
原标题:Spring认证中国教育管理中心-Apache Geode 的 Spring 数据教程六(Spring中国教育管理中心)
5.5.15.客户地区
Apache Geode 支持用于管理和分发数据的各种部署拓扑。Apache Geode 拓扑的主题超出了本文档的范围。但是,快速回顾一下,Apache Geode 支持的拓扑可分为:对等 (p2p)、客户端-服务器和广域网 (WAN)。在最后两个配置中,通常会声明连接到缓存服务器的客户端区域。
Spring Data for Apache Geode 通过其客户端缓存元素为每个配置提供专门的支持: client-region和pool. 顾名思义,client-region定义了一个客户端区域,同时pool定义了一个由各种客户端区域使用和共享的连接池。
以下示例显示了典型的客户端区域配置:
<bean id="myListener" class="example.CacheListener"/><!-- client Region using the default SDG gemfirePool Pool --><gfe:client-region id="Example"> <gfe:cache-listener ref="myListener"/></gfe:client-region><!-- client Region using its own dedicated Pool --><gfe:client-region id="AnotherExample" pool-name="myPool"> <gfe:cache-listener ref="myListener"/></gfe:client-region><!-- Pool definition --><gfe:pool id="myPool" subscription-enabled="true"> <gfe:locator host="remoteHost" port="12345"/></gfe:pool>
与其他 Region 类型一样,client-region支持CacheListener实例以及 aCacheLoader 和 a CacheWriter。它还需要一个连接Pool来连接到一组定位器或服务器。每个客户区域可以有自己的Pool,也可以共享同一个。如果未指定池,则将使用“DEFAULT”池。
在前面的示例中,Pool配置了一个定位器。定位器是一个单独的过程,用于发现分布式系统中的缓存服务器和对等数据成员,推荐用于生产系统。也可以Pool使用该server元素将 配置为直接连接到一个或多个缓存服务器。
对于选项来设置客户端上,特别是对的完整列表Pool,请参阅阿帕奇的Geode架构春数据(“春数据为Apache的Geode模式”)和Apache的Geode对文档 的客户端-服务器配置。
客户利益
为了最小化网络流量,每个客户端可以单独定义自己的“兴趣”策略,向 Apache Geode 指示它实际需要的数据。在 Spring Data for Apache Geode 中,可以分别为每个客户端区域定义“兴趣”。支持基于键和基于正则表达式的兴趣类型。
以下示例显示了基于键和基于正则表达式的interest类型:
<gfe:client-region id="Example" pool-name="myPool"> <gfe:key-interest durable="true" result-policy="KEYS"> <bean id="key" class="java.lang.String"> <constructor-arg value="someKey"/> </bean> </gfe:key-interest> <gfe:regex-interest pattern=".*" receive-values="false"/></gfe:client-region>
特殊键 ,ALL_KEYS表示为所有键注册了“兴趣”。使用正则表达式".\*".
