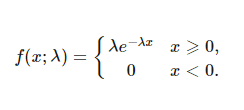在某些分布假设下,某些机器学习模型被设计为最佳工作。因此,了解我们正在使用哪个发行版可以帮助我们确定最适合使用哪些模型。
介绍
拥有良好的统计背景可能对数据科学家的日常生活大有裨益。每次我们开始探索新的数据集时,我们首先需要进行 探索性数据分析(EDA),以了解某些功能的主要特征是什么。如果我们能够了解数据分布中是否存在任何模式,则可以量身定制最适合我们的案例研究的机器学习模型。这样,我们将能够在更短的时间内获得更好的结果(减少优化步骤)。实际上,某些机器学习模型被设计为在某些分布假设下效果最佳。因此,了解我们正在使用哪些发行版可以帮助我们确定最适合使用哪些模型。
同类型的数据
我们正在与一个数据集工作,每次,我们的数据代表一个 样本 从 人口。然后,使用此样本,我们可以尝试了解其主要模式,以便我们可以使用它对整个人口进行预测(即使我们从未有机会检查整个人口)。
假设我们要根据一组特定功能来预测房屋的价格。我们也许可以在线找到一个包含旧金山所有房价的数据集(我们的样本),并且进行一些统计分析之后,我们也许可以对美国任何其他城市的房价做出相当准确的预测(我们的人口)。
