
kafka linux单机安装
1 下载并安装kafka
# tar zxvf kafka_2.12-1.1.0tgz # mv kafka_2.12-1.1.0 /usr/local/kafka # cd /usr/local/kafka
2 启动服务
运行kafka需要使用Zookeeper,所以需要先启动一个Zookeeper服务器,如果没有Zookeeper,可以使用kafka自带打包和配置好的Zookeeper,&后台进程
# bin/zookeeper-server-start.sh config/zookeeper.properties &
然后启动kafka服务
# bin/kafka-server-start.sh config/server.properties &
3 新建一个topic
创建一个名为“test”的Topic,只有一个分区和一个备份:
# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建好之后,可以通过以下命令查看已创建的topic信息:
# bin/kafka-topics.sh --list --zookeeper localhost:2181 test
除手工创建topic外,也可以配置broker,当发布一个不存在的topic时自动创建topic。
Kafka提供了一个命令行工具,可以从输入文件或者命令行中读取消息并发送给Kafka集群,每一行是一条消息。运行producer,然后在控制台输入几条消息到服务器
# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a message This is another message
5 消费消息
Kafka也提供了一个消费消息的命令行工具
# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning This is a message This is another message
append:
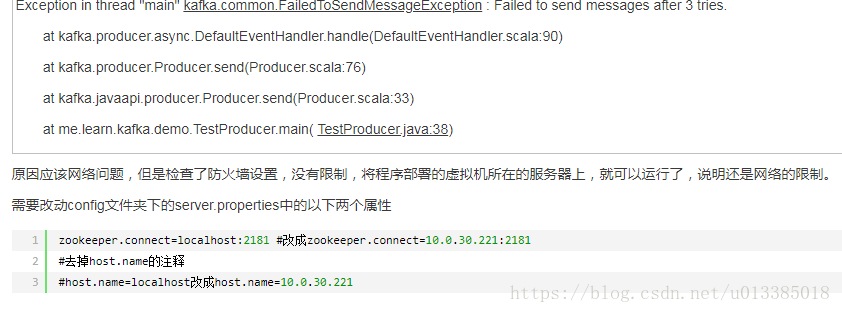
listeners=PLAINTEXT://172.16.49.173:9092
java 客服端连接代码
生产者代码
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer {
private final Producer<String, String> producer;
public final static String TOPIC = "test";
private KafkaProducer(){
Properties props = new Properties();
//此处配置的是kafka的端口
props.put("metadata.broker.list", "10.175.118.105:9092");
//配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
//配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder");
props.put("request.required.acks","-1");
producer = new Producer<String, String>(new ProducerConfig(props));
}
void produce() {
int messageNo = 1000;
final int COUNT = 10000;
while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello kafka message " + key;
producer.send(new KeyedMessage<String, String>(TOPIC, key ,data));
System.out.println(data);
messageNo ++;
}
}
public static void main( String[] args )
{
new KafkaProducer().produce();
}
}消费者代码
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import com.huawei.hwclouds.dbs.ops.base.huatuo.diagnosis.service.impl.KafkaProducer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
public class KafkaConsumer {
private final ConsumerConnector consumer;
private KafkaConsumer() {
Properties props = new Properties();
//zookeeper 配置
props.put("zookeeper.connect", "10.175.118.105:2182");
//group 代表一个消费组
props.put("group.id", "test-consumer-group");
//zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");//必须要加,如果要读旧数据
//序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConfig config = new ConsumerConfig(props);
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
}
void consume() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(KafkaProducer.TOPIC, new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
Map<String, List<KafkaStream<String, String>>> consumerMap =
consumer.createMessageStreams(topicCountMap,keyDecoder,valueDecoder);
KafkaStream<String, String> stream = consumerMap.get(KafkaProducer.TOPIC).get(0);
ConsumerIterator<String, String> it = stream.iterator();
while (it.hasNext())
System.out.println(it.next().message());
}
public static void main(String[] args) {
new KafkaConsumer().consume();
}
}




