
概述
本文基于 “KubeSphere & Friends 2021 Meetup 北京站” 分享主要内容整理而来,详细内容建议观看视频,本文有一定删减。
作者:胡涛(Daniel),马上消费金融高级云平台研发工程师。
本次分享主要分为四个部分:
- 什么是 AI 中台
- 为何需要 KubeSphere
- KubeSphere 的引入
- 二次开发和参与社区
什么是 AI 中台
首先简单介绍一下背景,关于我们是谁?
马上消费金融股份有限公司(简称“马上消费”)是一家经中国银保监会批准,持有消费金融牌照的科技驱动型金融机构。截止 2020 年底,注册资本金达 40 亿元,注册用户已突破 1.2 亿,累计发放贷款超过 5400 亿元,累计纳税近 33 亿元,公司技术团队人数超过 1000 人。
我们的技术类部门架构大致如下:
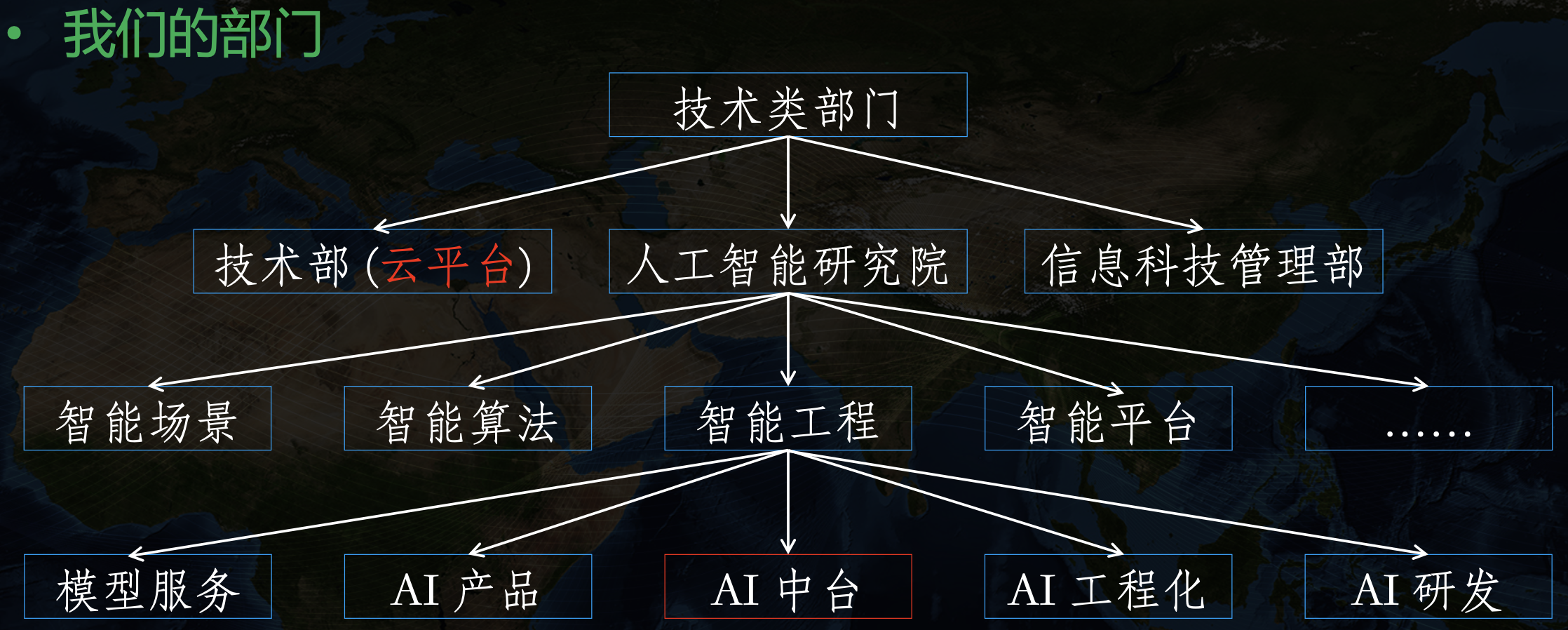
可以看到 AI 中台团队隶属于“人工智能研究院”大部门下,与负责“云平台”的技术部中间有一个很高的部门墙。也因此,AI 中台所需要的底层云计算相关技术并不能很好的依赖于技术部,两边有不同的考核机制、目标、痛点,所以 AI 中台团队需要自己搭建底层云平台,这也是我们引入 KubeSphere 的一个重要原因。
我们这边主要开发的产品如下,AI 中台是作为三大中台之一,在公司内部运行在金融云之上。但是由于 AI 中台需要考虑对外输出,而金融云暂时没有这个规划,所以 AI 中台也需要独立的云方面的解决方案,换言之 AI 中台本身必须是一个完整的容器云 + AI 架构。