数据集由两种主要类型的数据组成: 数字 (例如整数,浮点数)和 分类 (例如名称,笔记本电脑品牌)。
数值数据还可以分为其他两类: 离散 和 继续。离散数据只能采用某些值(例如学校中的学生人数),而连续数据可以采用任何实数或分数值(例如身高和体重的概念)。
从离散随机变量中,可以计算出 概率质量函数,而从连续随机变量中,可以得出 概率密度函数。
概率质量函数给出了一个变量可以等于某个值的概率,相反,概率密度函数的值本身并不是概率,因为它们首先需要在给定范围内进行积分。
自然界中存在许多不同的概率分布(概率分布流程图),在本文中,我将向您介绍数据科学中最常用的概率分布。
首先,让我们导入所有必需的库:

伯努利分布
伯努利分布是最容易理解的分布之一,可用作导出更复杂分布的起点。
这种分布只有两个可能的结果和一个试验。
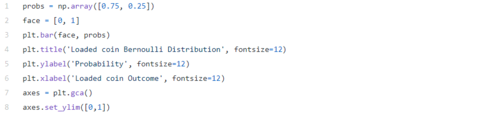
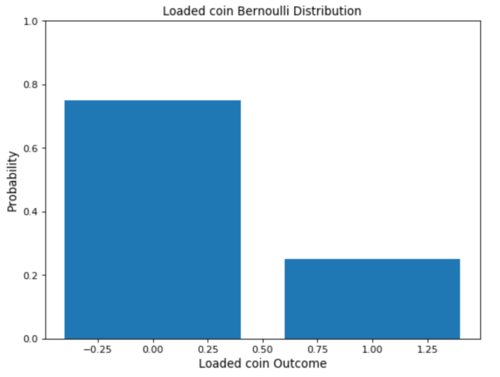
一个简单的例子可以是抛掷偏斜/无偏硬币。在此示例中,可以认为结果可能是正面的概率等于p, 而 对于反面则是 (1-p)(包含所有可能结果的互斥事件的概率总和为1)。
