

Kafka成长记的前4节我们通过KafkaProducerHelloWorld分析了Producer配置解析、组件组成、元数据拉取原理。
但KafkaProducerHelloWorld发送消息的代码并没有分析完,我们分析了如到了如下图所示的位置:
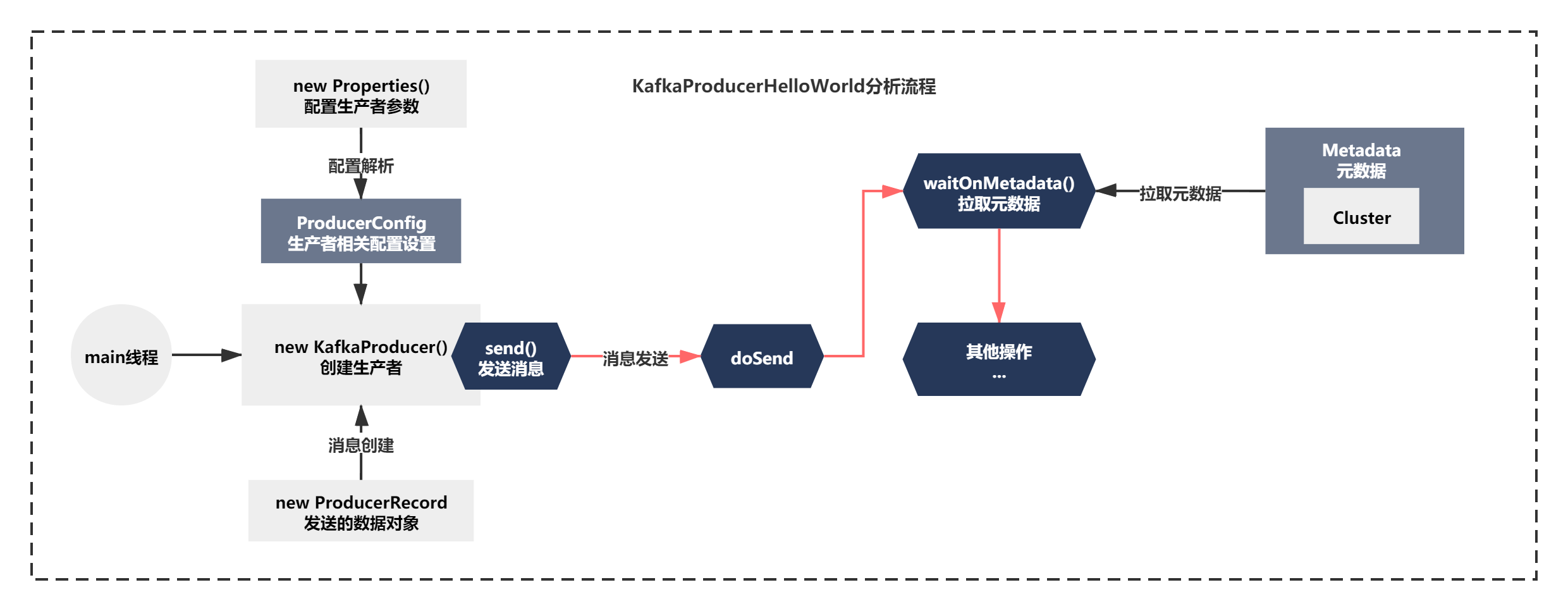
接下来,我们继续往下分析,这一节我们主要分析下发送消息的初步序列化和分区路由源码原理。
自定义消息的初步序列化的方式
在producer.send()执行doSend()的时候,waitOnMetadata拉取元数据成功之后脉络是什么呢?
