
一、背景
svc是deamon-tools工具集中用户守护进程的服务,头条目前在线上使用它来保证服务的存活(目前正在切换到更可靠的systemd)。当进程挂掉时,svc能自动重启挂掉的进程,当被监控的进程有代码更新时,我们可以通过svc发送命令让进程进行重启,以加载新上线的代码。
最近,我们发现部分模块有重启失败的情况,这种情况发生的几率极其小,几乎没法复现。然而今天,出现了另外一个奇怪的情况,就是没有进行过任何改动的模块,出现了无法启动的问题。追查到最后,终于发现模块启动失败与模块重启失败实际是一个问题。 更具体的现象:对于一个应用,执行启动命令『python bootstrap.py』,发现程序只打印了一行信息(而正常启动会打印非常多信息),访问相应的URL,返回504,证明应用根本就没起来,下面开始追查。 注:以下部分涉及到公司代码及代码路径的地方,会做适当替换/打码处理,不会影响问题追查的描述。
二、程序的最后状态
先看一下程序最后的执行状态,再一步步往上跟吧 Ctrl + C打断程序执行,程序会出错打出调用栈,直接贴出调用栈最深的部分:
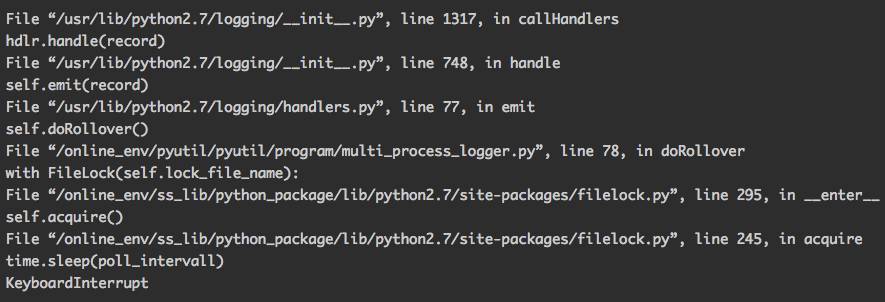
程序应该是卡在获取某个文件锁上了,使用strace来看一下当前执行的系统调用:
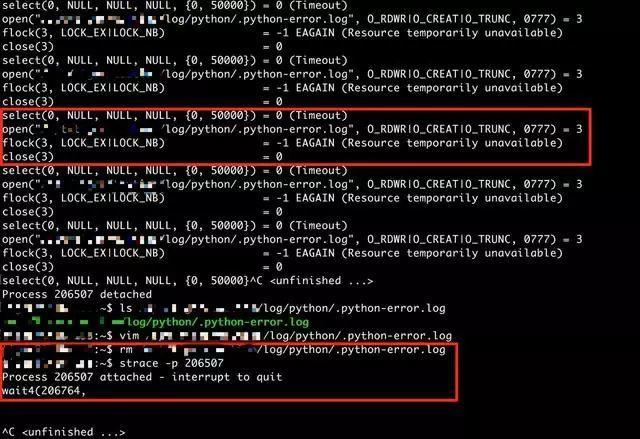
先看上面的红色框,程序当前是在不断地尝试得到『.python-error.log』这个文件锁,为什么程序要获取这个东西?去对应的目录看了一下『.python-error.log』这个文件是存在的,内容为空。这个时候如果把它删掉呢? 于是我真的把它删了,看一下下面的红色框,再次strace程序,发现已经没有了获取文件锁的尝试了,而且神奇的是这个时候程序启动成功了,如下所示:

原本只打了一行信息,后来把文件锁对应的文件删掉后,下面的其它启动信息全部打印出来了。 那么获取文件锁的代码,究竟调用条件是什么?为什么要获取文件锁?看一下源码:
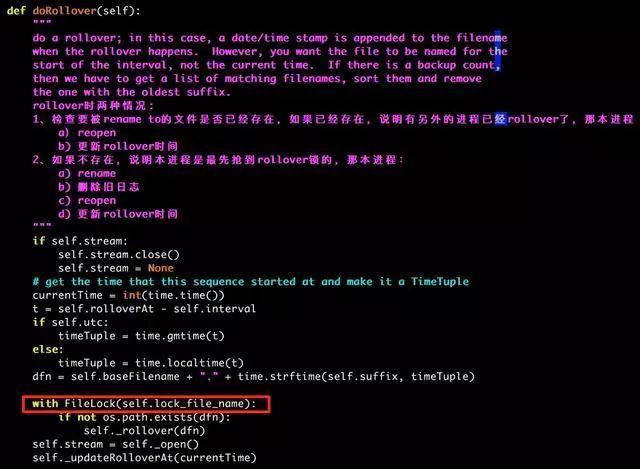