在下图中,我提供了一个偏向硬币情况下伯努利分布的例子。
均匀分布
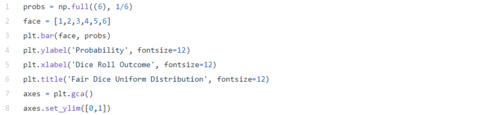
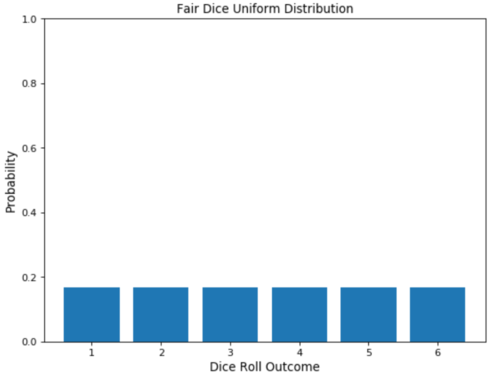
均匀分布可以很容易地从伯努利分布中得出。在这种情况下,结果的数量可能不受限制,并且所有事件的发生概率均相同。
例如,想象一下一个骰子的掷骰。在这种情况下,存在多个可能的事件,每个事件都有相同的发生概率。
二项分布
二项分布可以被认为是遵循伯努利分布的事件结果的总和。因此,二项分布用于二元结果事件,成功和失败的可能性在所有后续试验中均相同。此分布采用两个参数作为输入:事件发生的次数和分配给两个类别之一的概率。
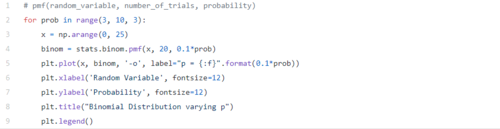
一个实际的二项式分布的简单示例可以是重复一定次数的有偏/无偏硬币的抛掷。
改变偏差量将改变分布的外观(如下图所示)。
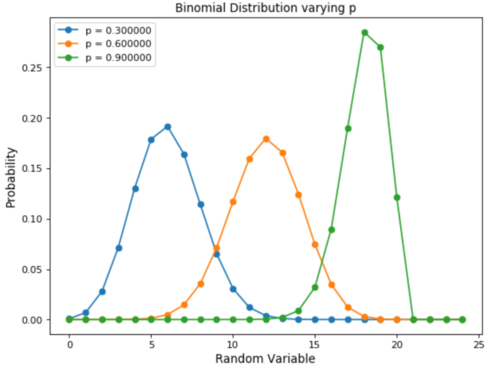
二项分布的主要特征是:
给定多个试验,每个试验彼此独立(一项试验的结果不会影响另一项试验)。
每个试验只能导致两个可能的结果(例如,获胜或失败),其概率分别为 p 和 (1- p)。
如果给出成功的概率(p)和试验次数(n),则可以使用以下公式计算这n次试验中的成功概率(x)(下图)。
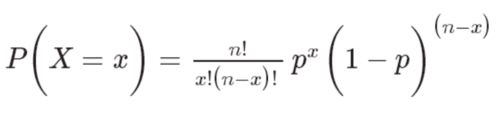
正态(高斯)分布
正态分布是数据科学中最常用的分布之一。我们日常生活中发生的许多常见现象都遵循正态分布,例如:经济中的收入分布,学生的平均报告,人口的平均身高等。此外,小的随机变量的总和还导致:通常遵循正态分布(中心极限定理)。
“在概率论中, 中心极限定理 (CLT)确定,在某些情况下,当添加独立随机变量时,即使原始变量本身未呈正态分布,其适当归一化的和也趋于正态分布。”

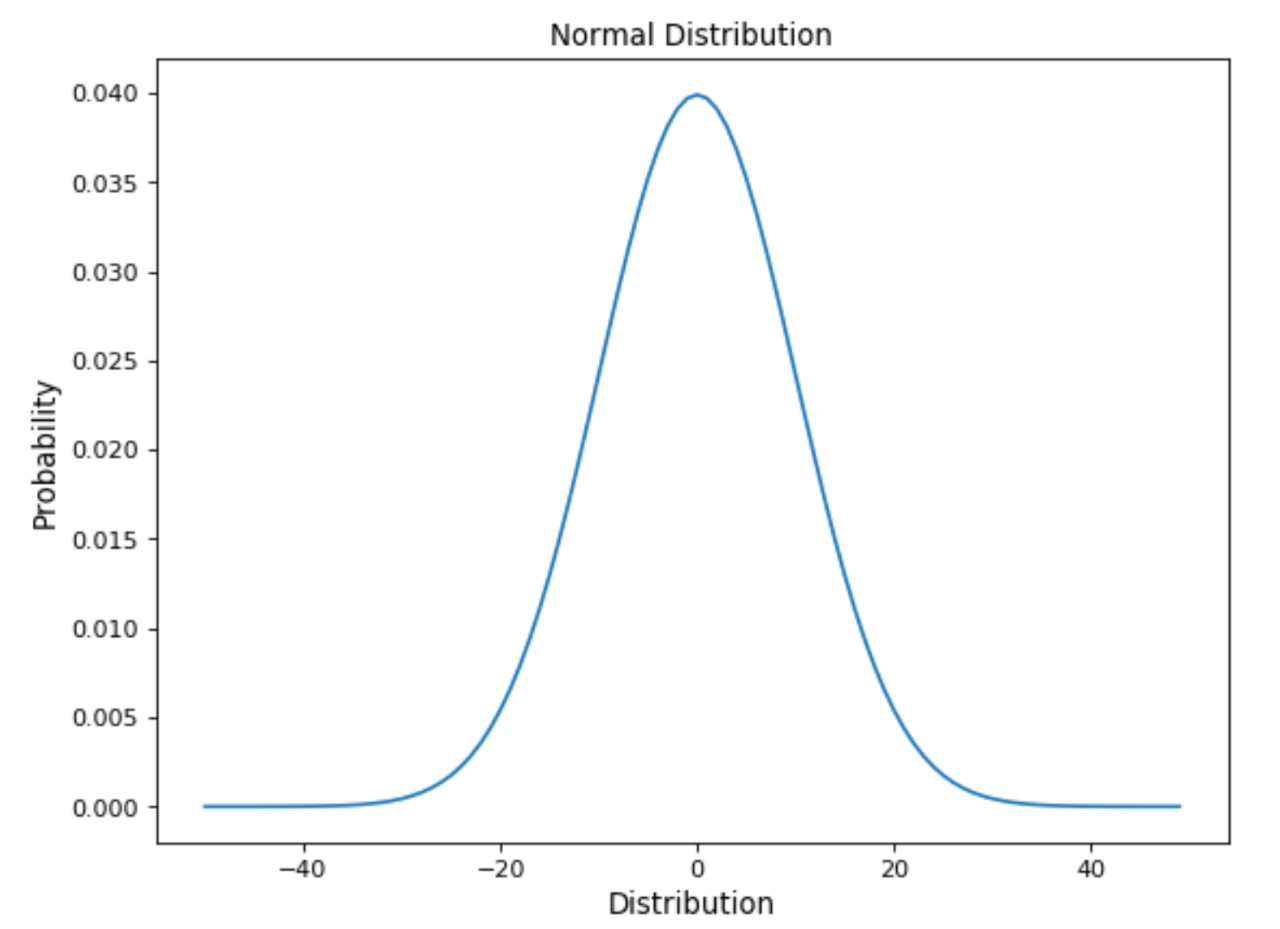
可以帮助我们识别正态分布的一些特征是:
曲线在中心对称。因此,均值,众数和中位数都等于相同的值,从而使所有值围绕均值对称分布。
分布曲线下的面积等于1(所有概率之和必须等于1)。
可以使用以下公式得出正态分布(下图)。