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
// first make sure the metadata for the topic is available
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);
long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs);
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer");
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer");
}
int partition = partition(record, serializedKey, serializedValue, metadata.fetch());
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize);
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
if (this.interceptors != null)
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (Exception e) {
throw e;
}
//省略其他各种异常捕获
}
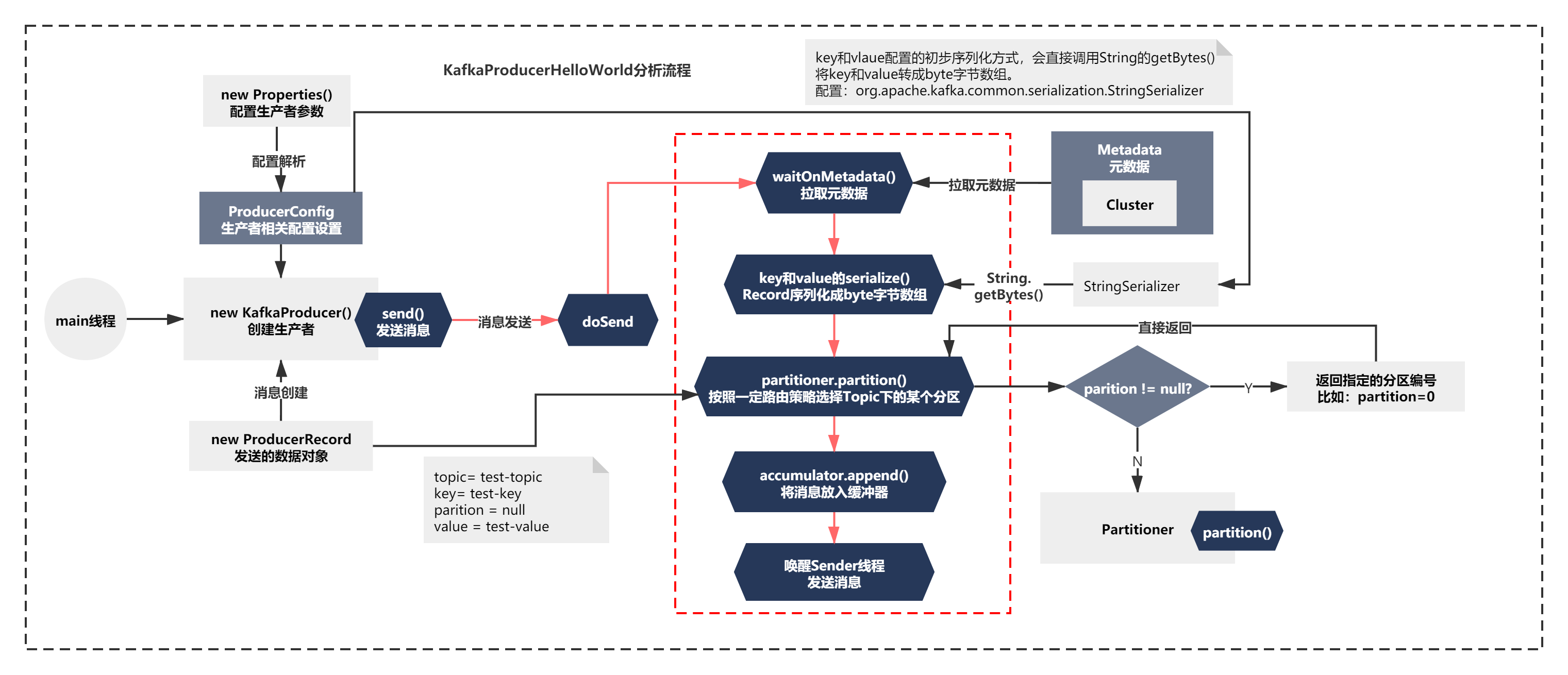
主要脉络就是:
1)waitOnMetadata 等待元数据拉取
2)keySerializer.serialize和valueSerializer.serialize,很明显就是将Record序列化成byte字节数组
3)通过partition进行路由分区,按照一定路由策略选择Topic下的某个分区
4)accumulator.append将消息放入缓冲器中
5)唤醒Sender线程的selector.select()的阻塞,开始处理内存缓冲器中的数据。
整个脉络如下图:
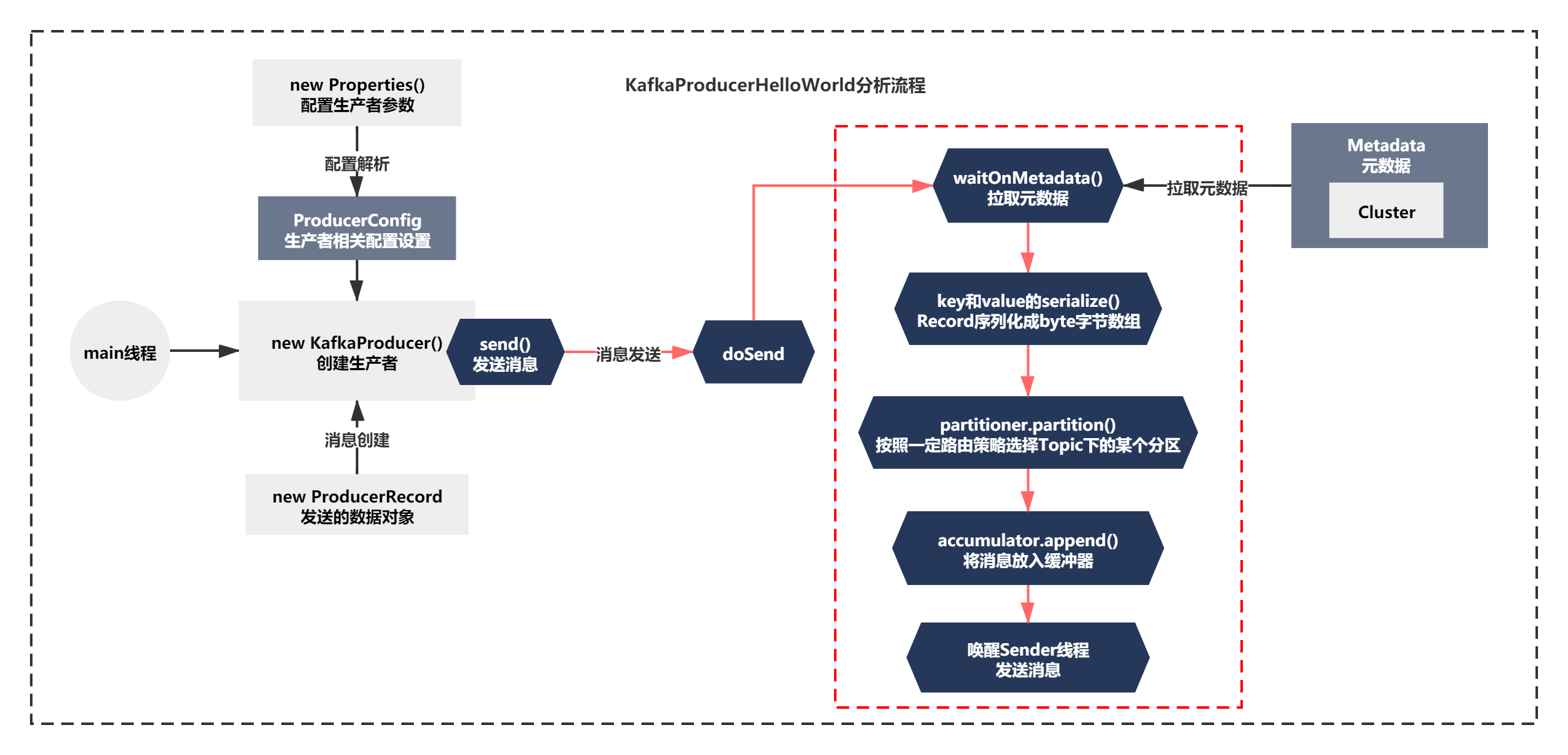
第二步执行的脉络是使用自定义序列化器,将消息转换为byte[]数组。我们就来先看下这块的逻辑。
首先第一个问题就是,自定义的消息序列化器哪里来的?其实是在配置参数中设置的。还记得KafkaProducerHelloWorld代码么?
