
数据处理贯穿整个应用的前后端,其中集合数据处理在大前端体系中主要集中应用于从数据库到业务逻辑,和前端呈现部分,是处理后端业务和前端呈现必需要掌握的技能,是大前端体系中非常微小,同时也非常常用的技能之一。
大前端体系课程涵盖了项目全周期、全流程的知识,Brian 老师会用实际案例,结合理论知识和方法、技巧,领略一个项目从无到有,从生产到实施的全部过程。内容详实,闭环打造大前端能力!
大前端体系课程地址:https://t.cn/AisA8hpi, 优惠码 NXXTP5XP。学习完后还有优惠哦!
产生数组
Array(...) 产生数组
看看下面两段代码,分别能输入多少个 hello?
for (let i in Array(10)) {
console.log("hello", i);
}
Array(10).forEach(v => console.log("hello again"));
**一个也没有!**因为 JS 的数组元素可以是空位,而不是 undefined。空位在遍历时会直接跳过。
那要怎么样才能有?好几种办法生产
// 使用 Array.form()
Array.from(Array(10))
// Array.from() 可以接收一个 Array Like 对象(像是数组的对象)
Array.from({ length: 10 })
// 直接使用展开运算符
[...Array(10)]
// 注意 [...{ length: 10}] 是不对的
// 使用 fill,
Array(10).fill("some value")
// 不带参数的 fill 会把所有元素初始化为 undefined
Array(10).fill()
扩展 range 函数生成数组
Array.range = function (length, min = 0, step = 1) {
if (step === 1) {
return Array.from(Array(length), (_, i) => min + i);
}
if (step === 0) {
return Array(length).fill(min);
}
return Array.from(Array(length), (_, i) => min + i * step);
}
产生一个偶数数组
// Array.from() 带第 2 个参数相当于做一次 map
const evenNums = Array.from({ length: 10 }, (_, i) => i + i);
// 相当于
const evneNums = [...Array(10)].map((_, i) => i + i);
// 或者用刚才扩展的 range
const evenNums = Array.range(10, 0, 2);
Array.range(10, )
遍历数组
// 传统的 for 遍历
for (let i = 0; i < data.length; i++) { }
// for ... in,遍历索引
for (const i in data) { } // [0, 1, 2]
// for ... of,遍历元素
for (const el of data) { } // [ 2, 3, 4]
// 函数式遍历
data.forEach(el => { ... }) // [2, 3, 4]
// 也可以带索引
data.forEach((el, index) => { ... })
遍历对象
const data = { a: 1, b: 2, c: 3 };
// for ... in 遍历 key
for (const key in data) { }
// for ... of 遍历值
for (const value of data) { }
// Object.keys() 获取所有 key
Object.keys(data).forEach();
// Object.values() 获取所有值
Object.values(data).forEach();
// Object.entries() 获取所有键值对,以数组 [key, value] 的形式
Object.entries(data).forEach(
([key, value]) => console.log(`${key} = ${value}`));
// 注意:上面的箭头函数使用了解构语法
补充:解构数组参数
function([a, b]) { ... }
// 相当于
function(arr) {
let [a, b] = arr;
}
// 相当于
function(arr) {
let a = arr[0];
let b = arr[1];
}
判断和查找
includes()和indexOf是用元素对参数精确匹配===进行查找find()和findIndex()是传入比较行为(函数),按指定方式查找
console.log([1, 2, 3, 4, 5].includes(3));
const a = { v: 3 };
const array = [
{ v: 1 },
{ v: 2 },
{ v: 3 },
{ v: 4 },
];
console.log(array.includes(a));
const arr = [
{ v: 1}
{ v: 2}
];
const a = { v: 2 }
// console.log(!!);
count f = array.find(it => it.v === a.v)
// 此时 f !== a
console.log(array.find(it => it.v === a.v));
console.log(array.findIndex(it => it.v === a.v) >= 0);
console.log(!![0, 1, 2, 3].find(it => it === 0));
过滤
const nums = Array.range(20);
// filter 的参数指定判断行为
const nums3 = nums.filter(n => n % 3 === 0);
变换
const times = Array.from(Array(10), (_, i) => i + 1);
const numsBase2 = times.map(t => 2 << (t - 1));
为什么计算 times 的时候要 i + 1,但在使用的时候又要 t - 1?