该<gfe:*-interest>键和正则表达式的元素支持三个属性:durable,receive-values,和result-policy。
durable指示当客户端连接到集群中的一个或多个服务器时为客户端创建的“兴趣”策略和订阅队列是否跨客户端会话维护。如果客户端离开并返回,durable则在客户端断开连接的同时维护客户端服务器上的订阅队列。当客户端重新连接时,客户端会接收在客户端与集群中的服务器断开连接时发生的任何事件。
集群中服务器上的订阅队列为Pool客户端中定义的每个连接维护,其中订阅也已“启用” Pool。订阅队列用于存储(并可能合并)发送到客户端的事件。如果订阅队列是持久的,它会在客户端会话(即连接)之间持续存在,可能达到指定的超时。如果客户端在给定的时间范围内没有返回,则客户端池订阅队列将被销毁,以减少集群中服务器的资源消耗。如果订阅队列不是durable,当客户端断开连接时立即销毁。您需要决定您的客户端是应该接收断开连接时出现的事件,还是只需要在重新连接后接收最新的事件。
该receive-values属性指示是否为创建和更新事件接收条目值。如果true,则接收值。如果false,则只接收失效事件。
最后,'result-policy' 是一个枚举:KEYS, KEYS_VALUE, 和NONE。默认为KEYS_VALUES。result-policy当客户端第一次连接以初始化本地缓存时,它控制初始转储,实质上是为客户端提供与兴趣策略匹配的所有条目的事件。
Pool如前所述,如果不启用 上的订阅,客户端兴趣注册并没有多大用处。事实上,在未启用订阅的情况下尝试注册兴趣是错误的。以下示例显示了如何执行此操作:
<gfe:pool ... subscription-enabled="true"> ...</gfe:pool>
此外subscription-enabled,您还可以设置subscription-ack-interval、
subscription-message-tracking-timeout、 和subscription-redundancy。subscription-redundancy用于控制集群中的服务器应该维护多少订阅队列的副本。如果冗余大于 1,并且“主要”订阅队列(即服务器)出现故障,则“辅助”订阅队列接管,防止客户端在 HA 场景中丢失事件。
除了Pool设置之外,服务器端区域还使用附加属性
enable-subscription-conflation来控制发送到客户端的事件的合并。这也有助于进一步减少网络流量,并且在应用程序只关心条目的最新值的情况下很有用。但是,当应用程序保留发生的事件的时间序列时,合并将阻碍该用例。默认值为false。以下示例显示了服务器上的 Region 配置,客户端包含[CACHING_]PROXY对此服务器 Region 中的密钥感兴趣的相应客户端Region:
<gfe:partitioned-region name="ServerSideRegion" enable-subscription-conflation="true"> ...</gfe:partitioned-region>
要控制客户端与集群中的服务器断开连接后维护“持久”订阅队列的时间量(以秒为单位),请 按如下方式设置元素durable-client-timeout上的属性<gfe:client-cache>:
<gfe:client-cache durable-client-timeout="600"> ...</gfe:client-cache>
关于客户利益如何运作和能力的全面深入讨论超出了本文档的范围。
有关 更多详细信息,请参阅 Apache Geode 关于客户端到服务器事件分发的文档 。
5.5.16.JSON 支持
Apache Geode 支持在 Regions 中缓存 JSON 文档,以及使用 Apache Geode OQL(对象查询语言)查询存储的 JSON 文档的能力。通过使用JSONFormatter类执行与 JSON 文档的转换(作为),JSON 文档在内部存储为 PdxInstance类型。String
Spring Data for Apache Geode 提供了一个<
gfe-data:json-region-autoproxy/>元素,使 AOP组件能够建议适当的代理区域操作,它有效地封装了JSONFormatter,从而让您的应用程序直接使用 JSON 字符串。
此外,写入到 JSON 配置区域的 Java 对象会使用 Jackson 的 ObjectMapper. 当这些值被读回时,它们将作为 JSON 字符串返回。
默认情况下,<
gfe-data:json-region-autoproxy/>对所有 Region 执行转换。要将此功能应用于选定的区域,请在region-refs属性中提供以逗号分隔的区域 bean ID 列表。其他属性包括pretty-print标志(默认为false)和convert-returned-collections。
此外,默认情况下,会为配置的 Region 转换getAll()和values()Region 操作的结果。这是通过在本地内存中创建并行数据结构来完成的。这可招致显著开销大集合,所以设置
convert-returned-collections到false,如果你想为这些地区的业务禁用自动转换。
某些地区的业务(特别是那些使用Apache的Geode的专利Region.Entry,如: entries(boolean),entrySet(boolean)和getEntry()类型)没有针对AOP建议。此外,entrySet()方法(返回 a Set<java.util.Map.Entry<?, ?>>)也不受影响。
以下示例配置显示了如何设置pretty-print和
