费者API的基础上封装了一层),从而支持了【精确消费一次】的语义。Storm保证的是【至少消费一次】,确保数据不重复的代价很高。
Flink简介:http://www.wjhsh.net/supertonny-p-11305118.html
4-5 Flume版本迭代:
版本:
og(老版本) 0.9版本发生了巨大变化
ng (新版本)目前业界用的基本都是ng的
4-6 Flume体系架构与三大组件(重要):
总纲:Flume的使用非常的简单,只从使用的角度上来看,核心就是配置文件,对于不同的source就会有不同的配置,所以,用记忆的方式并不是一个方法,关键是能在官网查文档,基于文档驱动配置。
第四模块
学习截图:






