
1. 流量复制回放
-
流量复制的作用
在开发新需求的过程中,我们可能会对应用进行重构和拆分,很难做到不改动老逻辑,只要有改动就有可能会出现问题。如果比较严谨的话,在开发完成后,会重新将 TestCase 都跑一遍,并同时补充新功能的 TestCase。
如果是小改动的业务需求,这种做法一般不会出现大的问题。但对于大改动的应用,比如很多基础逻辑都被改动过,这时候如果还是通过已有的 Case 去做覆盖验证,很难保证应用上线后不出现故障,因为线上运行的真实环境要复杂很多, TestCase是很难覆盖所有细节场景。
因此最好的方式就是用线上流量来验证,但是直接把新应用直接上线肯定是不行的,这个时候我们可以先把线上一段时间内的请求参数和响应结果保存下来,然后把这些请求参数在新改造的应用里重新跑一遍,这就间接达到了使用线上流量测试的效果,通过流量复制,在不影响线上服务稳定性的情况下面, 能够有效进行测试验证,最大限度的保障了服务的稳定性。
-
RPC应用中如何支持流量复制
常见的方案有很多种,比如基于TcpCopy的Dubbo服务引流、或者通过Nginx的Mirror模块来实现流量复制。但在线上环境要安装使用这些工具,需要运维团队把工具安装到应用实例里面,然后再按照需求配置好才能使用。如果觉得整个过程较为繁琐而且不利维护的话,那么可以在RPC的功能设计上去实现流量复制。
RPC内部如何去实现流量复制呢?
我们在 RPC 通讯当中, 可以很方便地拿到每次请求的出入参数, 这个时候可以通过异步线程,将这些出入参数旁录下来,并且将结果暂存或做持久化处理,这样就完成了流量的录制功能。
接下来, 就是把这些请求参数转发到我们要回归测试的应用里面。在 RPC 中,我们只需要模拟一个应用调用方,把刚才流量录制的请求参数重新发送一遍到回归测试的应用里面,这个时候大家可能会发现, 流量是先录制再回放, 如何完全模拟线上实际的高并发场景呢 ? 重点就在于流量录制的数据存储结构, 我们可以采用先进先出的队列, 保障有序性, 同时在队列里面可以再采用集合或是MAP结构数据来记录实际的请求信息,根据实际请求时间归并存储, 这样就能够有效模拟线上的高并发场景。
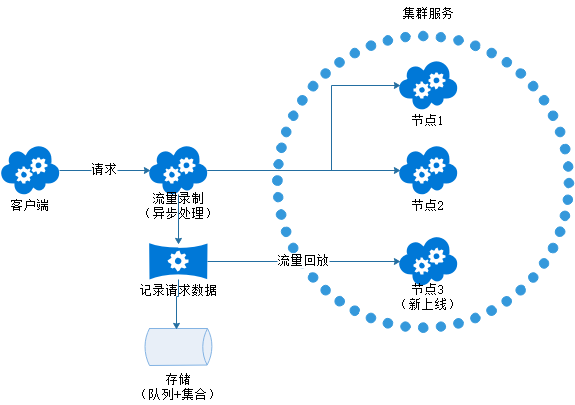
相对其它基于第三方工具实现的流量回放方案,我们在 RPC 里面内置的流量回放功能,虽然耦合性较强(在设计实现时, 要尽量避免对现有业务的影响),但使用起来会更加方便,并且我们还可以做更多定制,比如在线启停、方法级别录制等个性化需求。流量复制不仅可以用于功能性测试, 还能做更为真实的压力测试,甚至可以实现数据恢复功能。

2. 动态分组
-
为什么需要动态分组?
在调用方复杂的情况下,如果还是让所有调用方都调用同一个集群的话,很有可能会因为非核心业务的调用量突然增长,导致整个集群变得不可用。为了避免这种情况,我们需要把整个大集群根据不同的调用方来划分出不同的小集群来,从而实现调用方流量隔离的效果,保障业务之间不会互相影响。
-
如何分组?
如何对整个集群的划分分组,最理想的情况就是给每个调用方都分配一个独立的分组,对于服务提供方来说要维护这些关系还是比较困难。因此实际在给集群划分分组的时候,一般会选择性地合并一些相同性质的调用方到同一个分组里, 这就需要我们去全面评估考虑, 实现合理分配合并。
每个项目的业务与环境都存在差异, 这个没有统一标准。但我们可以按照以下原则进行分组:
> 按照应用的重要级别来划分,让非核心业务应用跟核心业务应用划分在不同分组内,核心应用之间也可以再做划分, 比如按照不同功能划分不同分组。按照解耦,分离式的原则去做划分,但是并非越细越好,太过细致会带来较大的维护量,需要做好权衡。
接下来就是给每个分组分配相应的机器数量。如何计算呢?通过计算分组内所有调用方 QPS 的方式来算出单个分组内所需的机器数,因为会有不确定性因素的存在,所以在分配数量时,通常都会在现有数量的基础上加一个百分比,比如10%~30%左右,确保分组集群具备一定的抗压能力。
-
如何动态分组?