目前产品主页大致长这样:
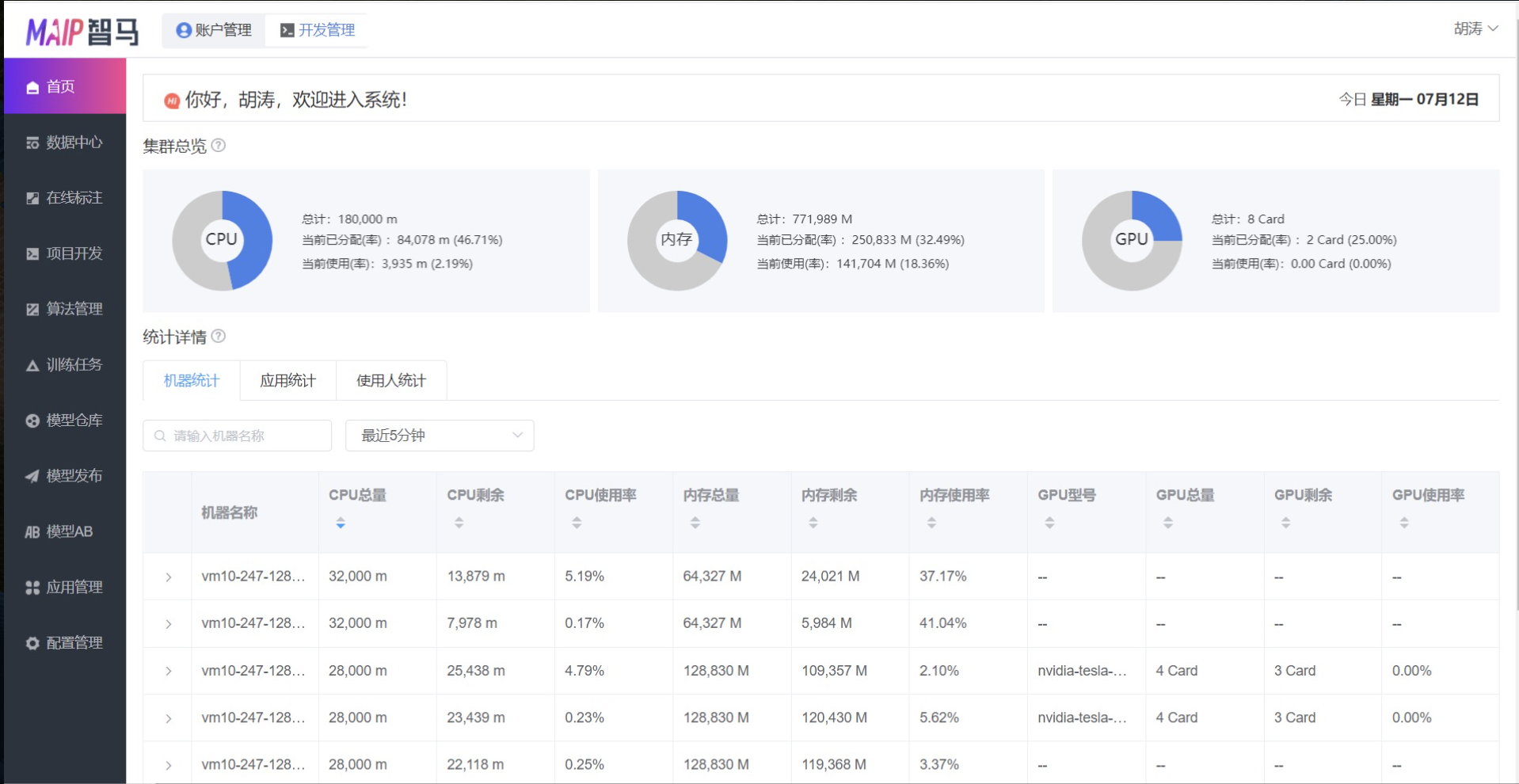
首页主要展示的是监控相关信息,这些都来自 Promethues。另外从左边可以看到我们的九大功能模块:数据中心、在线标注、项目开发、算法管理、训练任务、模型发布、模型 AB、应用管理等。监控信息相对来说还是比较粗糙,上面三个圈部分是集群纬度的整体信息,包括 CPU、内存、GPU 整体信息,下面是机器纬度、应用纬度、使用人纬度分别的汇总信息。另外我们也保留了原生的监控页面:
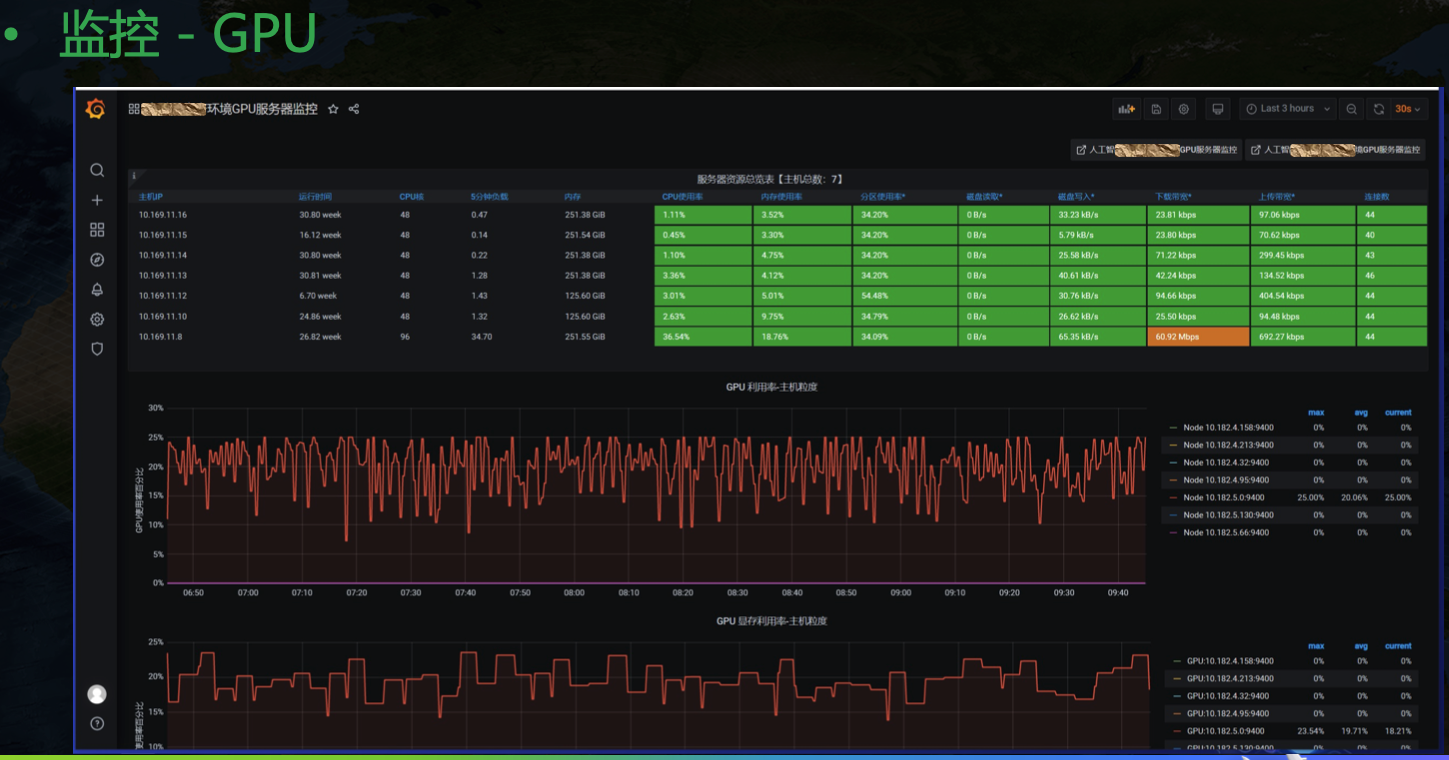
目前 grafana 社区并没有一个合适的 GPU 纬度展示模板,NVIDIA 也只给了一个主机纬度的相对粗糙的 Dashboard。目前我们用的 GPU Dashboard 是自己开发的。还有一个调用链纬度的监控:
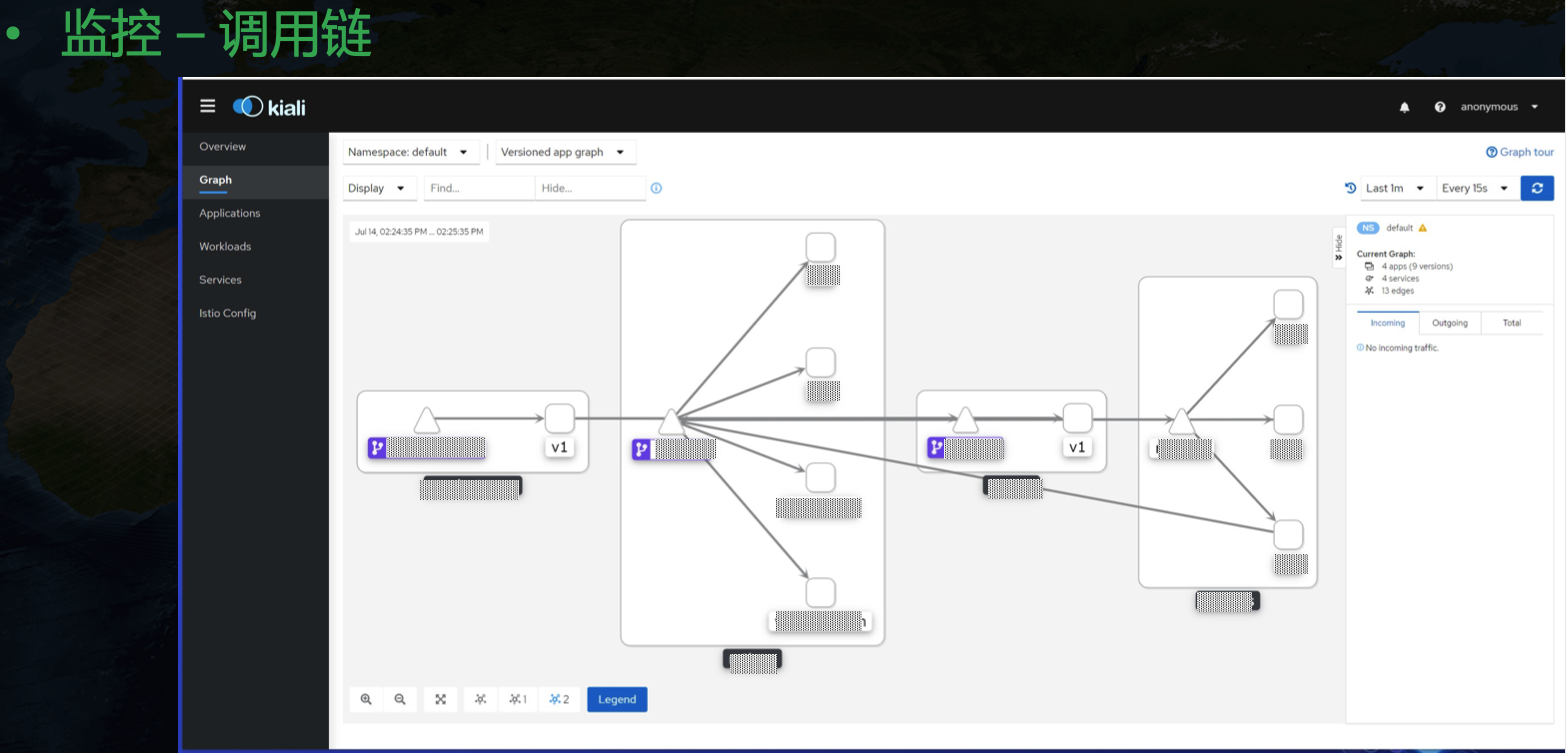
另外日志我们也是用的原生 kibana 来展示,对应的工具链是 Fluent Bit + Elasticsearch + Kibana。
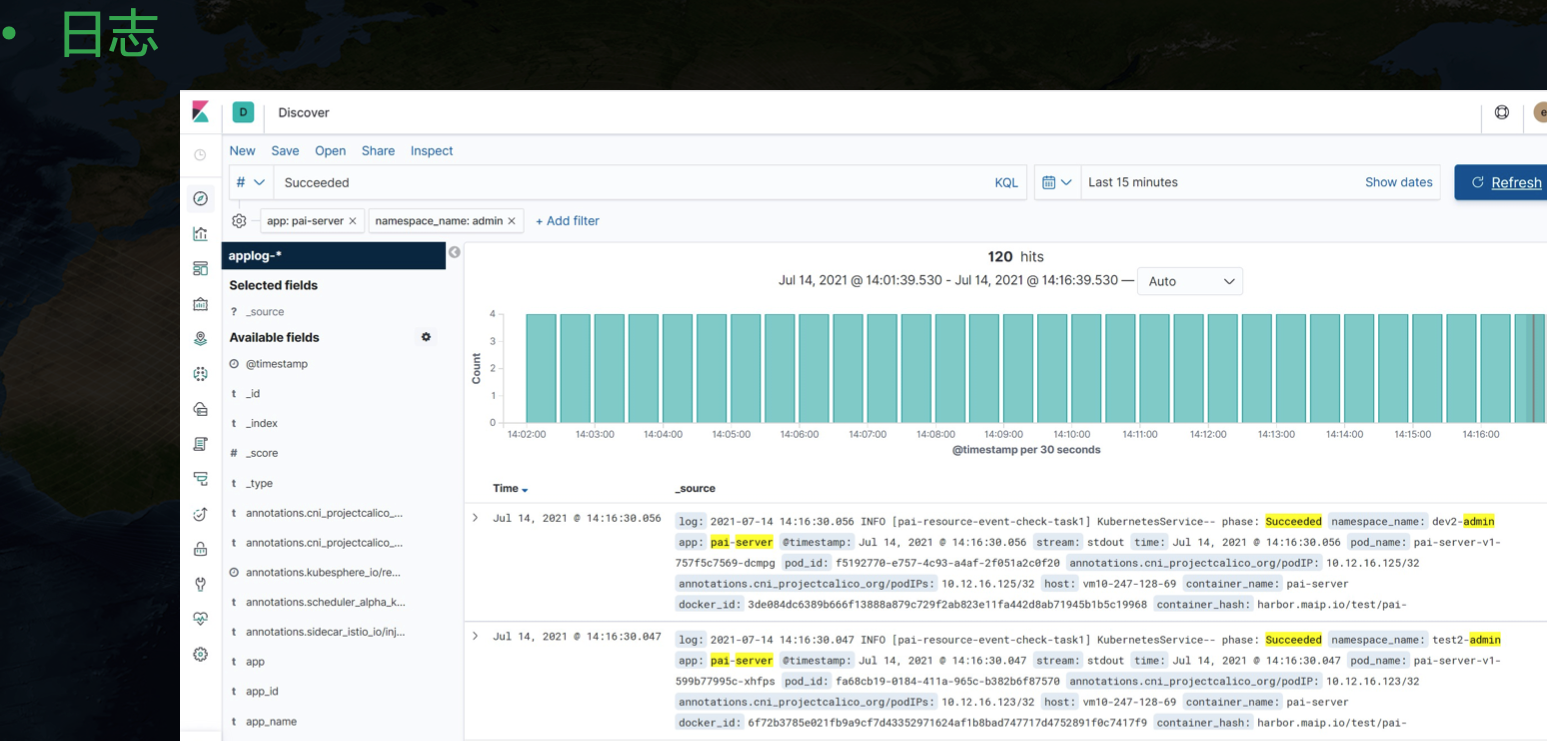
日志这里可以看到一个额外的信息,我们可以根据 app 纬度来聚合,也就是一个应用下的不同 Pod 产生的日志可以汇总展示。这里其实是简单地根据 pod 的 label 来实现的,将每个 Pod 打上应用相关的 label 信息,然后采集日志时将这个属性暴露出来,就能在展示时针对性汇总。在中台发布的应用有一个日志跳转按钮,转到 kibana 页面后会带上相关参数,实现该应用下全部日志聚合展示的功能。