// KafkaProducerHelloWorld.java
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "mengfanmao.org:9092");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
producer.send(record).get();
Thread.sleep(5 * 1000);
producer.close();
}
在之前的KafkaProducerHelloWorld.java中,我们起初并没有设置序列化参数。结果发消息失败,提示了如下堆栈:
Exception in thread "main" org.apache.kafka.common.config.ConfigException: Missing required configuration "key.serializer" which has no default value.
at org.apache.kafka.common.config.ConfigDef.parse(ConfigDef.java:421)
at org.apache.kafka.common.config.AbstractConfig.<init>(AbstractConfig.java:55)
at org.apache.kafka.common.config.AbstractConfig.<init>(AbstractConfig.java:62)
at org.apache.kafka.clients.producer.ProducerConfig.<init>(ProducerConfig.java:336)
at org.apache.kafka.clients.producer.KafkaProducer.<init>(KafkaProducer.java:188)
at org.mfm.learn.kafka.KafkaProducerHelloWorld.main(KafkaProducerHelloWorld.java:20)
上面堆栈的信息有没有很熟悉? 提示的那些类不正是我们之前研究配置解析相关的源码类么?ProducerConfig、AbstractConfig、ConfigDef实在是太熟悉了。
打开源码ConfigDef,你会发现ConfigDef在解析配置文件时,没有序列化配置会使得new KafkaProducer()这一步直接抛出异常,消息发送失败。
