
铺垫
人产生数据的速度越来越快,机器则更加快,more data usually beats better algorithms,所以需要另外的一种处理数据的方法。
硬盘的容量增加了,但性能没有跟上,解决办法是把数据分到多块硬盘,然后同时读取。但带来一些问题:
硬件问题:复制数据解决(RAID)
分析需要从不同的硬盘读取数据:MapReduce
而Hadoop提供了
1.可靠的共享存储(分布式存储) 2.抽象的分析接口(分布式分析)
大数据
概念
不能使用一台机器进行处理的数据
大数据的核心是样本=总体
特性
大量性(volume): 一般在大数据里,单个文件的级别至少为几十,几百GB以上
快速性(velocity): 反映在数据的快速产生及数据变更的频率上
多样性(variety): 泛指数据类型及其来源的多样化,进一步可以把数据结构归纳为结构化(structured),半结构化(semi-structured),和非结构化(unstructured)
易变性: 伴随数据快速性的特征,数据流还呈现一种波动的特征。不稳定的数据流会随着日,季节,特定事件的触发出现周期性峰值
准确性: 又称为数据保证(data assurance)。不同方式,渠道收集到的数据在质量上会有很大差异。数据分析和输出结果的错误程度和可信度在很大程度上取决于收集到的数据质量的高低
复杂性: 体现在数据的管理和操作上。如何抽取,转换,加载,连接,关联以把握数据内蕴的有用信息已经变得越来越有挑战性
关键技术
1.数据分布在多台机器
可靠性:每个数据块都复制到多个节点
性能:多个节点同时处理数据
2.计算随数据走
网络IO速度 << 本地磁盘IO速度,大数据系统会尽量地将任务分配到离数据最近的机器上运行(程序运行时,将程序及其依赖包都复制到数据所在的机器运行)
代码向数据迁移,避免大规模数据时,造成大量数据迁移的情况,尽量让一段数据的计算发生在同一台机器上
3.串行IO取代随机IO
传输时间 << 寻道时间,一般数据写入后不再修改
Hadoop - 简介
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点
特别适合写一次,读多次的场景
适合
大规模数据
流式数据(写一次,读多次)
商用硬件(一般硬件)
不适合
低延时的数据访问
大量的小文件
频繁修改文件(基本就是写1次)
Hadoop架构
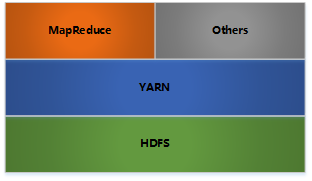
HDFS: 分布式文件存储
YARN: 分布式资源管理
MapReduce: 分布式计算
Others: 利用YARN的资源管理功能实现其他的数据处理方式
Hadoop安装
单节点安装
所有服务运行在一个JVM中,适合调试、单元测试
伪集群
所有服务运行在一台机器中,每个服务都在独立的JVM中,适合做简单、抽样测试
多节点集群
服务运行在不同的机器中,适合生产环境
配置公共帐号
方便主与从进行无密钥通信,主要是使用公钥/私钥机制 所有节点的帐号都一样 在主节点上执行 ssh-keygen -t rsa生成密钥对 复制公钥到每台目标节点中
这里仅仅是一个参考,可能暂时资料不全,如需要学习的请自行在网上查询,相信你能找到更好的资料学习。