直接不增不减不是正好吗?
从效率来说,确实可以不增不减。但从语义来说,times 是个次方列表,我们预期的次方是从 1 到 10。而 2 的 1 次方,确实是左位移 0 位。代码是写给人看的,所以语义很重要!
九九乘法表
const digits = Array.range(9, 1);
const result = digits.map(n => Array.range(n, 1).map(m => `${m} × ${n} = ${m * n}`))
要合并成一个数组怎么办?用 flat() 和 flatMap()
const flatReult = result.flat();
const flatResult = digits
.flatMap(n => Array.range(n, 1).map(m => `${m} × ${n} = ${m * n}`))
// ^^^^^^^
按条件删除元素
const data = Array.range(20); // 0 ~ 19
for (let i = 0; i < data.length; i++) {
if (data[i] % 3 === 0 || data[i] % 4 === 0) {
data.splice(i, 1);
}
}
// [
// 1, 2, 4,
// 5, 7, 9,
// 10, 11, 13, 14, 16,
// 17, 19
// ]
为什么还留下了 4、9、16 等符合去除条件的元素?
- 遍历过程中不要增/减元素,因为会造成索引变化
- 使用
filter过滤掉不需要的元素 - 删除从大索引往小逐一处理
- 插入从小索引往大逐一处理
展开多层数组
使用递归
递归是使用的数据归纳法的思想:
在数论中,数学归纳法是以一种不同的方式来证明任意一个给定的情形都是正确的(第一个,第二个,第三个,一直下去概不例外)的数学定理。
递归处理的两个关键点:
- 调用点,即在函数体内部找到调用自身进行处理点。更准确的说,每次调用是相同数据结构的参数
- 结束点,没有结束点递归就会一直进行下去,直到资源耗尽。也就是说,递归函数体中一定存在一个执行分支,不会调用自身。
const data = [1, 2, [3, 4, [5, 6]]];
const result = [];
addFrom(data);
function addFrom(arr) {
arr.forEach(el => {
if (Array.isArray(el)) {
addFrom(el);
} else {
result.push(el);
}
})
}
console.log(result);
result 可能会造成全局染污(它只在这里有用,但在整个函数范围内可访问),改用闭包
console.log((() => {
const result = [];
...
return result;
})());
或者直接用 generator 函数一次性解决:
function* flat(arr) {
for (el of arr) {
if (Array.isArray(el)) {
yield* flat(el);
} else {
yield el;
}
}
}
const result = [...flat(data)];
generator 写法更容易用于函数式代码。
分组代码示例
分组是一个聚合(reduce)处理过程
// keySelector: (model) => string;
Array.prototype.groupBy = function (keySelector) {
return this.reduce(
(groups, it) => { // <-- 这里的 group 从 (1)/(2) 传入
const key = keySelector(it);
const list = groups[key] || (groups[key] = []);
list.push(it);
return groups; // <-- (2) 会作为下一次迭代的 group 参数
},
{} // <-- (1),初始的 result,会作为第一次迭代的 group 参数
);
}
分组结果是一个键值对,键是一个字符串,由 keySelector 决定,值是分组好的数据列表([])
使用 Lodash
Lodash 已经定义好了多数对集合和对象数据进行处理所需要的方法。上面的分组处理可以用 Lodash 的 _.groupBy 来处理:
npm 安装或直接引入页面(下载或 CDN)
npm init -y
npm install lodash
import lodash from "lodash";
// 为了演示,简化数组元素结构
const simple = data.map(({ category, title }) => ({ category, title }));
// console.log(simple.groupBy(it => it.category));
// 对应的 lodash 方法
console.log(lodash.groupBy(simple, it => it.category));
上面两步可以使用延迟处理方式
console.log(
lodash(data) // 延迟处理需要对数据进行封装
// 下面的 map 和 groupBy 只是在配置处理链条
.map(({ category, title }) => ({ category, title }))
.groupBy(it => it.category)
.value() // 延迟处理需要最终调用处理过程
);
// const groupList = Object.entries(groups);
// console.log(groupList);
延迟处理相当于把需要循环 n 次干的事情,在一次循环里依次进行处理。减少循环,提高效率。
大前端课程
看完介绍有福利哦!看完介绍有福利哦!看完介绍有福利哦!
