
课程名称:笑傲Java面试 剖析大厂高频面试真题 秒变offer收割机
课程章节:第7章 存储、缓存、搜索基础篇
主讲老师:求老仙
课程内容:
第7章 存储、缓存、搜索基础篇
课程收获:
问题1)行存储和列存储?Mysql是行存储,支持事务。
-
每一行不是等大的,例如:varchar(200)不是等大的,大小是随内容变化,最大不超过200,而int(10)是等大的,存储的内容只保留10位
-
列存储,方便搜索列。是按照列的逻辑存储,一列一列的存储。
行存储的优点:事务操作更方便(直接操作行),方便添加行,修改行,删除行,搜索的时候需要把所有列都搜索出来(缺点)

问题2)正排索引和倒排索引?MySQL既不是倒排索引,也不是正排索引?
正排索引和倒排索引,针对是全文的检索。
全文正排索引:通过全文检索词语,就是正排索引
全文倒排索引:通过词语查全文,是倒排索引
正排索引和倒排索引的前提是全文搜索,MySQL的索引既不是正排索引也不是倒排索引
MySQL不是全文搜索,所以不属于正排或倒排索引
问题3)为什么需要索引?以及不使用索引会怎么样?
1,为什么要用id做索引,而不是业务字段?
Id是要做索引的,业务字段有重复,所以不适合做索引。
2,如果不使用索引,会怎么样?
就按照顺序存储,查找的时候,可以用二分查找,如果非顺序的列,就从上往下查
如果插入一行,就要将所有的数据往后挪,因为要保证顺序。
删除一行,可以不挪动,但是会有碎片
- 使用红黑树索引:
红黑树前提是一颗二叉搜索树
红与黑的目的是给实现着,保证二叉搜索的平衡(根节点是黑节点,根节点到叶子节点黑节点相差不超过1,叶子节点是红色)

问题3.1)为什么不使用红黑树做索引?
例如:有1G行索引,大概是2的30次方,10亿个节点。
**查询:**最多查询30次
**所需空间:**一个节点包含,行号,两个指针,索引值(例如Id),假如都是整型4个字节
1g行索引的大小 1G44 = 16G,显然存储一个索引,就需要16G内存,是非常大的,所以引入了B树

使用了B树之后:每个超级节点4k的空间,只需要在索引中使用一个节点16字节
(B树只存储索引的话,只需要存储4k的一个节点)
先查索引(只存储索引,索引存储在B+树中),再查磁盘

B树种存储的是索引,找到索引后,再去4k的存储中间中找数据

问题3.1)innodb索引的存储结构?
Id对应磁盘中的行,一次读取4k
聚集索引的存储结构:B+树种存储的是,(id - > 行号),是存储表的主键范围(并不是每个键都创建了索引,而是一个范围)。行号对应的就是在磁盘的4k空间中行所在位置。
非聚集索引的存储结构:B+书中存储的结构是(key-id),是存储整张表的key-id的索引,所以如果插入数据或者删除数据,id发生改变,就要更新二级索引
先看看B+Tree是怎样的,B+Tree是B Tree的一个变种,在B+Tree中,B树的路数和关键字的个数的关系不再成立了,数据检索规则采用的是左闭合区间,路数和关键个数关系为1比1,具体如下图所示:
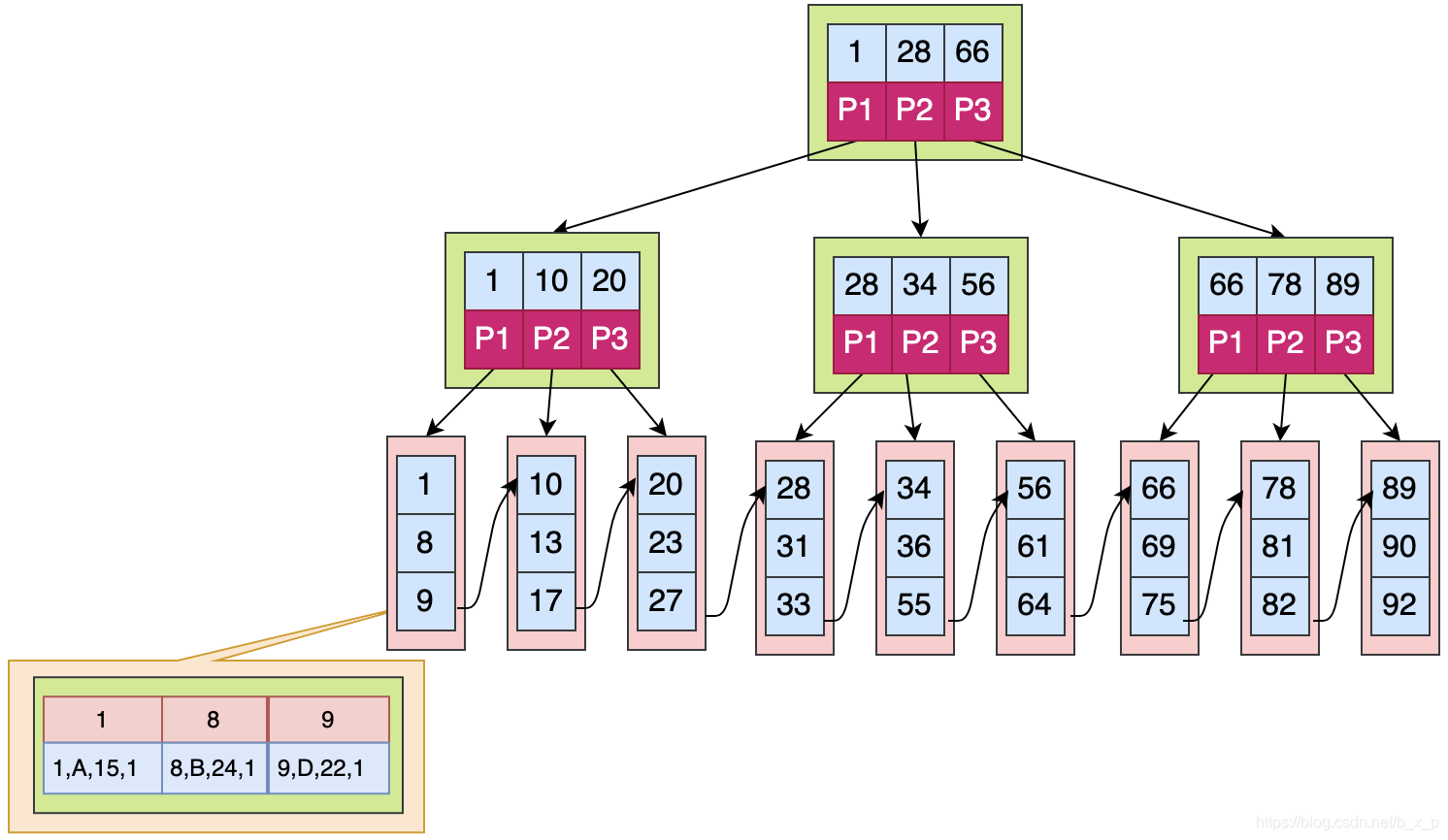
如果上图中是用ID做的索引,如果是搜索X = 1的数据,搜索规则如下:
取出根磁盘块,加载1,28,66三个关键字。
X <= 1 走P1,取出磁盘块,加载1,10,20三个关键字。
X <= 1 走P1,取出磁盘块,加载1,8,9三个关键字。
已经到达叶子节点,命中1,接下来加载对应的数据,图中数据区中存储的是具体的数据。