convert-returned-collections属性:
<gfe-data:json-region-autoproxy region-refs="myJsonRegion" pretty-print="true" convert-returned-collections="false"/>
如果GemfireTemplate模板被声明为 Spring bean,则此功能还可与操作无缝协作。目前QueryService不支持原生操作。
5.6.配置索引
Apache Geode 允许在区域数据上创建索引(有时也称为索引),以提高 OQL(对象查询语言)查询的性能。
在 Spring Data for Apache Geode 中,索引是用index元素声明的,如以下示例所示:
<gfe:index id="myIndex" expression="someField" from="/SomeRegion" type="HASH"/>
在 Spring Data for Apache Geode 的 XML 模式(也称为 SDG XML 命名空间)中,indexbean 声明不绑定到区域,这与 Apache Geode 的原生cache.xml. 相反,它们是类似于<gfe:cache>元素的顶级 元素。这使您可以在任何区域上声明任意数量的索引,无论它们是刚刚创建的还是已经存在的——这是对 Apache Geode 的原生cache.xml格式的重大改进。
一个Index必须有一个名字。您可以Index使用该name属性为该名称指定一个显式名称。否则,将使用 bean 定义的 bean 名称(即id属性的值)index作为Index名称。
的expression和from条款形式的主要部件Index,识别所述数据索引(即,在所识别的地区from子句)用什么样的标准沿(即,expression)用于索引的数据。本expression应以什么样的应用程序域对象字段在应用程序定义OQL的谓语使用的查询用来查询和查找存储在该区域中的对象。
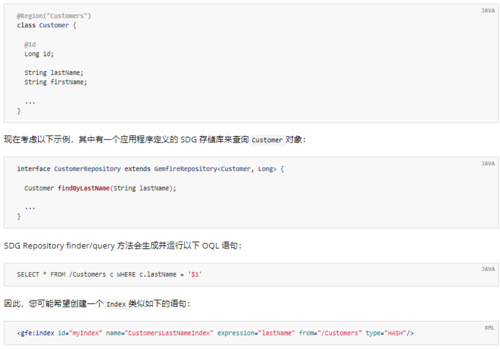
考虑下面的例子,它有一个lastName属性:
@Region("Customers")class Customer { @Id
Long id;
String lastName;
String firstName;
...
}现在考虑以下示例,其中有一个应用程序定义的 SDG 存储库来查询Customer对象:
interface CustomerRepository extends GemfireRepository<Customer, Long> { Customer findByLastName(String lastName);
...
}SDG Repository finder/query 方法会生成并运行以下 OQL 语句:
SELECT * FROM /Customers c WHERE c.lastName = '$1'
因此,您可能希望创建一个Index类似如下的语句:
<gfe:index id="myIndex" name="CustomersLastNameIndex" expression="lastName" from="/Customers" type="HASH"/>
该from子句必须引用有效的现有区域,并且是如何Index将 a 应用于区域。这不是特定于 Apache Geode 的 Spring Data。它是 Apache Geode 的一个特性。
该Index type可能是由Spring数据为Apache的Geode的定义了三种枚举值的一个 IndexType枚举: FUNCTIONAL,HASH,和PRIMARY_KEY。
每个枚举值对应于在实际创建(或“定义”——您可以在下一节中找到有关“定义”索引的更多信息)时调用的方法之一。例如,如果是,则 调用
QueryService.createKeyIndex(..)以创建.QueryService create[|Key|Hash]IndexIndexIndexTypePRIMARY_KEYKEY Index
默认值为FUNCTIONAL并导致QueryService.createIndex(..)调用方法之一。请参阅 Spring Data for Apache Geode XML 模式以获取完整的选项集。
有关 Apache Geode 中索引的更多信息,请参阅Apache Geode 用户指南中的“使用索引”。
5.6.1.定义索引
除了Index在 Spring 容器初始化时 Spring Data for Apache Geode 处理 bean 定义时预先创建索引,您还可以在使用define 属性创建它们之前定义所有应用程序索引,如下所示:
<gfe:index id="myDefinedIndex" expression="someField" from="/SomeRegion" define="true"/>
当define设置为true(默认为false)时,它实际上不会Index在那个时候创建。当 SpringApplicationContext被“刷新”时,或者换句话说,当 aContextRefreshedEvent由 Spring 容器发布时,所有“定义的”索引都是一次性创建的。Spring Data for Apache Geode 将自己注册ApplicationListener为ContextRefreshedEvent. 触发时,Apache Geode 的 Spring Data 调用
QueryService.createDefinedIndexes().
定义索引并同时创建它们可以提高创建索引的速度和效率。