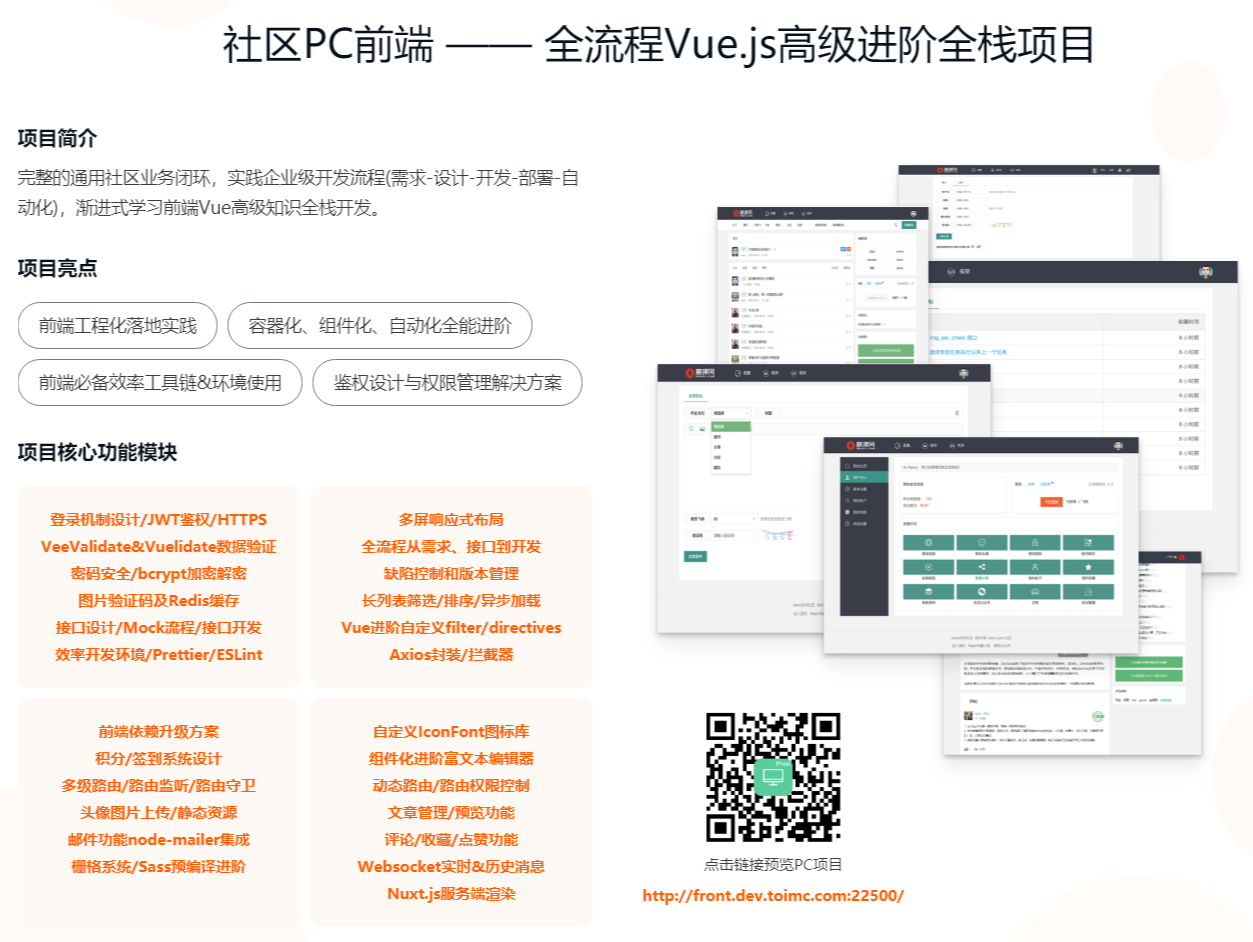
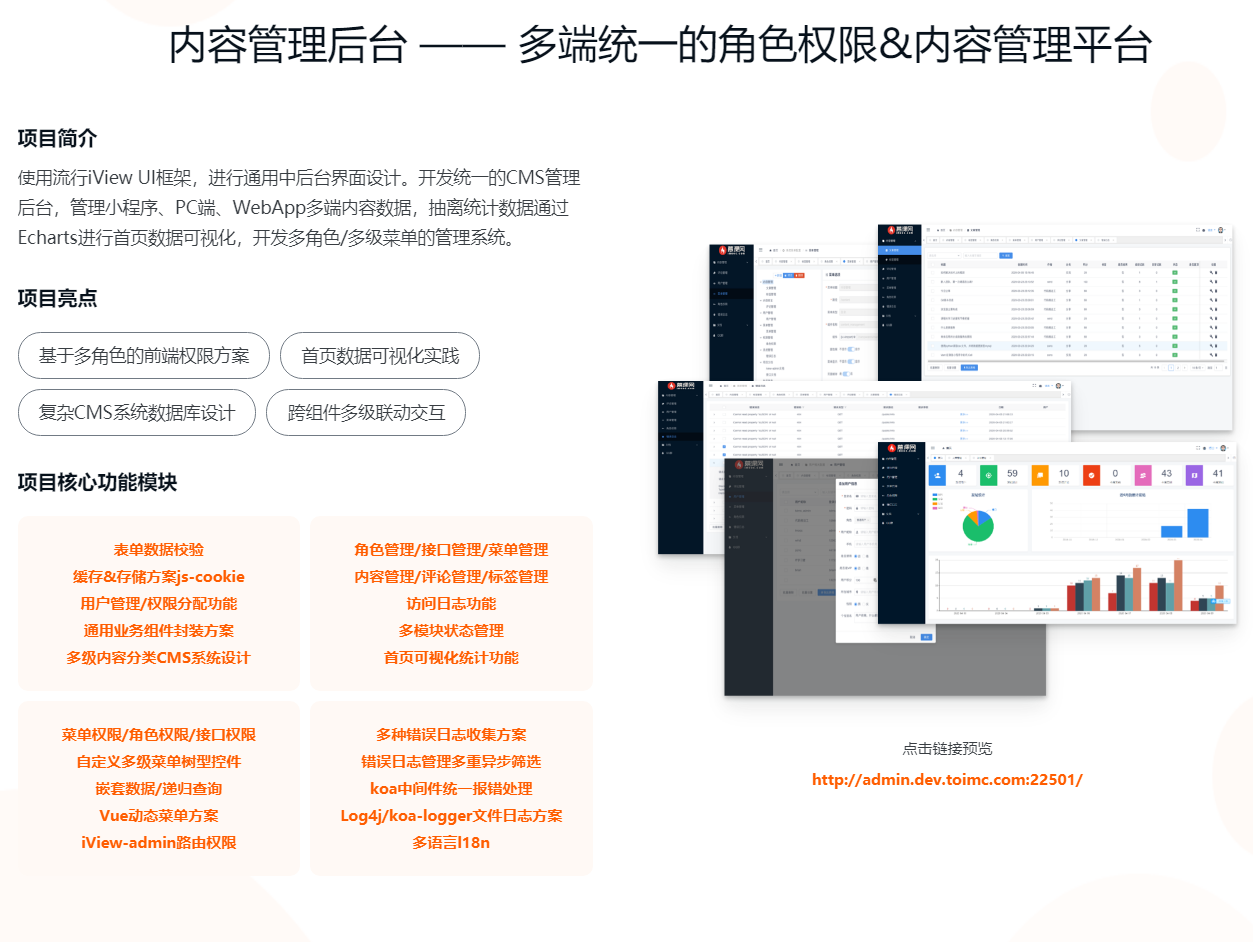