说明这个函数是在日志进行切分时调用的,由于多个进程可能会打印日志到同一个文件,当它们都发现应该切分日志时,应该由谁去切分呢?假设要切分的日志文件名为『A.log』,程序的逻辑就是大家都去 阻塞地抢名为『.A.log』的文件锁,谁抢到了谁就去切分一下日志。 这里再说一个实际是后面才观察到的结论,就是程序什么时候去检查是否要切分日志?即什么时候执行这个『def doRollOver』函数?在每次有日志需要打印的时候,例如出现『logger.INFO/TRACE..』或者『logging.INFO/TRACE…』,因此每次打印日志,就会调用这个函数,但是否一定会执行到获取文件锁那一段代码(with Filelock…),还不一定,它会检查是否到了切分间隔,到了切分间隔才会切分日志。不了解python的log handler的同学可以去看一下相关资料,这个东西有点类似回调函数,如果你注册了一个log handler到某个某个logger,则这个logger在每次发生日志打印行为的时候,就会调用handler里面的『emit』函数(这里调用了父类的emit,父类的emit调用doRollOver函数)。
三、初步结论
1.程序启动时会使用『.python-error.log』作为文件锁,如果无法获得文件锁就一直等待;
2.有其它程序占用了文件锁,而且一直不释放,导致程序无法启动;
3.由于所有服务化的程序都要在启动时获取一下这个文件锁,如果某台机器上出现了锁一直没释放的情况,那么从那一刻开始之后所有的要打印到这个文件的程序都无法重启、启动,而且在大量上线的时候你还没办法发现这个问题。
四、谁动了大家的文件锁
在上述过程中我已经把『.python-error.log』这个文件删掉了,所以问题在这台机器上暂时就没法继续查了。还好还有另外一台有问题的线上机器! 现在就要找出是谁拥有这个文件锁,我搜了很久,都没说怎么查文件锁归属(英文中文变着搜)。后来忽然想到我直接看看谁打开了这个文件应该就可以了吧,然后再慢慢排除?这些转不过脑子的变通总是能卡你很久…… 关键的良心工具『lsof』出马了,结果如下图:

乍一眼看上去,像是我之前启动的程序中的几个子进程在占用,直接用ps命令查看我之前起的所有进程,如下图:
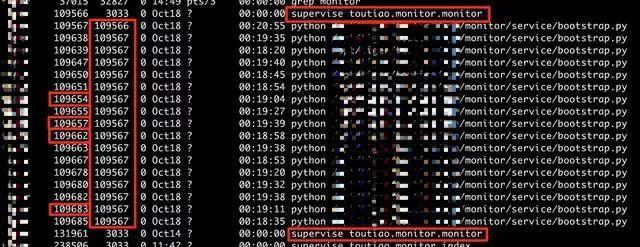
就是这几个进程无疑!上面使用lsof列出的PID在下面的ps命令列出的PID中悉数出现,而且都是我怀疑的目标进程,同一个服务『supervise toutiao.monitor.monitor』同时存在两个,现在重新用strace查看这些问题进程到底在执行什么。 先直接看看模块服务的父进程109567在干什么:
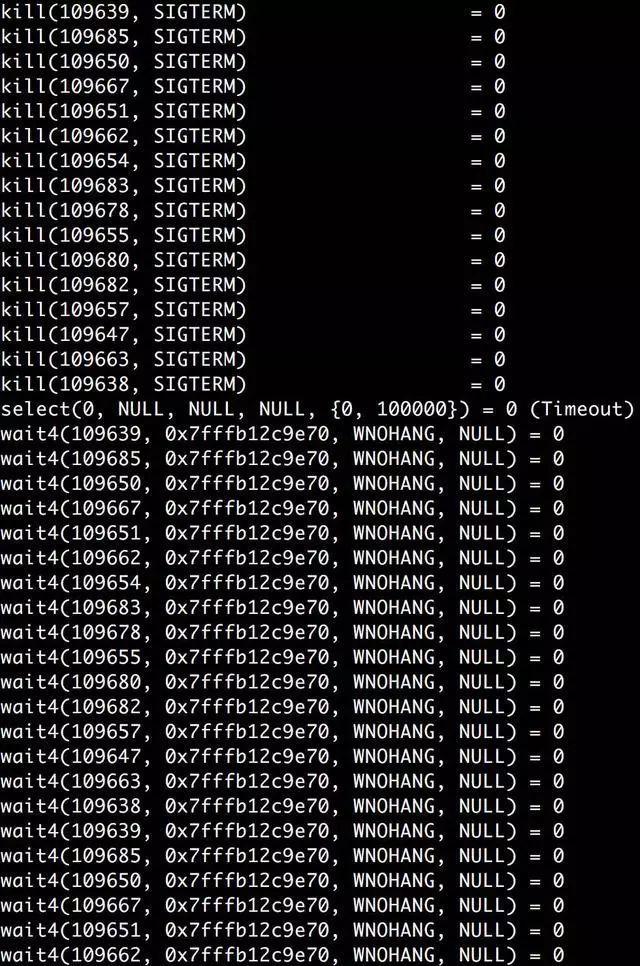
父进程在发送SIGTERM信号给子进程,然后等待这些子进程,如果等着等着发现子进程不退出,又会重新发送SIGTERM信号,不断循环。 那么子进程为什么就非不退出呢? 看一下打开了『.python-error.log』的子进程在干什么,依然使用strace:
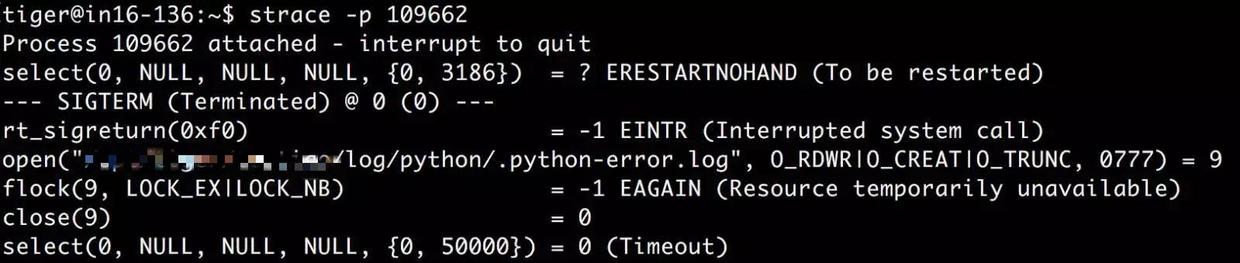
还是在不断地获取文件锁! 那么到底还有谁在拿着这个文件锁不放?
五、中段结论
1.某些模块无法启动、无法重启的问题,其直接原因都是有人占用了『.python-error.log』这个文件锁,导致想启动的起不来,想退出的退不了;
2.通过lsof能够发现当前尝试打开文件的只有这些想退出的service子进程;
3.因此『.python-error.log』文件锁的占用只可能有2种情况:a.有其它程序退出时没有释放文件锁,导致文件一直被锁,别的程序没法用;b.service某些进程在获取锁之后没有释放,导致其它进程无法获取。
我们现在就要查出在结论3中,到底是a还是b导致了所有进程无法获取锁。
六、文件锁的获取与释放
感觉快要接触到真理了! 谁导致了文件锁无法释放:a.是已退出的程序没有释放文件锁;b.还是在运行的程序自己没有释放文件锁导致进程内死锁。 文件锁在程序退出时,会自动释放,所以只剩下一个可能了,就是进程内部有死锁。
七、哪里发生了死锁?
