
- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
-
1、测试环境
-
2、测试数据
GreatSQL马上正式开源了,这次又新增了两个重磅特性:InnoDB事务锁优化 以及 InnoDB引擎的并行查询优化,这两个特性是由华为鲲鹏计算团队贡献的Patch合并而来。
InnoDB并行查询优化怎么实现的?
根据B+树的特点,可以将B+树划分为若干子树,此时多个线程可以并行扫描同一张InnoDB表的不同部分。对执行计划进行多线程改造,每个子线程执行计划与MySQL原始执行计划一致,但每个子线程只需扫描表的部分数据,子线程扫描完成后再进行结果汇总。通过多线程改造,可以充分利用多核资源,提升查询性能。
优化后,在TPC-H测试中表现优异,最高可提升30倍,平均提升15倍。
该特性适用于周期性数据汇总报表之类的SAP、财务统计等业务,例如月初、月底跑批业务等。
使用限制:
-
暂不支持子查询,可想办法改造成JOIN。
-
暂时只支持ARM架构平台,X86架构平台优化也会尽快完成。
本文针对 InnoDB引擎的并行查询优化 特性进行对比测试。
1、测试环境
服务器:神州鲲泰R222,华为Hi1616 * 2(主频 2400 MHz 共64个逻辑CPU),256G内存。
操作系统:Docker 20.10.2,Docker容器下的CentOS Linux release 7.9.2009,Linux 4.15.0-29-generic。
本次测试采用TPC-H,dbgen构造测试数据参数 dbgen -vf -s 50,导入后数据库物理大小约70G。GreatSQL关键配置:
#运行Q10测试时,需要较大临时表
temptable_max_ram = 6G
#使得本测试基于纯内存场景
innodb_buffer_pool_size=96G
#InnoDB并行查询优化
#global级别,设置并行查询的开关,bool值,on/off。默认off,关闭并行查询特性。可在线动态修改。
force_parallel_execute = ON
#global级别,设置系统中总的并行查询线程数。有效值的范围是(0, ULONG_MAX),默认值是64。
parallel_max_threads = 64
#global级别,并行执行时leader线程和worker线程使用的总内存大小上限。有效值的范围是(0, ULONG_MAX),默认值是1G
parallel_memory_limit = 32G
2、测试数据
测试过程中,注意要确保每次查询都是基于纯内存的场景,也就是确保innodb_buffer_pool_size大于数据库物理大小,并确认查询过程中没有额外的物理I/O发生。
个别SQL例如Q10在运行过程中会产生临时表(Using temporary),这时候需要加大 temptable_max_ram 选项值。该选项默认值1G,在上述测试数据量前提下,大概需要加大到4G才能hold住。如果该选项值不够的话,可能运行过程中会提示诸如 The table ‘/tmp/#sql57_a1_0’ is full 这样的错误提示,然后退出查询,这是MySQL的BUG#99100。
InnoDB并行查询特性通过HINT语法可以很方便地使用,首先确认启用了该特性(可在线动态打开):
$ mysqladmin var|grep force_parallel_execute
| force_parallel_execute | ON
那么默认所有的SQL只要符合条件,即可自动采用并行查询,通过查看执行计划确认:
mysql> EXPLAIN SELECT ... FROM ... WHERE ...
...
Parallel execute (4 workers)
...
可以看到执行计划输出中包含 Parallel execute (4 workers) 关键字,这就表示最高可并行4个线程查询。
也可以查看树状执行计划:
mysql> EXPLAIN FORMAT=TREE SELECT ... FROM ... WHERE ...
...
| -> Limit: 1 row(s)
-> Sort: lineitem.l_returnflag, lineitem.l_linestatus, limit input to 1 row(s) per chunk
-> Table scan on <temporary>
-> Aggregate using temporary table
-> Parallel scan on <temporary>
-> Sort: lineitem.l_returnflag, lineitem.l_linestatus
-> Table scan on <temporary>
-> Aggregate using temporary table
-> Filter: (lineitem.l_shipdate <= <cache>((DATE'1998-12-01' - interval '88' day))) (cost=6342898.28 rows=19669815)
-> PQblock scan on lineitem (cost=6342898.28 rows=59015354)
...
可以看到执行计划中包含 PQblock scan on … 关键字,并且注意到同一行里提示 cost=6342898.28,这是启用并行查询的条件之一,也就是 cost 超过了 parallel_cost_threshold = 1000 设置的阈值开关。
一条SQL若不想启用并行查询,加上相应的HINT即可:
mysql> SELECT /*+ NO_PQ */ ... FROM ... WHERE ...
也可以动态调整并行线程数为最高64线程:
mysql> SELECT /*+ PQ(64) */ ... FROM ... WHERE ...
好了,直接查看结果对比数据:
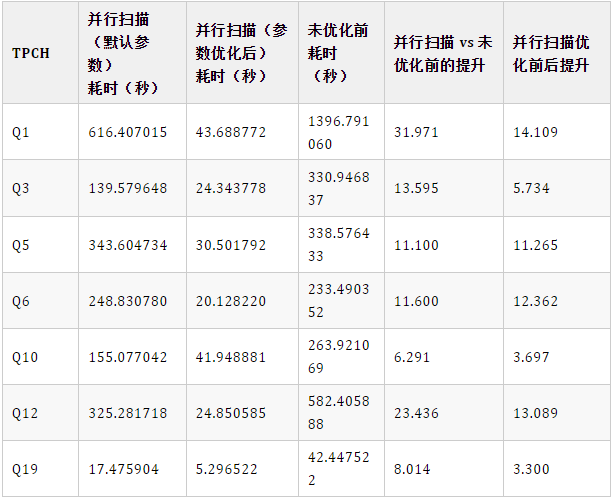
从这个测试结果简单概括几条:
- 1、平均提升约14倍,最高提升约32倍。
- 2、如果并发量更高,则优化效果更好。
- 3、Q5原始SQL性能提升不多,调整JOIN顺序后性能提升显著(从只提升28%跃升到11倍)。
GreatSQL将于近期正式开源,欢迎关注。
Enjoy GreatSQL :)