在应对大的突发流量时,因为机器成本的原因,我们给每个分组预留的机器数量都不会太多,所以当突发流量超过预留机器的能力的时候,就会让这个分组的集群处于危险的状态。这个时候就可以采用动态分组,但通过
修改分组进行重启应用的方式,不仅操作过程慢,事后还得恢复,显然不太合理, 那有没更好的方案?可以通过修改注册中心的数据来解决这个问题。
> 我们只要把注册中心里面的部分实例的别名改成期望的别名,然后通过服务发现功能去调用不同服务提供方的实例集合。
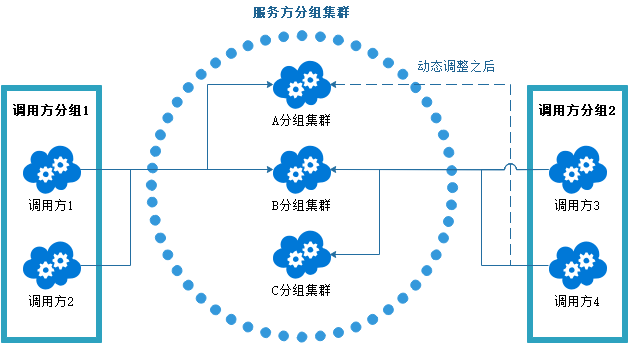
如上图所示,调用方分组1分配了A、B两个服务方分组集群, 调用方分组2分配了B、C两个服务方分组集群;如果调用方分组2突发面临峰值请求,B、C两个分组集群负载过高, 但是调用方分组1请求较少, 服务方A分组集群较为空闲,这个时候可以通过直接修改注册中心数据,动态调整,让调用方分组2可以调用A分组集群,这样, 我们就可以让任何一个分组瞬间拥有不同规模的集群能力。不仅可以实现把某个实例的分组名改成另外一个分组名,还可以让某个实例分组做组合调整,提升集群吞吐能力,这就是我们在动态分组里面最常见的两种动作——追加与替换。

3. 保障调用安全
-
为什么需要保障安全?
网络应用服务经常会受到SQL 注入、XSS 攻击等恶意攻击行为,那在 RPC 里面会出现怎样的安全问题呢?
RPC 是解决应用间互相通信的框架,应用之间的远程调用一般不会暴露在公网,RPC 一般采用内部方式进行通信,而这个“内部”是指部署在同一个局域网内。相对于公网环境,局域网的隔离性更好,也就相对更安全,所以在 RPC 里面我们很少考虑像数据包篡改、请求伪造等恶意行为, 如果增加处理, 会牺牲一些效率。
RPC的调用会先由服务提供方定义好一个接口,并把这个接口的 Jar 包发布到私服上去,然后在项目中去实现这个接口,最后通过 RPC 提供的 API 进行调用,这里面其实存在一个安全隐患问题,因为私服上所有的 Jar 包所有人都可以下载查阅,只要拿到了 Jar 包,就可以通过私服的 Jar 引入到项目中完成 RPC的 调用,这种行为对于服务提供方来说就比较危险,因为接入了新的调用方就意味着承担的调用量会变大,有时候很有可能新增加的调用量会成为压倒服务提供方的“最后一根稻草”,从而导致服务提供方负载过高而无法正常提供服务,所以需要有一个安全机制, 能够确保调用方的合法身份。
-
如何解决调用安全问题?
出现以上问题主要原因是不知道这次请求是哪个调用方所发起的,无法判定合法性,所以也就没法选择拒绝还是继续执行请求。解决办法只需要给每个调用方设定一个唯一的身份,每个调用方在调用之前都先做好登记,服务提供方根据登记信息做判断, 只有登记过的调用方才能继续放行,没有登记过的调用方一律拒绝。
-
实现方案
我们可以采用第三方授权平台去完成调用方身份的验证, 但这样要对每次请求通过第三方授权平台做验证会影响通讯效率,那么有没有更好的方案?可以采用类似JWT的签名方案或者采用加密算法约定私钥,对请求数据进行加密处理,这样可以不用完全依赖于第三方授权平台,即便第三方授权平台出现故障, 也不会影响RPC的正常通信, 由调用双方自身负责完成鉴权处理,由于涉及到加密与解密处理, 会稍微耗费一些CPU开销。
-
解决伪造服务方问题
如果他人拿到了私服的调用JAR包,可以根据接口信息发布一个新的服务提供者,这样的后果就是导致调用方通过服务发现拿到的服务IP 地址集合里会存在伪造的提供方信息。
为了避免出现这个问题, 我们可以建立一个白名单机制,将开放合法的服务方IP和端口纳入白名单中,有两种处理方案:
> 1. 白名单可以存放在注册中心中, 由调用方拉取并做校验,但这样需要在调用方增加判断逻辑。
> 2. 由服务端来检测处理,开辟一个白名单专用检测线程, 从注册中心拉取服务节点信息做判断比对,如果有不合法的节点,发出预警并调用注册中心的接口将其剔除。