到这里你是不是可以略微体验出来,阅读源码的好处之一了?
接着你补充配置下序列化参数如下:
// KafkaProducerHelloWorld.java
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put("bootstrap.servers", "mengfanmao.org:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
producer.send(record).get();
Thread.sleep(5 * 1000);
producer.close();
}
消息发送成功!我们补充设置的序列化器是客户端jar包中默认提供的StringSerializer。既然有了消息序列化器,我们就来看看它是如何序列化的key和value的。
我们将之前第二步核心简化,其实就是如下代码:
//KafkaProudcer.java#doSend
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "test-key", "test-value");
keySerializer.serialize(record.topic(), record.key());
valueSerializer.serialize(record.topic(), record.value());
//StringSerializer.java
public byte[] serialize(String topic, String data) {
try {
if (data == null)
return null;
else
return data.getBytes(encoding);
} catch (UnsupportedEncodingException e) {
throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + encoding);
}
}
可以看到StringSerializer的序列化的方式非常简单,就是调用String原始的getBytes()方法而已。(PS:第一个参数竟然没有使用…)
序列化真的只是到这里为止了么?肯定不是,这个bytes[]数组的数据肯定最终需要通过网络发送出去的,这里只是算是初步的一次序列化而已。消息之后最终的序列化,包括具体的格式,我们之后研究Kafka使用原生Java NIO解决粘包和拆包问题时在深入研究。
起码,这里我们可以得到如下的图了:
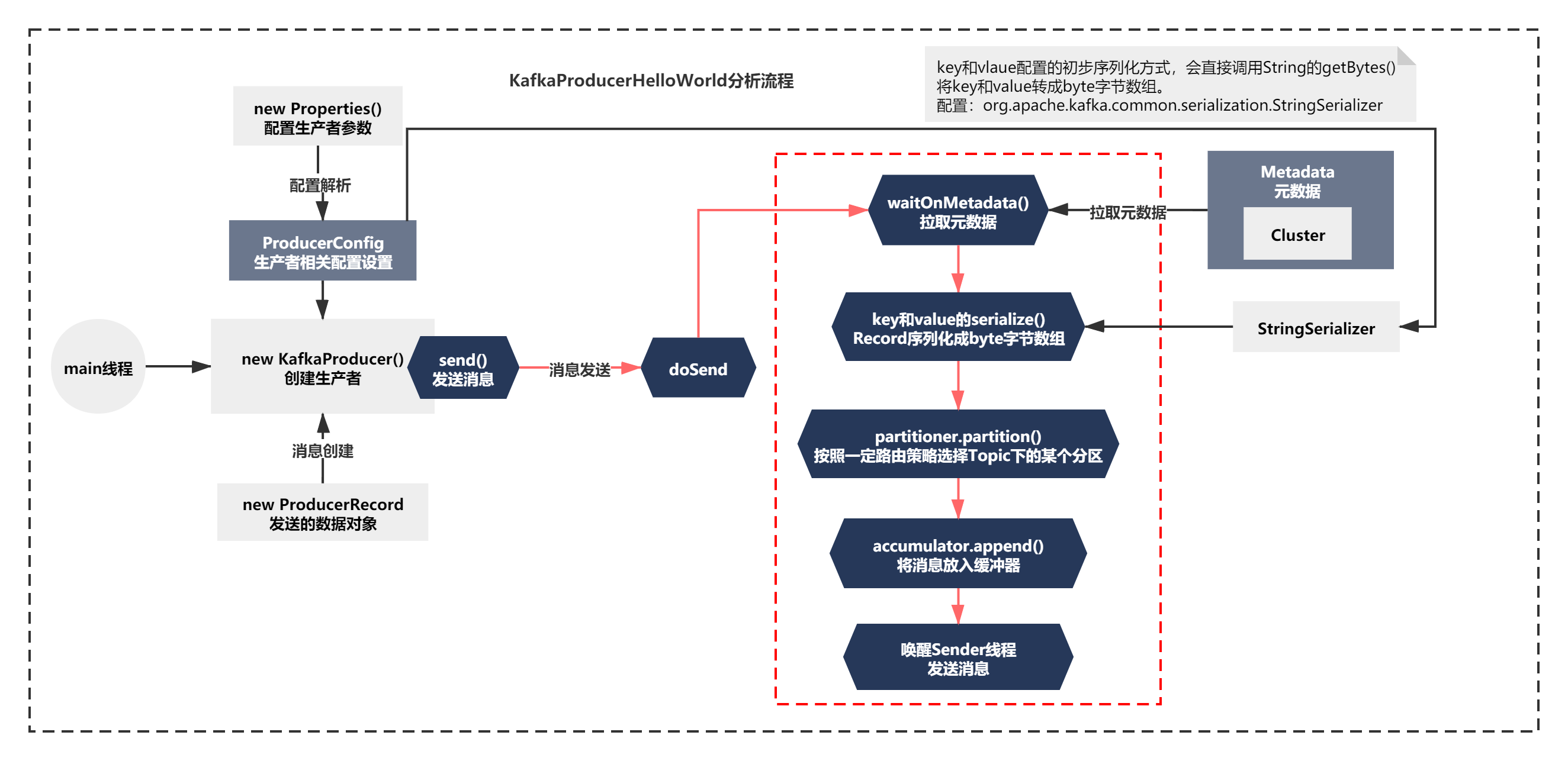
消息基于Topic分区路由源码原理
发送消息时,拉取到元数据、初步序列化消息为byte[]数组。之后就是通过元数据信息进行路由,选择一个Topic对应的Partition发送消息了。在路由选择发送消息的分区时,用到了Metadata中的Cluster元数据,这里带大家回顾下它的结构。
Cluster类的元数据内存结构回顾
**List:**Kafka Broker节点,主要是Broker的ip、端口。
**Map nodesById,**key是broker的id,value是Broker的信息Node
**Map partitionsByTopic:**每个topic有哪些分区,key是topic名称,value是分区信息列表
Map availablePartitionsByTopic,每个topic有哪些当前可用的分区,key是topic名称,value是分区信息列表
**Map partitionsByNode,**每个broker上放了哪些分区,key是broker的id,value是分区信息列表
**unautorhizedTopics:**没有被授权访问的Topic的列表,如果你的客户端没有被授权访问某个Topic,消息队列的权限控制用的很少,这个几乎可以忽略。
你可以断点,看下数据,如下所示:
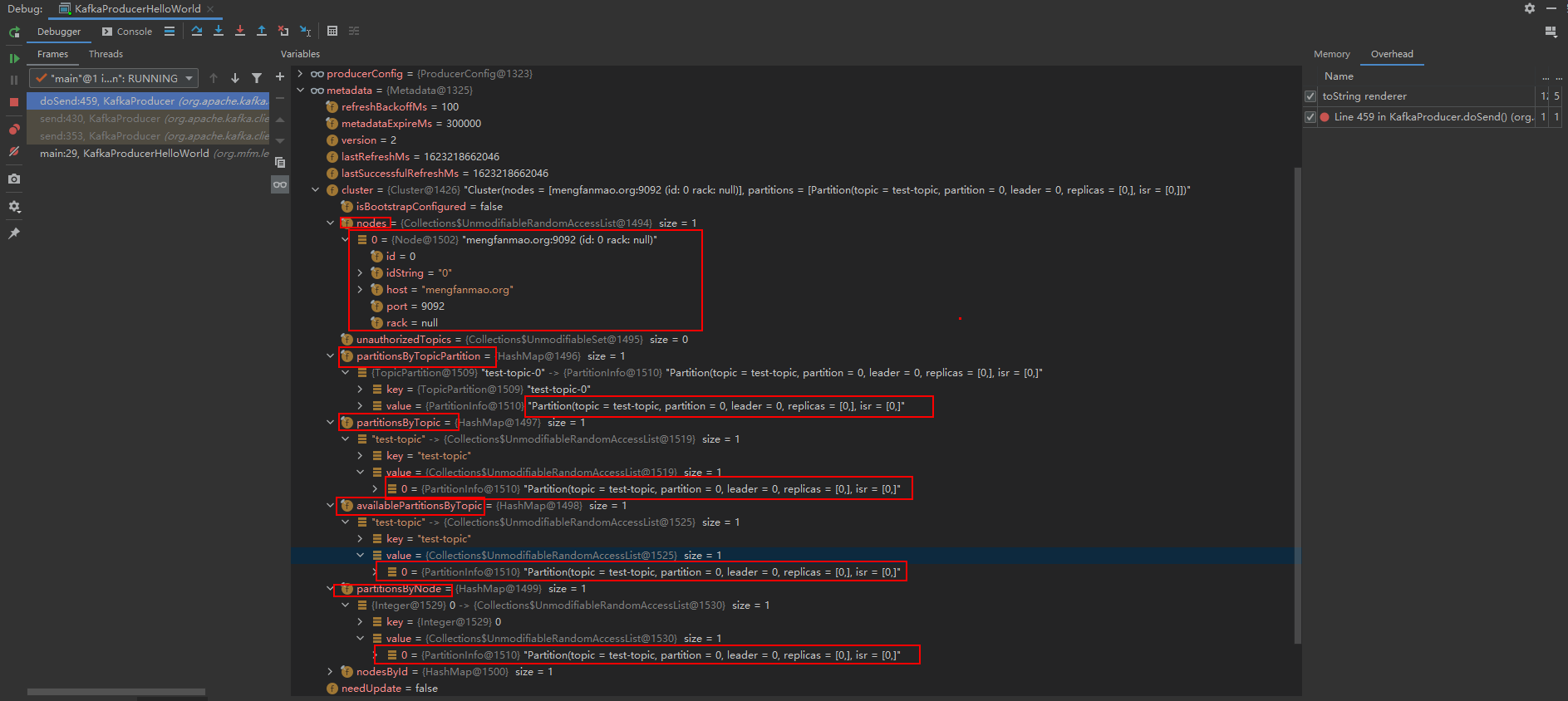
对集群元数据,你可以发现,根据不同的需求、使用和场景,采用不同的数据结构来进行存放,kafka Producer设计了不同的数据结构,其实很多时候我们是可以学习用类似这种思路写代码的。
回顾了元数据之后,客户端肯定可以根据元数据信息进行路由了。那么是如何路由的呢?代码如下:
// KakfaProducer.java
private final Partitioner partitioner;
//#doSend()
int partitionpartition = partition(record, serializedKey, serializedValue, metadata.fetch());
//#partition()
private int partition(ProducerRecord<K, V> record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
if (partition != null) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(record.topic());
int lastPartition = partitions.size() - 1;
// they have given us a partition, use it
if (partition < 0 || partition > lastPartition) {
throw new IllegalArgumentException(String.format("Invalid partition given with record: %d is not in the range [0...%d].", partition, lastPartition));
}
return partition;
}
return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue,
cluster);
}
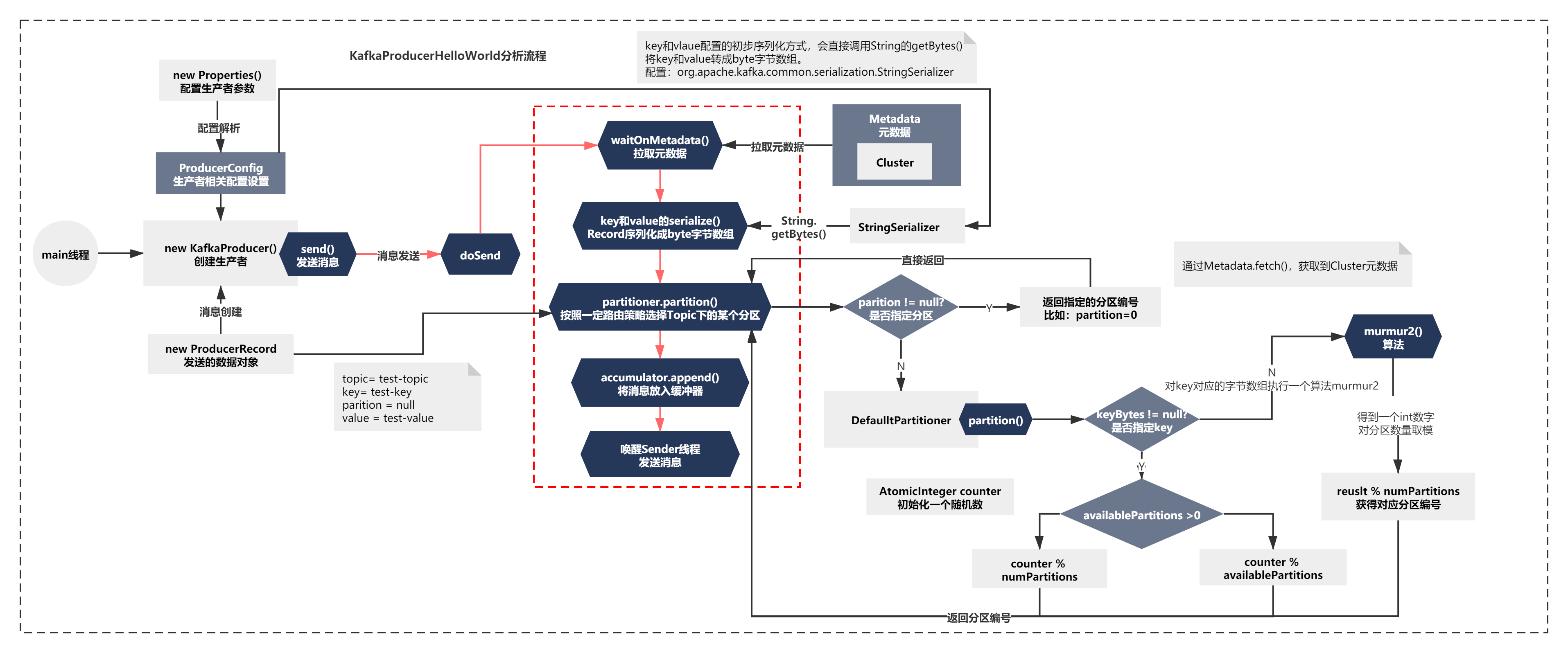
这段方法脉络很简单,主要就是根据record是否指定分区partition决定:
1)如果发送的消息record指定了分区,使用元数据信息Cluster校验后,路由后的分区就是指定的分区编号。
2)如果发送的消息record没有指定分区,使用一个Partitioner组件partition方法路由决定分区编号。
如下图:
上一节我们说过ProducerRecord的时间戳和分区是可选的,默认都是null。也就是说,默认会走到Partitioner组件partition这个分支。
可是问题就来了。Partitioner这个是什么时候初始化的?
由于partitioner这个是KafkaProducer的一个成员变量,你可以搜索下它。你会发现:
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
//省略其他代码...
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
//省略其他代码...
}
原来是在构造函数时候初始化的,它其实就是通过配置解析得到的。并且有一个默认值DefaultPartitioner。
知道了这个之后,我们来看看默认的话是如何路发送的消息呢?
//DefaultPartitioner.java