到这里可以看到整个中台虽然看起来功能还算齐全,但是面板很多,日志监控和主页分别有各自的入口,虽然可以在主页跳转到日志和监控页面,但是这里的鉴权问题、风格统一问题等已经很不和谐。但是我们团队主打的是 AI 能力,人手也有限,没有太多的精力投入到统一 Dashboard 开发上,日志监控等虽然必不可少,但也不是核心能力。这也是引入 KubeSphere 的一个重要原因。后面还会详细谈到为什么引入 KubeSphere。
再介绍下整个中台的底层架构:
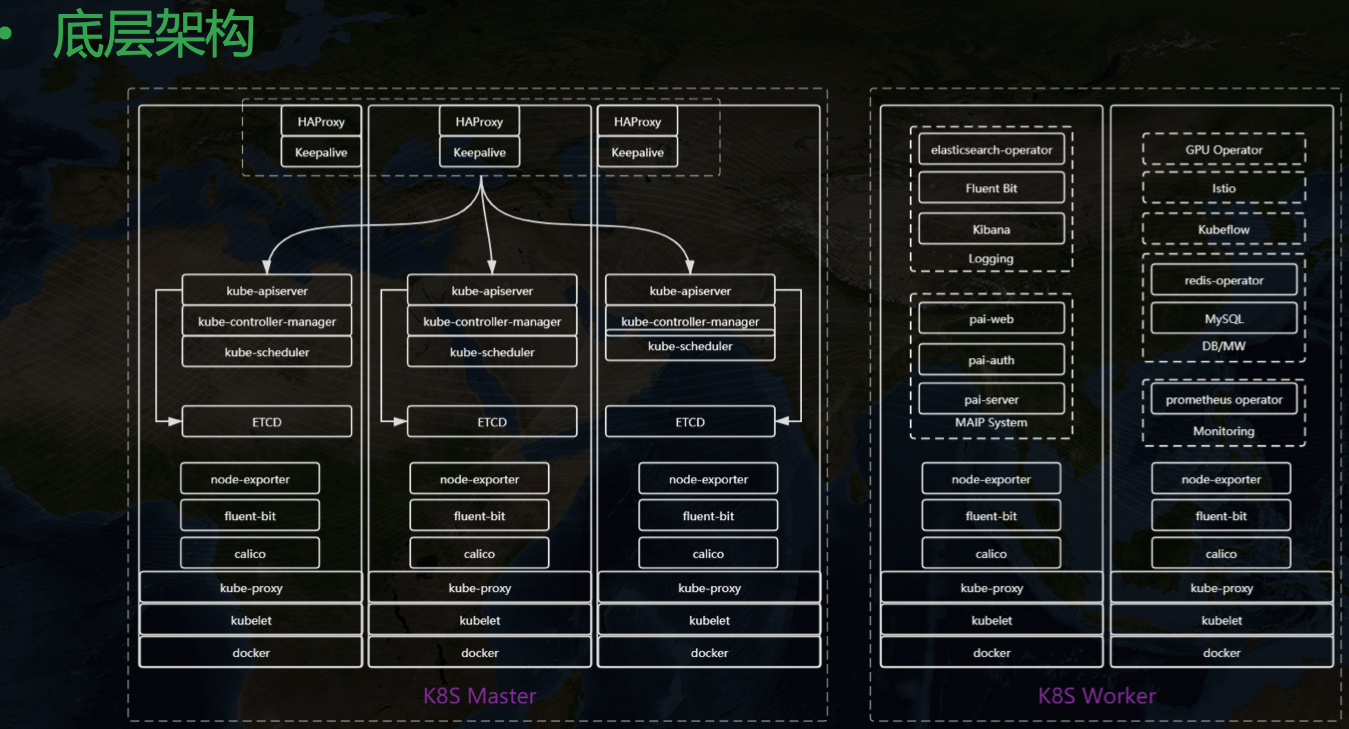
整个中台构建在 Kubernetes 之上,在引入 KubeSphere 之前大致长这样,三主多从。
另外在网络上我们做了三网隔离支持,也就是业务、管理、存储可以分别使用不同的网卡,假如用户现场有多张网卡。
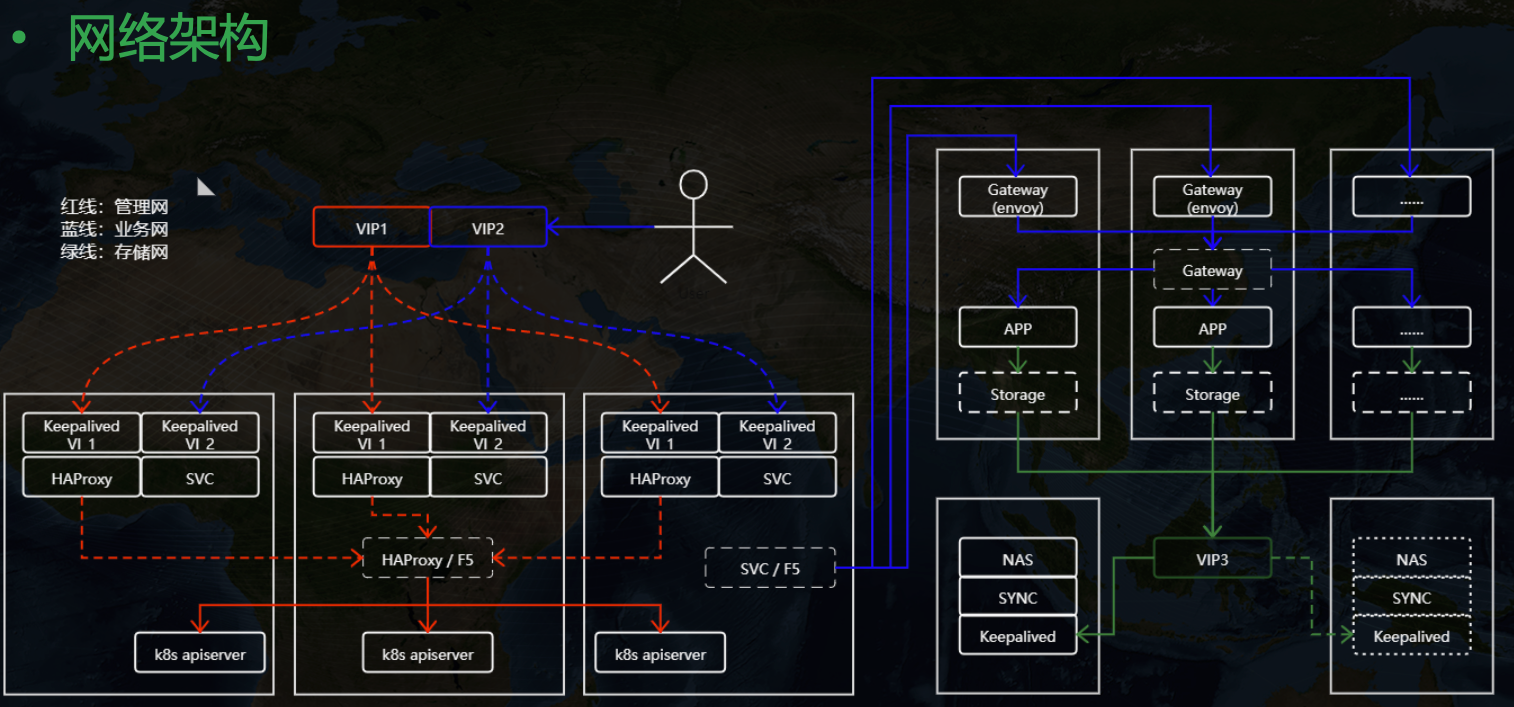
关于三网隔离这里不赘述,后面我会专门写一篇博文来介绍这里的实现细节。
为什么需要 KubeSphere
接下来聊一下为什么需要 KubeSphere。
我们使用 Kubernetes 会面临诸多问题与挑战,比如:
- 学习成本高:Kubernetes 引入了诸多新概念,要掌握 Kubernetes 达到生产落地的能力需要不少的学习时间,这里还会涉及到网络、存储、系统等方方面面知识,不是随便一个初级开发人员花时间就能掌握的。
- 安装部署复杂:目前虽然已经有了 kubeadm 等一系列半自动化工具,可以接近一键部署环境,但是要搭建高可用生产集群,还是需要花不少精力深入掌握工具的各种配置细节,才能很好落地应用。
- 功能组件选型复杂:要落地一套容器云并不是部署 Kubernetes 就够了,这里还有日志、监控、服务网格、存储等一系列相关组件需要落地实施,每一个方向都是涉及一系列可选方案,需要专门投入人力去学习、选型。
- 隐形成本高:就算部署了 Kubernetes,后期的日常运维也需要专业的团队,对于一般中小公司来说一个 Kubernetes 运维团队的人力成本也是不小的开支,很多时候花钱还招不到合适的人,往往会陷入部署了 Kubernetes,但是出问题无人能解决的尴尬境地,通过重装来恢复环境。
- 多租户模式实现复杂,安全性低:在 Kubernetes 里只有简单的 Namespace 隔离,配合 Quota 等一定程度上实现资源隔离,但是要 to C 应用还远远不够,很多时候我们需要开发一套权限管理系统来适配企业内专有的账号权限管理系统来对接,成本很高。
- 缺少本土化支持:Kubernetes 一定程度上可以称为云操作系统,类比于 Linux,其实 Kubernets 更像是 kernel,我们要完整使用容器云能力,要在 Kubernets 之上附加很多的开源组件,就像 kernel 上要加很多的开源软件才能用起来 Linux 一样。很多企业,尤其是国企,会选择购买 Redhat 等来享受企业级支持,专注于系统提供的能力本身,而不想投入太多的人力去掌握和运维系统本身。Kubernetes 本身也有这样的问题,很多企业并不希望额外投入太大的成本去使用这套解决方案,而是希望有一个类似 Redhat 系统的 Kubernetes 版本来简单化落地,而且希望免费。