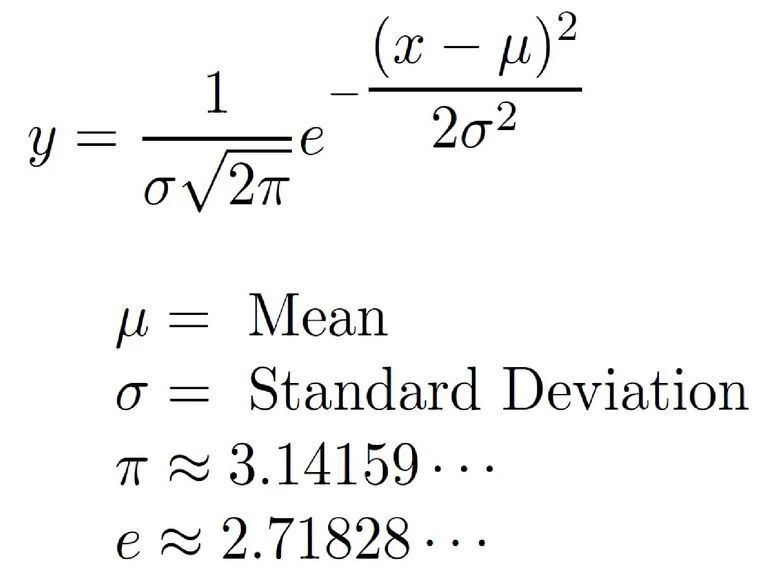
使用正态分布时,分布平均值和标准偏差起着非常重要的作用。如果我们知道它们的值,则只需检查概率分布即可轻松找出预测精确值的概率(下图)。实际上,由于分布特性,68%的数据位于平均值的一个标准偏差范围内,95%的数据位于平均值的两个标准偏差范围内,99.7%的数据位于平均值的三个标准偏差范围内。
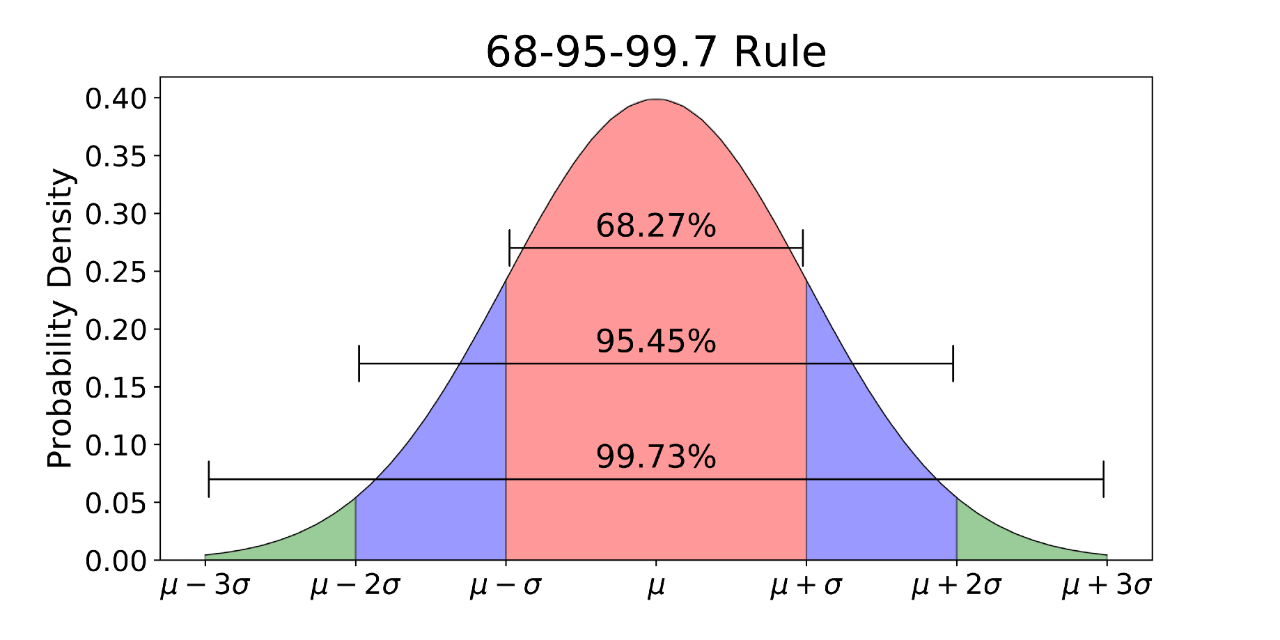
许多机器学习模型被设计为遵循正态分布的最佳使用数据。一些例子是:
高斯朴素贝叶斯分类器
线性判别分析
二次判别分析
基于最小二乘的回归模型
此外,在某些情况下,还可以通过应用对数和平方根之类的转换将非正常数据转换为正常形式。
泊松分布
泊松分布通常用于查找事件可能发生或不知道事件通常发生的频率。此外,泊松分布还可用于预测事件在给定时间段内可能发生多少次。
例如,保险公司经常使用泊松分布来进行风险分析(例如,在预定时间范围内预测车祸事故的数量),以决定汽车保险的价格。
当使用Poisson Distributions时,我们可以确信发生不同事件之间的平均时间,但是事件发生的确切时刻在时间上是随机间隔的。