private final AtomicInteger counter = new AtomicInteger(new Random().nextInt());
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
这个方法脉络主要是:
1)从元数据Cluster中的map获取topic下对应的所有分区和分区数量
2)发送消息如果没有指定key,则从一个随机数开始,每次通过AtomicInteger递增+1,对分区数量或者可用分区大小取模,获得对应的分区编号
3)发送消息如果指定key,会对key对应的字节数组执行一个算法murmur2,得到一个int数字,之后对分区数量取模,获得对应分区编号
整个过程如下图所示:
通过上面的路由策略,你可以发现,kafka发送的消息,哪怕只是指定了topic都是可以的。不需要指定key和partition。不过这样可能会导致消息乱序。
至于如何保证kafka发送消息的顺序性,除了指定分区和key外,其实还需要其他的配置,比如InFlightRequest的size默认是5,需要设置为1,否则重试的时候也会导致消息乱序,这些我们后面会分析到的。
小结
今天我们主要探索了消息的初步序列化方式、消息的路由策略。我们简单小结下:
1)Kafka消息的初步序列化必须通过配置参数指定,一般使用StringSerializer,不指定会导致发送消息失败
2)Kafka发送的消息,Topic必须指定,而Topic下的key和partition可选。
默认的分区路由的策略,支持三种,指定分区,指定分区key,或者不指定分区key
a.同时指定或者只指定partition,由于parttition路由的优先级高于key,会根据指定的parttition编号直接路由消息。
b.如果只是指定key,会对key对应的字节数组执行一个算法murmur2,得到一个int数字,之后对分区数量取模,获得对应分区编号
c.如果都不指定,则从一个随机数开始,每次通过AtomicInteger递增+1,对分区数量或者可用分区大小取模,获得对应的分区编号
这一节的知识比较轻松,不知道大家掌握的怎么样了。随着对KafkaProducer的分析,我们已经,慢慢揭开了它神秘的面纱了。后面两节我们一起来分析下发送消息的内存缓冲器的原理,如何分配内存区域,队列机制+batch机制如何将消息批量发送出去。在之后再分析下,Kakfa如何解决Java 原生NIO中的拆包和粘包的问题。基本Producer的源码原理就研究的差不多了。
我们下一节再见!