而我们 AI 中台所面临的技术与挑战如下:

我们涉及的技术栈很广,AI 方向的,云计算方向的,还有工程开发的,也就是 Java + 前端等。但是我们的人力很稀缺,在云方向只有 2 个人,除了我之外另外一个同事擅长 IaaS 方向,在网络、存储等领域可以很好 cover 住。所以剩下的容器方向、监控日志等方向,在大公司可能每个方向一个团队,加一起大几十号人做的事情,这边只有我一个人了。所以我再有想法,有限的时间内也做不完一个平台。所以我也在寻找一个现成的解决方案,可以把自己解放出来,能够把精力投入到 AI 相关能力的建设上,比如模型训练等的 Operator 开发上,而不是整体研究日志监控组件和 Kubernetes 最佳部署实践等。
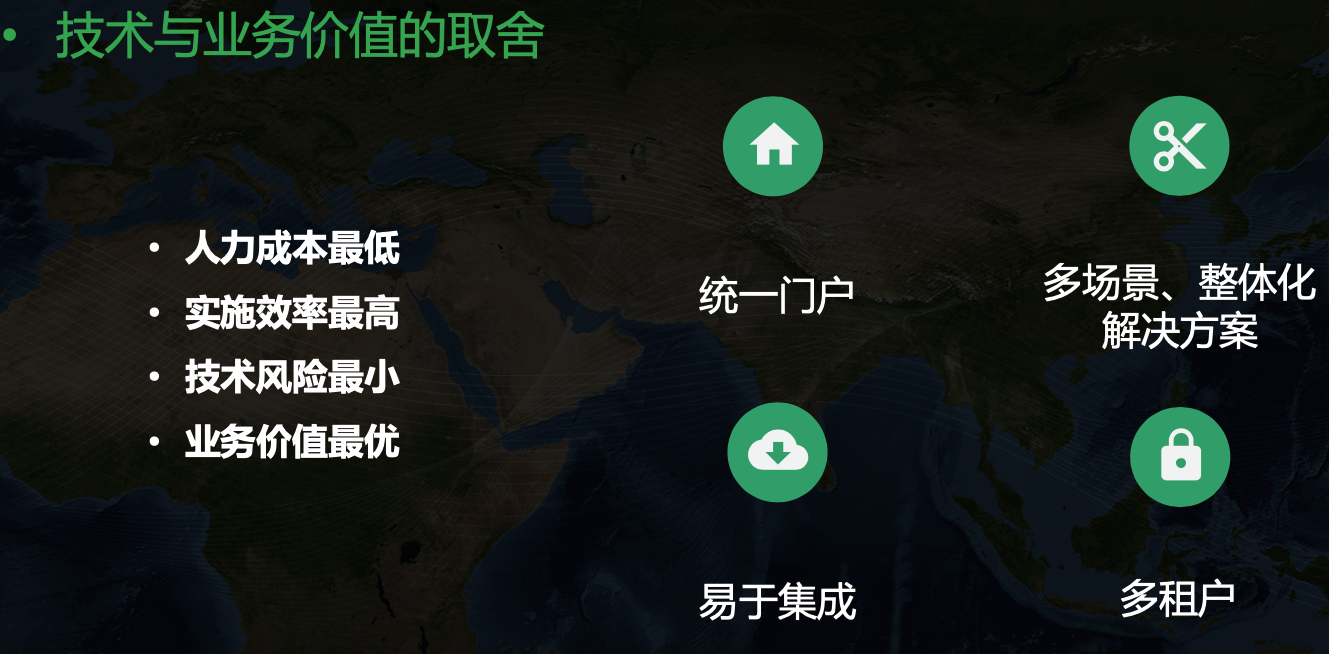
KubeSphere 提供的统一门户、多租户、多场景整体化解决方案正好能解决我的很多痛点。KubeSphere 的架构大致如下

不同于 OpenShift 的解决方案,KubeSphere 对 Kubernetes 没有侵入,而是基于 Operator 模式来拓展,这种方式也是我个人比较推崇的。
KubeSphere 的引入
KubeSphere 里组件不少,面对这样一个复杂软件,我的方式是通过思维导图来梳理里面的所有组件,然后最小化部署,看下集群里有些啥,然后可插拔组件一个个开启,看下多了哪些组件,这样一个个模块去梳理,最终实现对整个平台架构整体掌握的目的:
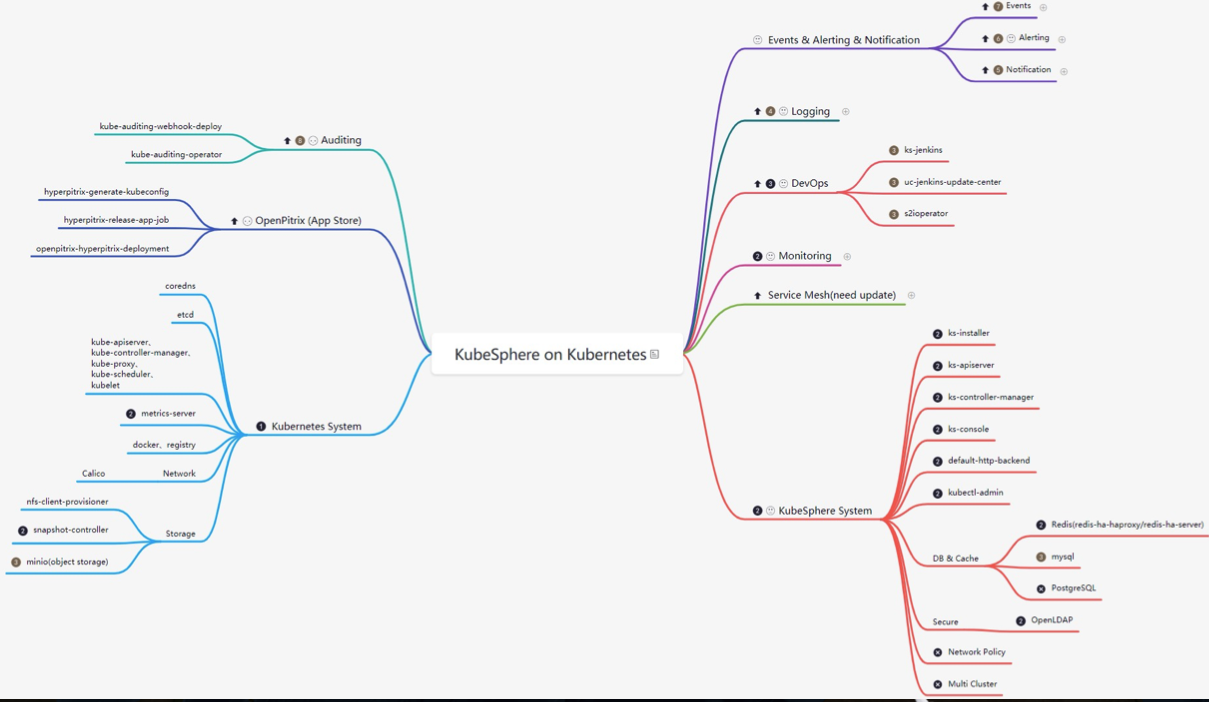
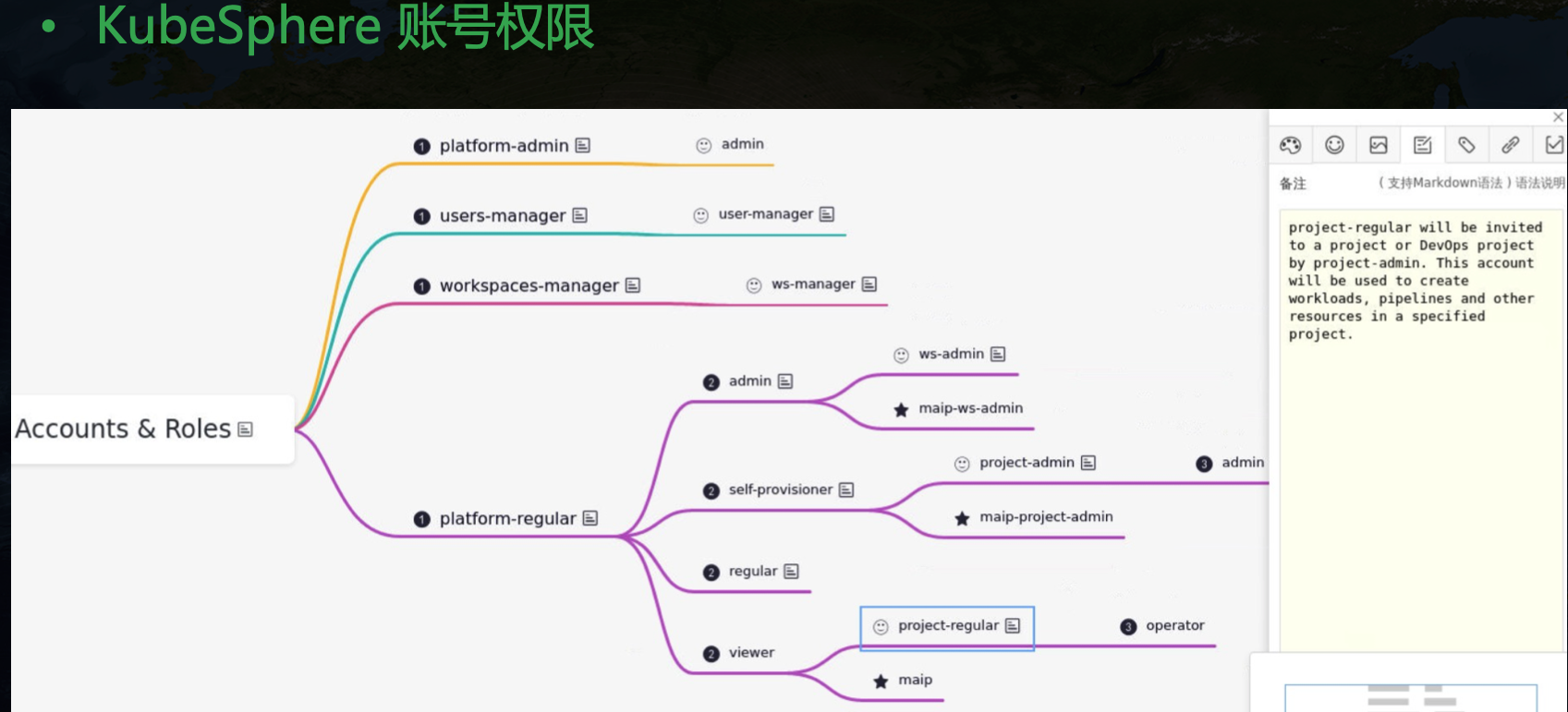
KubeSphere 页面如下:
后面介绍下 KubeSphere 的部署架构:
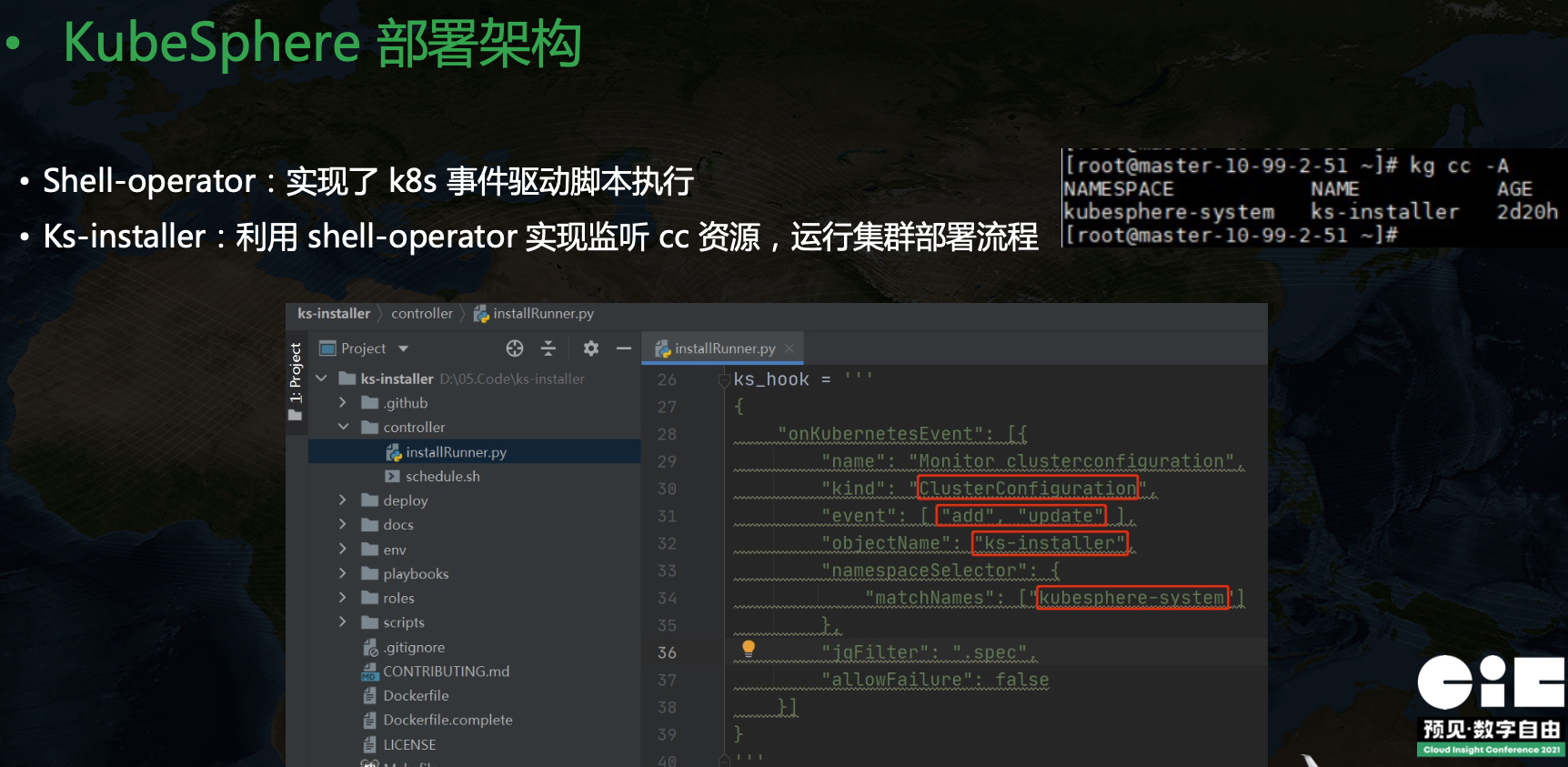
在 KubeSphere 里可以看到一个叫做 kubesphere-system/ks-installer 的资源,简写 cc,全称是 ClusterConfiguration,里面维护了集群的配置信息。我们在 ks-installer 里可以看到一个 ks-hook 配置,里面定义了 kind ClusterConfiguration,event add update,objectName ks-install,namespace kubesphere-system 等信息,这里也就是告诉 shell-operator 当 cc 发生变更的时候要触发相关代码执行。ks-installer 的核心原理是利用 shell-operator 来监听 cc 资源的变更,然后运行集群部署流程。
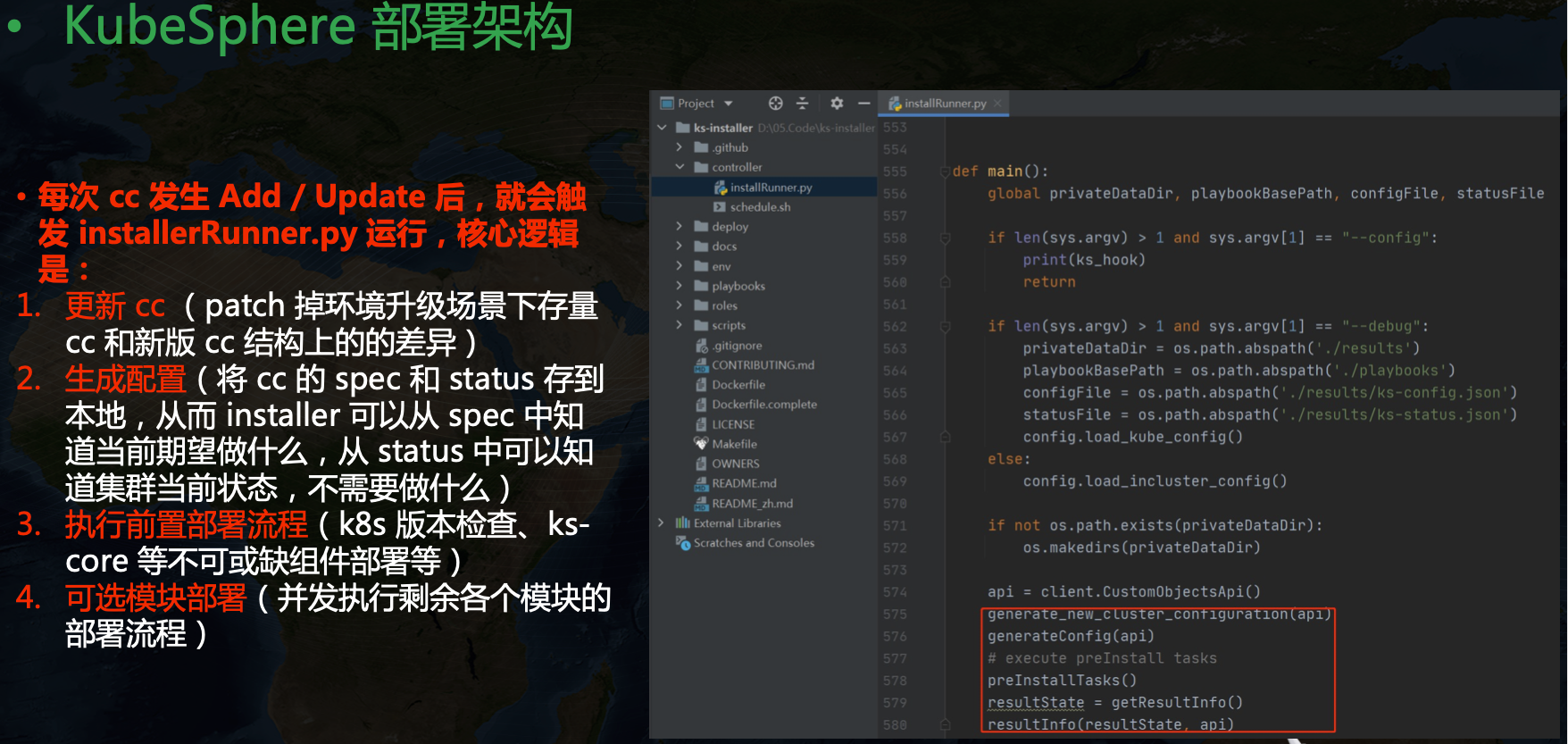
每次 cc 发生 Add / Update 后,就会触发 installerRunner.py 运行,核心逻辑是:
- 更新 cc (patch 掉环境升级场景下存量 cc 和新版 cc 结构上的差异)