有一点需要引起注意,为什么所有的子进程都会尝试去获取『.python-error.log』这个文件锁?之前已经查明了,只有在打印日志的时候,才有可能触发获取文件锁的代码,子进程在哪里打印日志导致它想获取文件锁? 看源码:
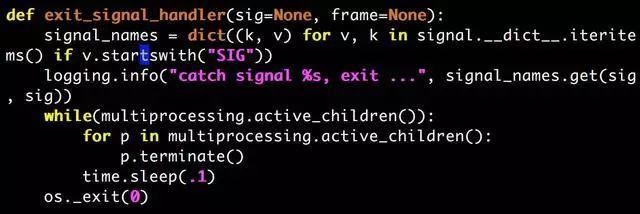
就是这里!svc发送重启命令(SIGTERM)时,父进程会进入『def exitsignalhandler』这个函数,父进程在这个函数里会发送『SIGTERM』给所有的子进程,所有子进程接到信号,实际上也是进入这个『def exitsignalhandler』函数,然后它们调用了『logging.info…』! 但这个应该不会造成死锁,顶多是各个子进程排队去获取一下这个锁而已,除非某个拿到锁的子进程hung住了。。。。。为什么它会hung住?我不负责任地猜测,因为它在等着拿锁! 灵光一闪后的细思极恐,它自己已经拿到锁了,为什么它还要再拿一次!?我忽然想起上面第3节使用strace观察父进程时它在干的事情——父进程在不断发SIGTERM给子进程。 看一下代码,就是这样的!父进程只要发现子进程没有完全退出,就会隔0.1秒重新发一次SIGTERM给所有活着的子进程。 信号处理函数是抢占式的,无论当前的进程在干什么,只要信号一来,会保存当前执行的上下文,强制切换到信号处理函数并开始执行,设想一个这样的场景(下面就是理解这次线上问题的关键):
1.子进程A接到SIGTERM信号,它要准备退出了,于是打印一条日志说『我接收到信号,要退出了』;
2.子进程A在打印日志的时候,发现——哎呀,到点切日志了,获取一下文件锁先。于是,它成功获取了文件锁;
3.当它成功获取到文件锁的时候,忽然,又收到一个『SIGTERM』信号。这个信号来自父进程,因为父进程心里想:都过去0.1秒了,怎么子进程还没退出啊?我再发一个SIGTERM给子进程让它退出。于是子进程人格分裂了;
4.子进程把自己原来的人格保存好,新的人格心想——我接到SIGTERM信号,准备退出了,打印一条日志说『我接收到信号,要退出了』,打印日志的时候发现——哎呀,到点切日志了,获取一下文件锁先…获取一下文件锁先…获取一下文件锁先…
死锁发生了!感觉就是这个原因啊!但是严谨的我还是设计了一个小程序来验证我的想法,万一对于每个进程而言,它可以多次获取它已经获取到的文件锁呢? 我的程序源码如下:
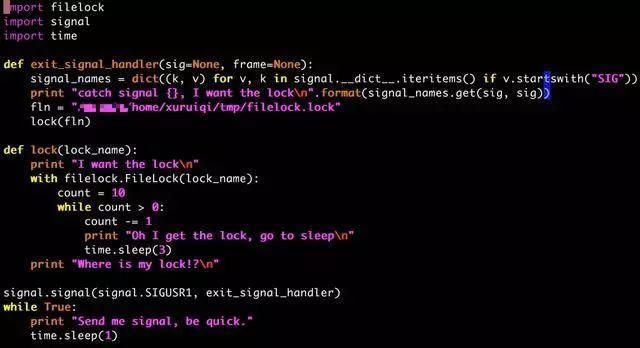
很简单的实验办法:
1.开两个窗口,都执行这个程序,假设为进程A和进程B。
2.然后给进程A发送SIGUSR1,进程A这个时候会获取『filelock.lock』这个文件锁,它不释放,它直接就睡觉