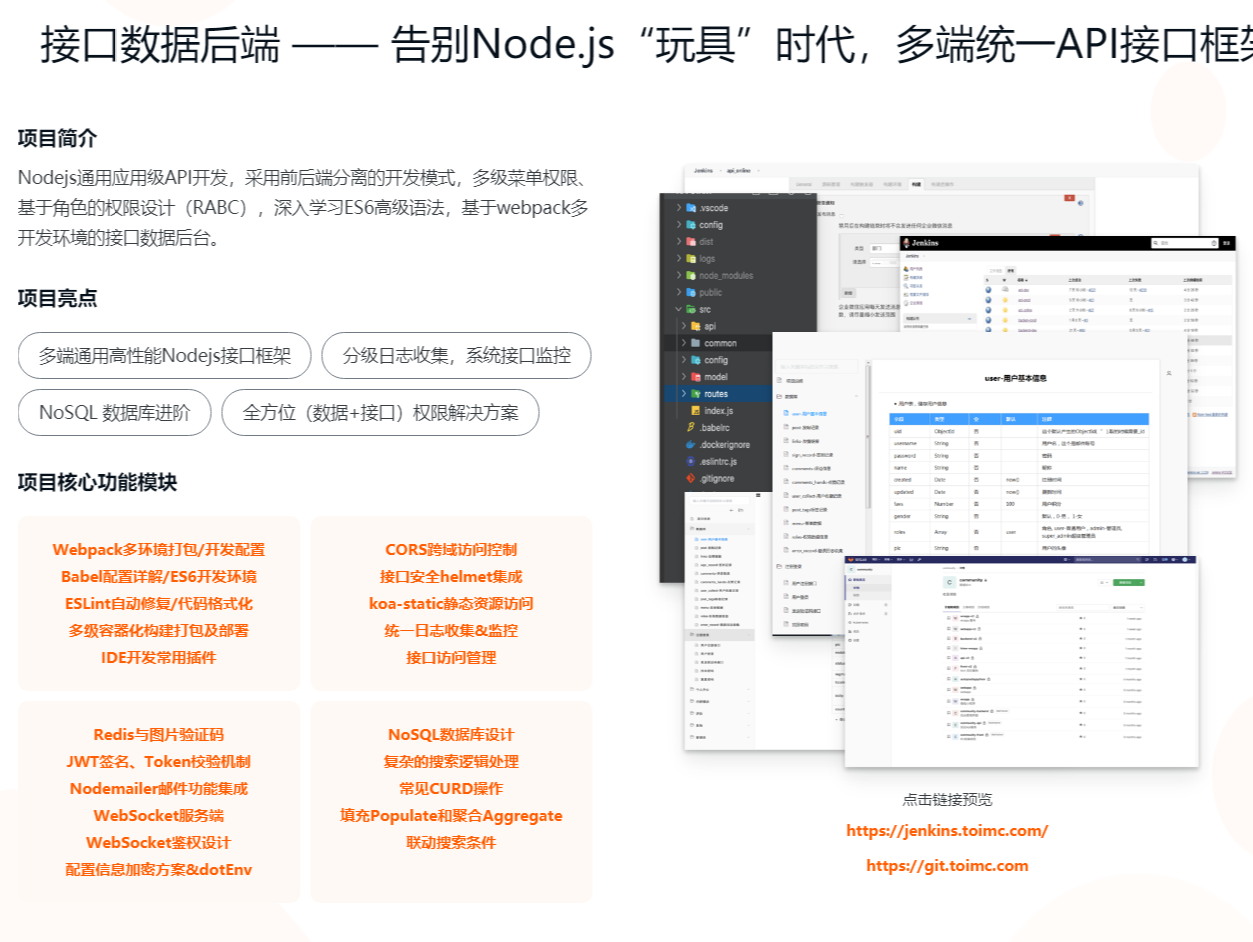
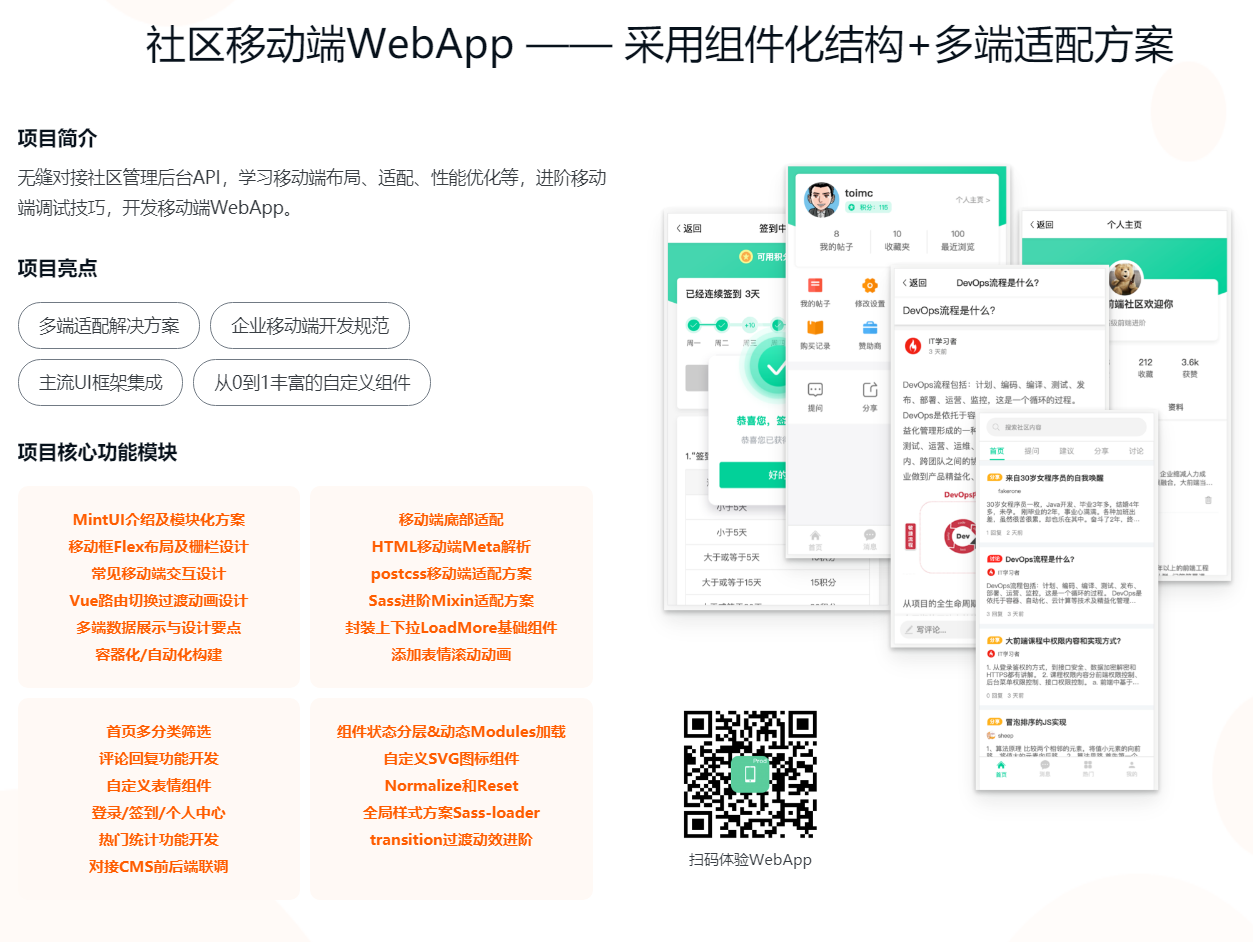