- 生成配置(将 cc 的 spec 和 status 存到本地,从而 installer 可以从 spec 中知道当前期望做什么,从 status 中可以知道集群当前状态,不需要做什么)
- 执行前置部署流程(K8s 版本检查、ks-core 等不可或缺组件部署等)
- 可选模块部署(并发执行剩余各个模块的部署流程)
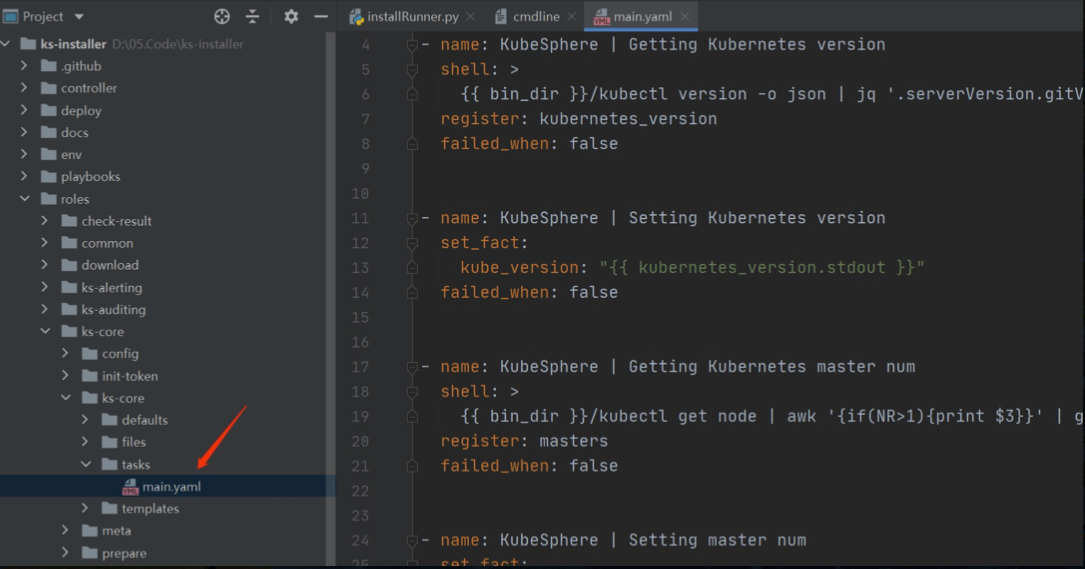
然后再看下为什么配置里的变量可以被 ansible 识别,如下所示,在 env 里指定里 ks-config.json 和 ks-status.json 两个文件,ks-installer 运行的时候会将 cc 的 spec 和 status 分别存到这两个文件里,这样 ansible 执行的时候就可以获取到集群的期望状态和实际状态了。
每个 playbook 的入口逻辑都在 main.yaml 里,所以接着大家可以在每个模块里通过 main.yaml 来具体研究每个模块的部署流程,串在一起也就知道了整个 KubeSphere 是怎么部署起来的了。
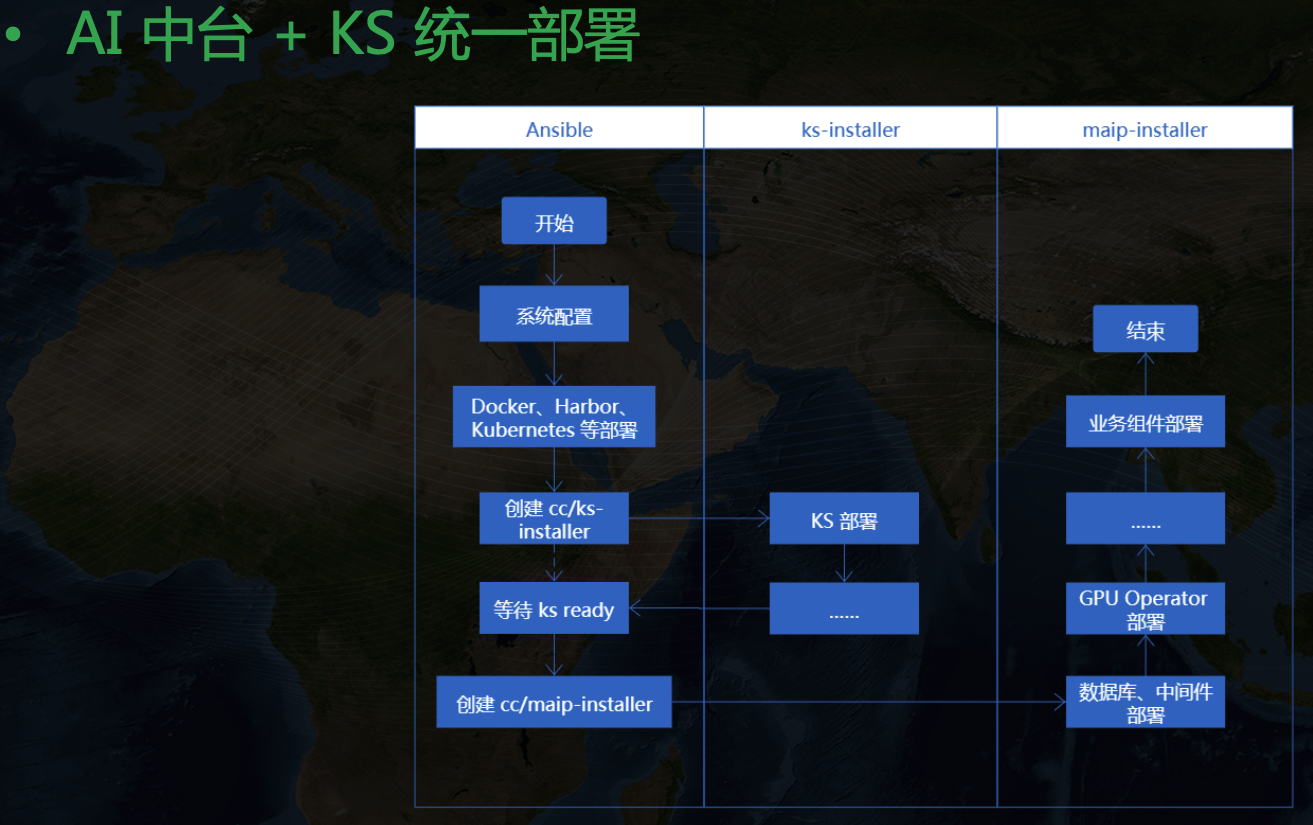
然后 KubeSphere 和中台本身的一堆组件怎么一起部署呢?
我们也参考 KubeSphere 的部署模式,加了一个 mail-installer 的 cc,然后按照下面流程来完成整个中台的部署:
二次开发与参与社区
接着聊下参与社区的问题。

对于新手推荐看下下面两个资料,里面有一些很好的前人总结,可以避免一些不必要的坑。
