
1 前言
欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章!
Spring Cloud Data Flow是什么,虽然已经出现一段时间了,但想必很多人不知道,因为在项目中很少有人用。不仅找不到很多中文资料,英文资料也一样少的可怜。这让探索的路更加艰辛,也更加有趣吧。
Spring Cloud Data Flow是基于微服务的,专门用于流式和批式数据处理的框架。
2 基本概念
2.1 数据处理模式
数据处理有两种模式,分别是Streaming流式处理和Batch批次处理。Streaming是长时间一直存在的,你数据来了我就处理,没来我就等着,基于消息驱动。Batch是处理时间较短的,启动一次处理一次,处理完就退出任务,需要去触发任务。
一般地,我们会基于Spring Cloud Stream框架来开发Streaming应用,而基于Spring Cloud Task或Spring Batch框架来开发Batch应用。完成开发后,可以打包成两种形式:
- (1)
Springboot式的jar包,可以放在maven仓库、文件目录或HTTP服务上; - (2)
Docker镜像。
对于Stream,有三个概念是需要理解的:
- (1)
Source:消息生产者,负责把消息发送到某个目标; - (2)
Sink:消息消费者,负责从某个目标读取消息; - (3)
Processor:联合Source和Sink,它从某个目标消费消息,然后发送到另一个目标。
2.2 特性
Spring Cloud Data Flow有许多好的特性值得我们学去使用它:
-
基于云的架构,可部署在
Cloud Foundry、Kubernetes或OpenShift等。 -
有许多可选择的开箱即用的流处理和批处理应用组件。
-
可自定义应用组件,且是基于
Springboot风格的编程模型。 -
有简单灵活的
DSL(Domain Specific Language)去定义任务处理逻辑。 -
有美观的
Dashboard能可视化地定义处理逻辑、管理应用、管理任务等。 -
提供了
REST API,可以在shell命令行模式下进行交互。
2.3 服务端组件
服务端有两个重要的组件:Data Flow Server和Skipper Server。两者作用不同,互相协作。
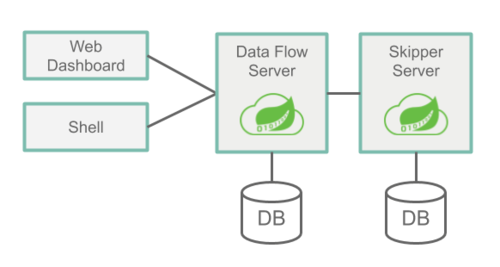
Data Flow Server的主要作用有:
- 解析
DSL; - 校验和持久化
Stream、Task和Batch的定义; - 注册应用如
jar包应用和docker应用; - 部署
Batch到一个或多个平台; - 查询
Job和Batch的历史执行记录; Stream的配置管理;- 分发
Stream部署到Skipper。
Skipper Server主要作用有:
- 部署
Stream到一个或多个平台; - 基于有灰度/绿色更新策略地更新或回滚
Stream; - 保存每一个
Stream的描述信息。
可以看出,如果不需要使用Stream,可以不用部署Skipper。两者都需要依赖关系型数据库(RDBMS),默认会使用内置的H2,支持的数据库有H2、HSQLDB、MYSQL、Oracle、PostgreSql、DB2和SqlServer。
2.4 运行环境
优秀的Spring的解耦能力总是特别强,Server和应用可以运行在不同的平台。我们可以把Data Flow Server和Skipper Server部署在Local、Cloud Foundry和Kuernetes,而Server又可以把应用部署在不同的平台。
- 服务端Local:应用Local/Cloud Foundry/Kuernetes;
- 服务端Cloud Foundry:应用Cloud Foundry/Kuernetes;
- 服务端Kuernetes:应用Cloud Foundry/Kuernetes。
一般情况下,我们会把Server和应用部署在同一平台上。对于生产环境,建议还是在Kuernetes上比较合适。
3 本地模式安装使用
为了快速体验,我们使用最简单的本地运行环境。
3.1 下载Jar包
下载以下三个jar包:
wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server/2.5.3.RELEASE/spring-cloud-dataflow-server-2.5.3.RELEASE.jar
wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-shell/2.5.3.RELEASE/spring-cloud-dataflow-shell-2.5.3.RELEASE.jar
wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-skipper-server/2.4.3.RELEASE/spring-cloud-skipper-server-2.4.3.RELEASE.jar
如果是简单的Batch应用,可以只下载spring-cloud-dataflow-server-2.5.3.RELEASE.jar。
3.2 启动应用
# 启动Skipper,默认端口为7577
java -jar spring-cloud-skipper-server-2.4.3.RELEASE.jar
# 启动Data Flow Server,默认端口为9393
java -jar spring-cloud-dataflow-server-2.5.3.RELEASE.jar
启动完成后,访问UI:http://localhost:9393/dashboard

3.3 部署应用
3.3.1 添加应用Applications
只有添加了应用,才能部署Batch和Stream。官方提供了示例Applications,我们直接使用就可以了:
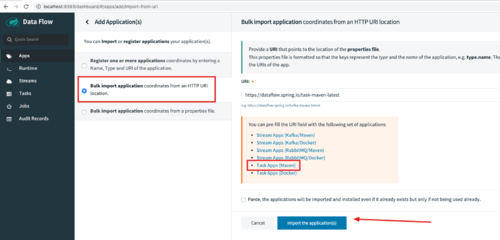
添加成功后,在应用列表可以查看:

3.3.2 创建Task
创建Task可以图形化创建,也可以通过DSL来创建,非常方便:

定义好Task后,输入名字创建:

3.3.3 运行Task
直接点击运行:

可以传入参数:

3.3.4 查看Task运行情况


可以查看运行日志:

3.4 Data Flow Shell命令行
除了在网页上,还可以通过命令行模式来与Server进行交互。
启动应用:
$ java -jar spring-cloud-dataflow-shell-2.5.3.RELEASE.jar
____ ____ _ __
/ ___| _ __ _ __(_)_ __ __ _ / ___| | ___ _ _ __| |
\___ \| '_ \| '__| | '_ \ / _` | | | | |/ _ \| | | |/ _` |
___) | |_) | | | | | | | (_| | | |___| | (_) | |_| | (_| |
|____/| .__/|_| |_|_| |_|\__, | \____|_|\___/ \__,_|\__,_|
____ |_| _ __|___/ __________
| _ \ __ _| |_ __ _ | ___| | _____ __ \ \ \ \ \ \
| | | |/ _` | __/ _` | | |_ | |/ _ \ \ /\ / / \ \ \ \ \ \
| |_| | (_| | || (_| | | _| | | (_) \ V V / / / / / / /
|____/ \__,_|\__\__,_| |_| |_|\___/ \_/\_/ /_/_/_/_/_/
2.5.3.RELEASE
Welcome to the Spring Cloud Data Flow shell. For assistance hit TAB or type "help".
Successfully targeted http://localhost:9393/
dataflow:>app list
╔═══╤══════╤═════════╤════╤════════════════════╗
║app│source│processor│sink│ task ║
╠═══╪══════╪═════════╪════╪════════════════════╣
║ │ │ │ │composed-task-runner║
║ │ │ │ │timestamp-batch ║
║ │ │ │ │timestamp ║
╚═══╧══════╧═════════╧════╧════════════════════╝
dataflow:>
4 总结
本文使用的是官方提供的应用,我们可以自己开发应用并注册到Server上。Local模式适合开发环境适合,生产环境还是部署在Kubernetes比较靠谱。后面我们再来探索吧。
多读书,多分享;多写作,多整理。





