
正文之前
一鼓作气!肝死它!!!!
正文
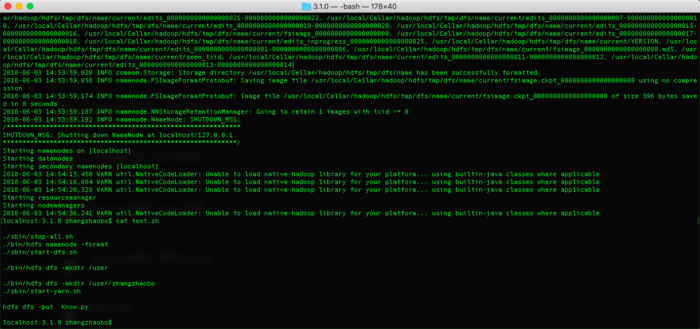
前面都已经配置好了。我就准备试试伪分布式了!!结果??!啊哈?!?!
localhost:hadoop zhangzhaobo$ cd 3.1.0/localhost:3.1.0 zhangzhaobo$ hdfs dfs -put /Users/zhangzhaobo/program/python/KnowledgeGame.py logs2018-06-03 14:38:52,230 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2018-06-03 14:38:53,685 WARN hdfs.DataStreamer: DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/zhangzhaobo/logs._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and no node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2116) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:287) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2688) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:875) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:559) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1682) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675) at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1491) at org.apache.hadoop.ipc.Client.call(Client.java:1437) at org.apache.hadoop.ipc.Client.call(Client.java:1347) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116) at com.sun.proxy.$Proxy11.addBlock(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:504) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy12.addBlock(Unknown Source) at org.apache.hadoop.hdfs.DFSOutputStream.addBlock(DFSOutputStream.java:1078) at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1865) at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1668) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716)put: File /user/zhangzhaobo/logs._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and no node(s) are excluded in this operation.
数据节点不见了???WTF?
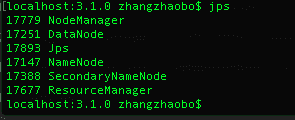
现在是有的 ,一开始没有!
所以就去找呀找~ 最后找到了两个法子。。
启动Hadoop时,DataNode启动后一会儿自动消失的解决方法
从日志中可以看出,原因是因为datanode的clusterID 和 namenode的clusterID 不匹配。
(在slaver端上修改)
打开hdfs-site.xml里配置的datanode和namenode对应的目录,分别打开current文件夹里的VERSION,可以看到clusterID项正如日志里记录的一样,确实不一致,修改datanode里VERSION文件的clusterID 与namenode里的一致,再重新启动dfs(执行start-dfs.sh)再执行jps命令可以看到datanode已正常启动。
上面这个是比较正统的做法!我是个正统的人吗??是!当然是。。但是这次不行。伪分布式。。。比较任性。猥琐一波!!
直接删除掉前面产生的文件就ok!

我的是这样,看你把你的文件系统挂在哪儿了!!
然后运行下面的代码:
./sbin/stop-all.sh ./bin/hdfs namenode -format ./sbin/start-dfs.sh ./bin/hdfs dfs -mkdir /user ./bin/hdfs dfs -mkdir /user/zhangzhaobo ./sbin/start-yarn.sh hdfs dfs -put Know.py
当然一把就成功啦!!
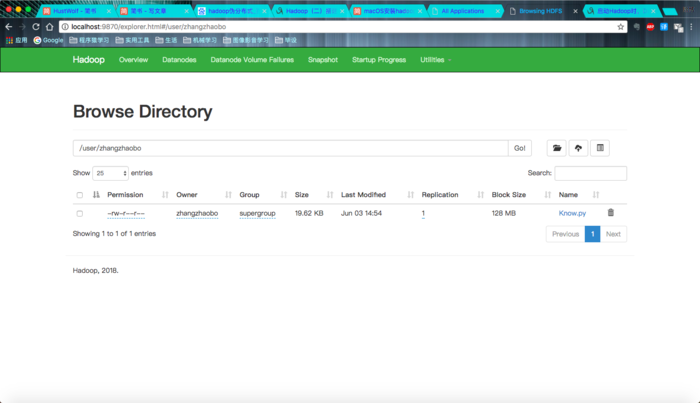
然后试试按照例程来哈~
进入mapreduce目录