很多人在玩社区的过程中可能会有如下一些问题:
- 不擅长英语描述问题怎么办?
- 提了 Issue 没人理怎么办?
- Pr 没有人给 Review 怎么办?
- 与 Reviews 意见分歧怎么办?
最后针对这些问题聊下我的一些思考。
- 不擅长英语描述问题怎么办?
其实很多开源社区别看上面都是英文,背后有相当比例的中国人飙“中式英语”,你勇敢去说,各种语法错误其实一点关系也没有,互相能理解意思,交流的目的也就达到了。另外借助谷歌翻译等平台,其实有个一两千词汇量就完全够用了,在开源社区没有必要追求完美英语。
- 提了 Issue 没人理怎么办? Pr 没有人给 Review 怎么办?
社区是一个异步协作等过程,和在公司里团队开发不一样,互相喊一声就能彼此听见,及时反馈。参与社区的人都是手上有自己的本职工作,很多时候两三天上 Github 看一下也无可厚非。如果你不是很着急,还是可以耐心多等几天。如果确实有需要,也可以给相关人员发个邮件,或者在微信群等及时通讯途径去艾特对应人员,不过不是很推荐。
- 与 Reviews 意见分歧怎么办?
有时候玩开源就是这样,大家有自己不同的想法,谁也说服不了谁。一般大家产生分歧的是两个都能满足需求的实现方式哪个更优,其实满足需求的方案都是可接受的方案,如果你能说服 reviewer,这也是一种能力,如果不能,就接受另外一种方式,比较也是实现需求了,能用就行。不要因为这种“争辩”而对开源活动失去信心,协作开发本身就充满了“争论”与“妥协”,不会一切完全按照某个人的意愿走下去。