泊松分布可以使用以下公式建模(下图),其中 λ 表示一个时期内可能发生的预期事件数。
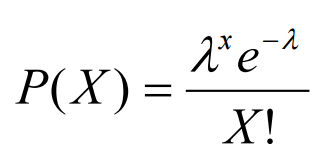
描述泊松过程的主要特征是:
事件彼此独立(如果事件发生,则不会改变另一个事件发生的可能性)。
一个事件可以发生任何次数(在定义的时间段内)。
两个事件不能同时发生。
事件发生之间的平均速率是恒定的。
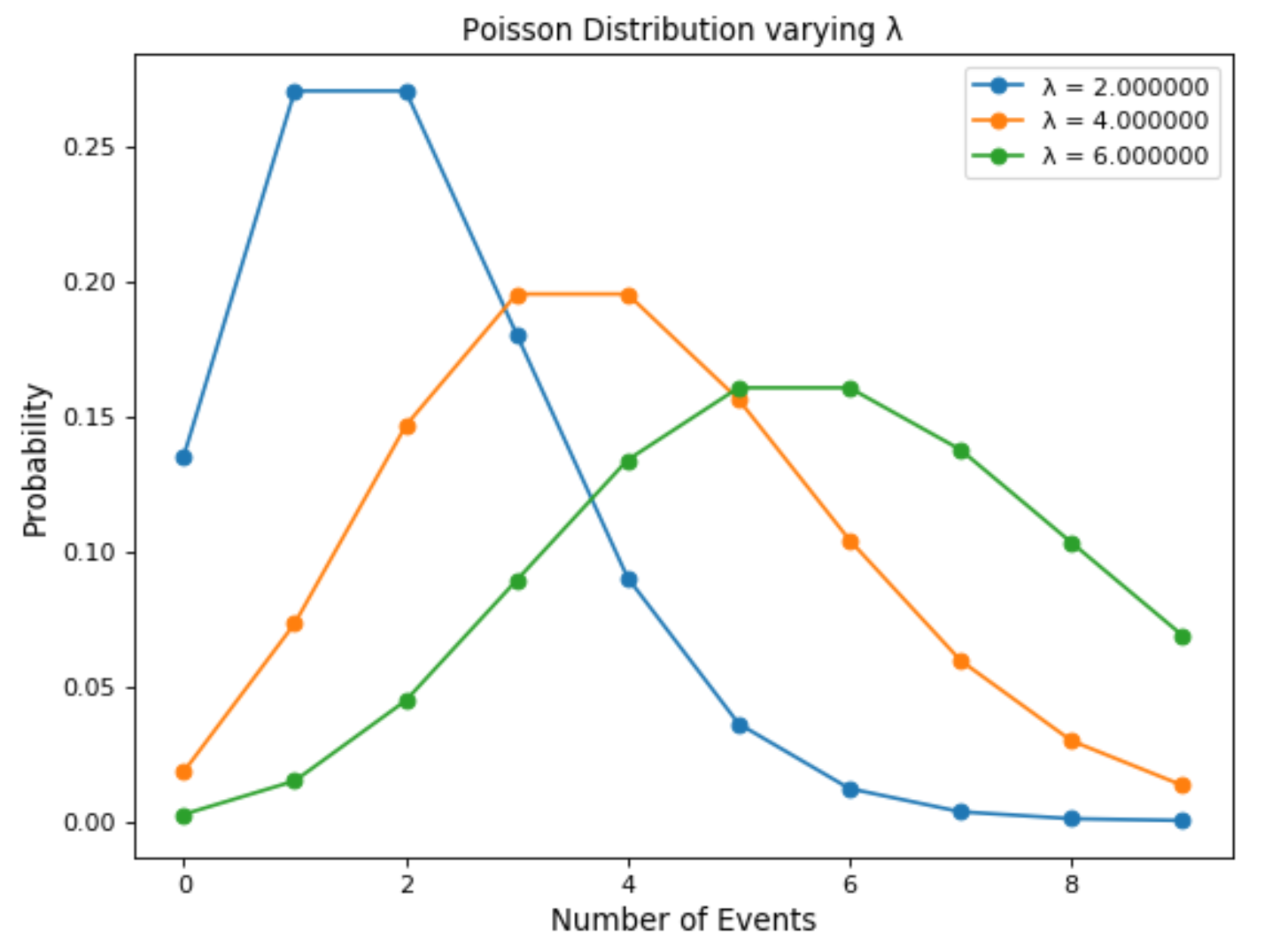
在下图中,显示了改变周期(λ)中可能发生的事件的预期数目如何改变泊松分布。

指数分布
最后,指数分布用于对不同事件发生之间的时间进行建模。
举例来说,假设我们在一家餐厅工作,并且希望预测到到不同顾客进入餐厅之间的时间间隔。针对此类问题使用指数分布,可能是一个理想的起点。
指数分布的另一个常见应用是生存分析(例如,设备/机器的预期寿命)。
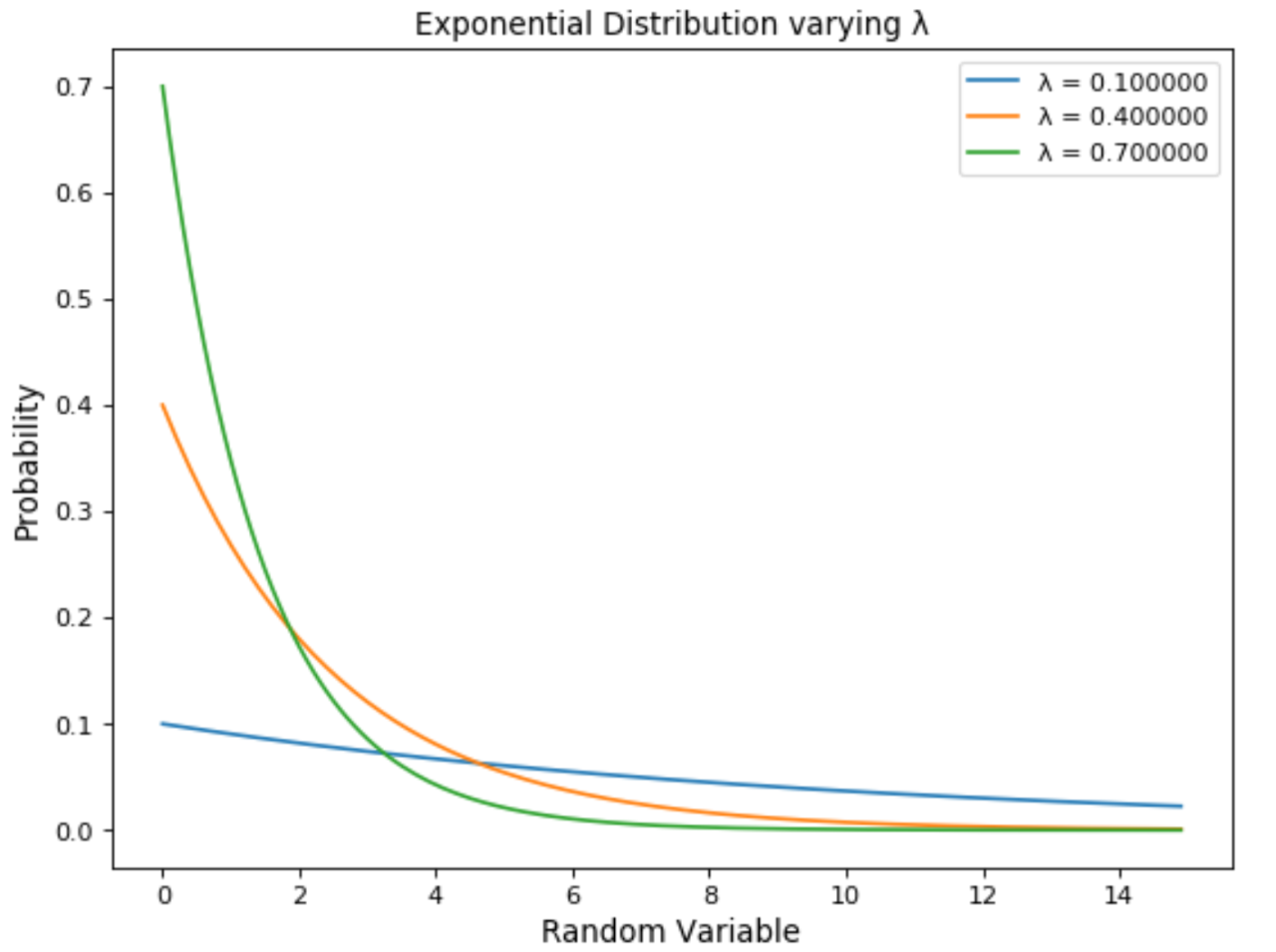
指数分布由参数λ调节。λ值越大,指数曲线到十年的速度就越快(下图)。

指数分布使用以下公式建模(下图)。