
本着对网络爬虫的兴趣,在闲来无事时做了一个有关网络爬虫的项目,本项目用的是Scrapy爬虫框架,同时为了有效利用这些数据,用入门的sklearn对这些数据进行预处理并训练除了一个预测模型,下面开始本项目的介绍。
1、数据准备与爬虫
本项目以房天下网站北京市租房信息为对象,首先确定爬取的房屋属性为:标题、出租方式、户型、建筑面积、朝向、楼层、装修程度等因素。首先我们获取要爬取内容的首页为http://zu.fang.com/,可以看到北京市有多个区,为了尽可能多的爬取租房数据,因此我们再每个区所在网页爬取100页。同时用xpath提取器来提取网页的内容,爬虫的代码如下:
import scrapy
from scrapy.http import Request
from zufang_scrapy.items import ZufangScrapyItem
import requests
from lxml import etree
class ZufangSpider(scrapy.Spider):
name = 'zufang'
headers = {'User_Agent':
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.168 Safari/537.36'}
def start_requests(self):
for i in range(1, 150):
start_url = "http://zu.fang.com/house-a0" + str(i) + "/"
for j in range(1, 100):
url = start_url + "i3" + str(j) + "/"
html=requests.get(url)
xpath1=etree.HTML(html.text)
href=xpath1.xpath(
'//p[@class="title"]/a/@href'
)
for link in href:
link1='http://zu.fang.com'+link
yield Request(link1, headers=self.headers)
def parse(self, response):
zufang = response.xpath('//div[@class="wid1200 clearfix"]')
for fangzi in zufang:
title=fangzi.xpath('/html/body/div[5]/div[1]/div[1]/text()').extract()
area = fangzi.xpath('//*[@id="agantzfxq_C01_03"]/text()').extract()
rent_style = fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[3]/div[1]/div[1]/text()').extract()
house_type= fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[3]/div[2]/div[1]/text()').extract()
house_area = fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[3]/div[3]/div[1]/text()').extract()
orientation = fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[4]/div[1]/div[1]/text()').extract()
floor = fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[4]/div[2]/div[1]/text()').extract()
decoration = fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[4]/div[3]/div[1]/text()').extract()
price = fangzi.xpath('/html/body/div[5]/div[1]/div[3]/div[2]/div/i/text()').extract()
for i in range(len(title)):
item = ZufangScrapyItem()
item['title'] = title[i]
item['area'] = area[i]
item['rent_style'] = rent_style[i]
item['house_type'] = house_type[i]
item['house_area'] = house_area[i][:-2]
item['orientation'] = orientation[i]
item['floor'] = floor[i][:-2]
item['decoration'] = decoration
item['price'] = price[i]
yield item
2、数据处理与sklearn
用Python的科学计算库Numpy和Pandas对爬取的数据进行去重,切片等处理操作,数据已经被保存在Mysql数据库中。处理完毕后,用sklearn训练处理后的数据并且用一些测试数据对模型进行评估。
skelarn算法:
import pandas as pd
from pylab import mpl
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import seaborn as sns
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif'] = ['FangSong']
df = pd.read_csv(u'chaoyang.csv',encoding="gbk" )
def change_decoration(x):
if x == "豪华装修":
x = 0.9
elif x == "精装修":
x = 0.7
elif x == "中装修":
x = 0.5
elif x == "简装修":
x = 0.3
else :
x = 0.1
return x
def change_floor(x):
if x=="高层":
x = 0.8
elif x=="中层":
x= 0.5
else :
x=0.2
return x
df["decoration_num"] = df["decoration"].apply(change_decoration)
df["floor_num"] = df["floor"].apply(change_floor)
X = df[['house_area', 'floor_num', 'decoration_num','price']]
y = df[['price']]
sns.pairplot(df,x_vars=['house_area','floor_num','decoration_num'],y_vars=['price'],size=7,aspect=0.8,kind=)
plt.show()
predictors = ["house_area","floor_num","decoration_num"]
X = df[predictors]
y = df["price"].tolist()
X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.05, random_state=1)
alg = LinearRegression()
alg.fit(X_train, y_train)
print(alg.score(X_test, y_test))
爬虫爬取过程如下:
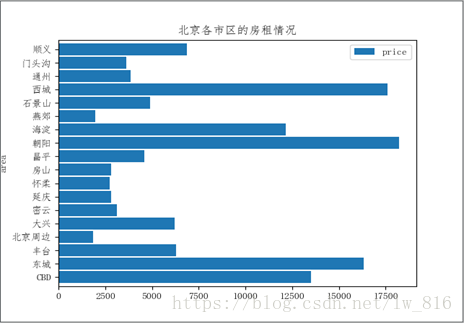
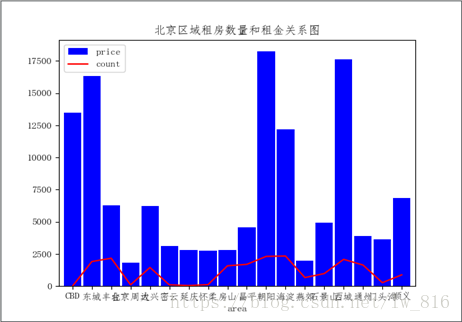
用可视化库matplotlib对数据可视化展示如下:
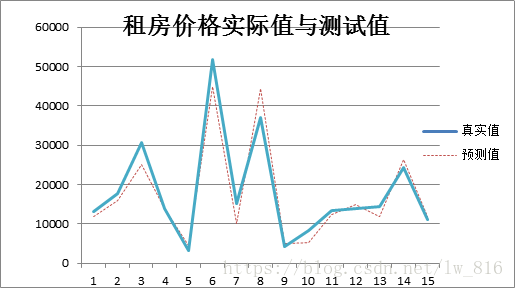
模型评估如下:
项目源码可以在我的github主页下载到:
https://github.com/Yokeng/CrawlProject
有问题可以留言告诉我哦