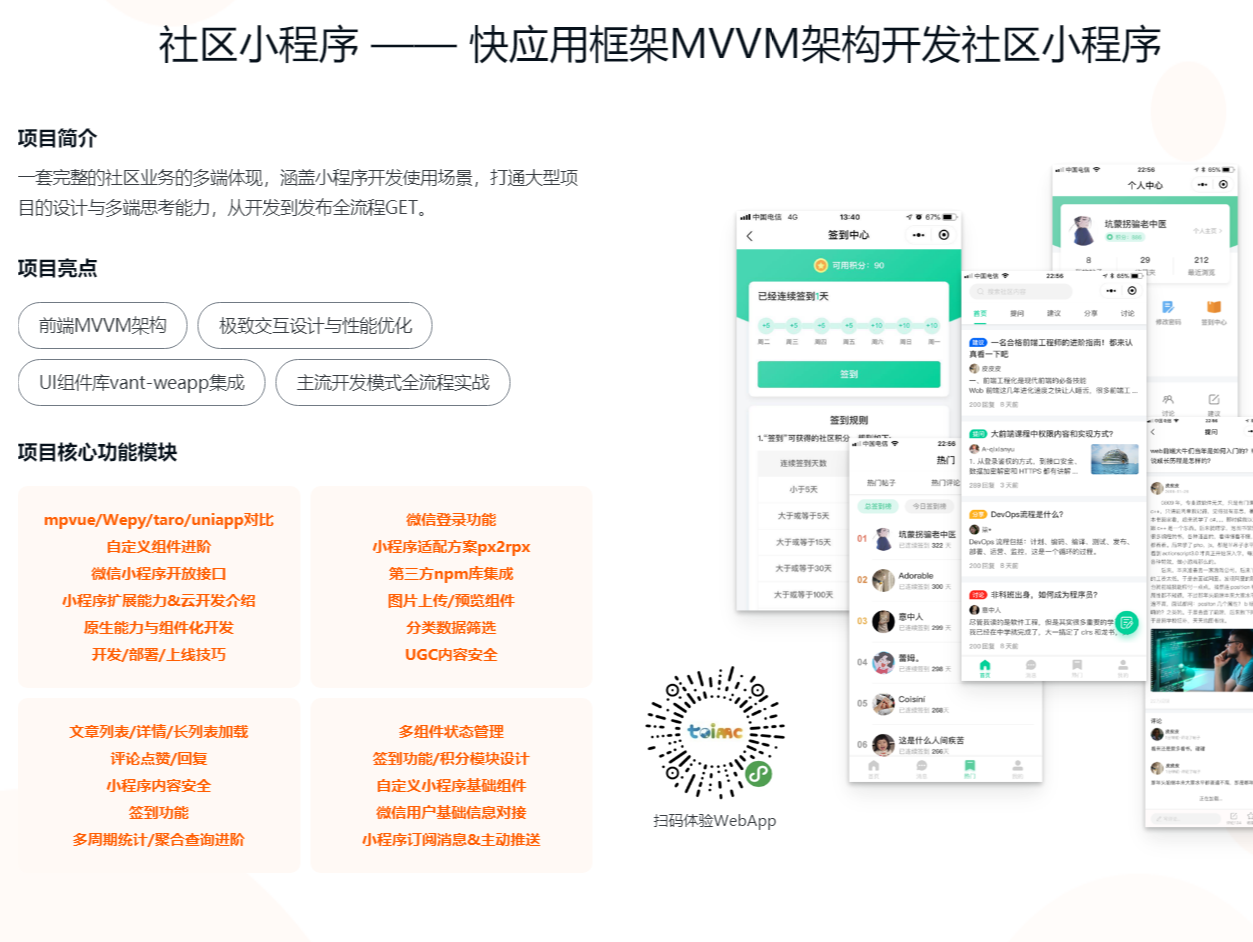
这是直播课程的知识整理,学习有礼:给大家的福利!
(礼物多多,要仔细看哦~)
福利1:
官网原价立减 400 元超大额优惠码,到手 2280 元!
优惠码:NXXTP5XP
大前端体系课地址:https://t.cn/AisA8hpi
福利2:
今天报名的所有小伙伴,都可任选慕课专栏一个!
福利3:
参加直播的同学均可获得:《用技术打造小程序简历》一分钱领取!
福利4:
今晚报名及之前报名大前端课程的小伙伴,均可进入【福利群】抽取慕课三件套、专栏等奖品!