3.这个时候给进程B发送SIGUSR1,进程B无法拿到锁,所以一直轮询
4.在A睡眠结束前,再发送一个SIGUSR1信号给进程A
5.观察两个进程的执行情况
直接上图,上方是进程A,下方是进程B:
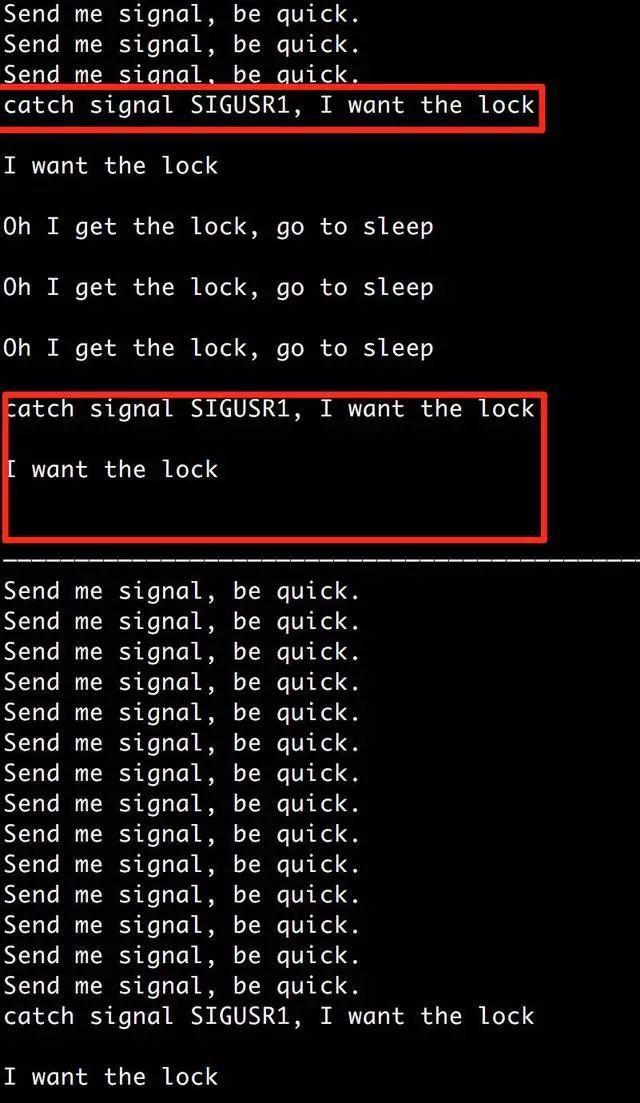
好了,复现了,两个进程都没法继续往下走了。正常情况下,进程拿到锁30秒后就会释放,但是我等了很久,锁都没有释放,程序也没动。
八、最终结论
至此,我们得到了最终结论:
1.父进程接到重启、退出信号(SIGTERM)时,会发送SIGTERM信号给所有的子进程; 2.子进程接到SIGTERM信号,打印一条日志表明自己要退出了,这个时候如果恰好要进行一次日志切分,它会获取相应日志的文件锁,获取成功后准备进行日志文件的重命名以及新建; 3.父进程等了0.1秒,发现还有子进程没有退出,于是重新发送SIGTERM信号给所有未退出的子进程; 4.刚才获取了文件锁的子进程恰好还没有释放锁的时候再次接到SIGTERM信号,于是将当前的上下文环境保存(不释放文件锁),重新开始执行信号处理函数,信号处理函数中打印一条日志表明自己要退出了,然后发现要进行日志切分,去尝试获取文件锁,这个时候,发现文件锁被占用,于是它阻塞等待这个文件锁。 5.死锁发生,所有未退出的子进程都无法退出,并且父进程一直发送信号给子进程。 不知道上下文不断保存会不会造成线上出core?按道理说在时间足够长的情况下,内存没法继续放得下上下文了,整个进程就直接退出了(这个时候文件锁被释放)然后supervise发现进程死了,好家伙,重新启动,这个时候,由于文件锁已经释放了,所以程序可以重新启动了,并且日志也正常切分了。而在程序挂掉到重新启动之间,这个时间到底有多长,不好说,可能持续几天也是有可能的。除非说保存上下文的机制与我想的不一样,否则最终基本内存不够用。 但无论上下文的保存机制是怎么样的,有一个没法否认的,就是文件锁肯定是不会释放。
九、解决方案
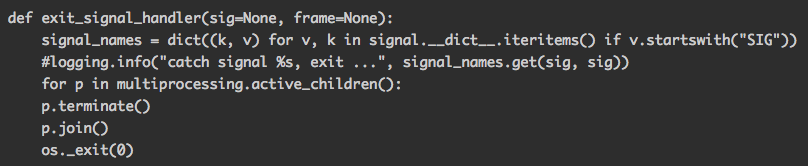
知道原因后解决方案就相对简单了,父进程不需要多次发送SIGTERM给子进程,发送一次就可以了(如果发送一次都没法退出的子进程,发送两次也是重新执行信号处理函数,行为就更加无法预测了),发送后直接阻塞地join子进程就可以了。 目前修改后的信号处理函数代码如下:
折腾了一整天啊这个问题,上面的追查看似行云流水,实际碰壁极多,Google+百度搜了很多无效的结果。还好最终查到了。
出自:今日头条技术博客,原文地址https://techblog.toutiao.com/2018/05/30/untitled-26/