运行程序:
localhost:mapreduce zhangzhaobo$ hadoop jar hadoop-mapreduce-examples-3.1.0.jar wordcount /user/zhangzhaobo/in /user/zhangzhaobo/out/resultWordCount

查看result

这是运行成功的过程:
2018-06-03 15:25:38,662 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2018-06-03 15:25:39,697 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:80322018-06-03 15:25:40,514 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/zhangzhaobo/.staging/job_1528008869850_00032018-06-03 15:25:40,819 INFO input.FileInputFormat: Total input files to process : 12018-06-03 15:25:40,910 INFO mapreduce.JobSubmitter: number of splits:12018-06-03 15:25:40,960 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled2018-06-03 15:25:41,104 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1528008869850_00032018-06-03 15:25:41,106 INFO mapreduce.JobSubmitter: Executing with tokens: []2018-06-03 15:25:41,372 INFO conf.Configuration: resource-types.xml not found2018-06-03 15:25:41,373 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.2018-06-03 15:25:41,463 INFO impl.YarnClientImpl: Submitted application application_1528008869850_00032018-06-03 15:25:41,513 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1528008869850_0003/2018-06-03 15:25:41,514 INFO mapreduce.Job: Running job: job_1528008869850_00032018-06-03 15:25:50,700 INFO mapreduce.Job: Job job_1528008869850_0003 running in uber mode : false2018-06-03 15:25:50,702 INFO mapreduce.Job: map 0% reduce 0%2018-06-03 15:25:57,808 INFO mapreduce.Job: map 100% reduce 0%2018-06-03 15:26:04,871 INFO mapreduce.Job: map 100% reduce 100%2018-06-03 15:26:04,887 INFO mapreduce.Job: Job job_1528008869850_0003 completed successfully2018-06-03 15:26:05,005 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=2684 FILE: Number of bytes written=431255 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2281 HDFS: Number of bytes written=2126 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=4094 Total time spent by all reduces in occupied slots (ms)=4530 Total time spent by all map tasks (ms)=4094 Total time spent by all reduce tasks (ms)=4530 Total vcore-milliseconds taken by all map tasks=4094 Total vcore-milliseconds taken by all reduce tasks=4530 Total megabyte-milliseconds taken by all map tasks=4192256 Total megabyte-milliseconds taken by all reduce tasks=4638720 Map-Reduce Framework Map input records=36 Map output records=191 Map output bytes=2902 Map output materialized bytes=2684 Input split bytes=126 Combine input records=191 Combine output records=138 Reduce input groups=138 Reduce shuffle bytes=2684 Reduce input records=138 Reduce output records=138 Spilled Records=276 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=154 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=407896064 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=2155 File Output Format Counters Bytes Written=2126
弄了三次才成功的!!
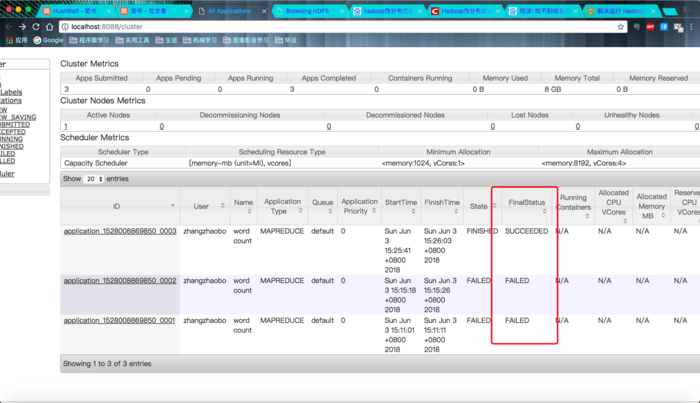
原因是一开始有一个地方一直报错。。说我的主类加载不到???WTF?
[2018-06-03 15:15:24.474]Container exited with a non-zero exit code 1. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :Last 4096 bytes of stderr : 错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster[2018-06-03 15:15:24.474]Container exited with a non-zero exit code 1. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :Last 4096 bytes of stderr : 错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
然后找到了如下文章,贼有用!
然后例程主要是参考的这个人来的:
正文之后
溜了溜了,在测试一个例程就睡觉,然后去健身房咯!晚上回去搭建集群~
作者:HustWolf
链接:https://www.jianshu.com/p/e6d5c17ecd15
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




