
在上一篇文章中,我们学习了如何安装配置OpenCV和Python,然后写了些代码玩玩人脸检测。现在我们要进行下一步了,即搞一个人脸识别程序,就是不只是检测还需要识别到人是谁。
来,搞人脸识别
要搞一个人脸识别程序,首先我们需要先用提前裁剪好的标注好的人脸照片训练一个识别器。比如说,我们的识别器需要识别两个人,一个人的id是1,而另一个的id是2,于是在数据集里面,1号人的所有照片会有id 1号,2号人同理。然后我们就会使用这些数据集照片去训练识别器,再从一个视频中识别出1号人。
我们把要做的事分成三部分:
- 创建数据集
- 训练
- 识别
在本文中,我们会尝试写一个程序来生成数据集。
生成数据集
我们来写一个数据集生成脚本。
首先打开我们的Python环境,不管是Pycharm等IDE,还是简单的记事本都行。需要提前准备的是在目录中放好haarcascade_frontalface_default.xml,上一篇也有用到过这个XML文件,就是OpenCV自带的。
接下来使用cv2获取摄像头数据以及XML文件:
import cv2
cam = cv2.VideoCapture(0)
detector=cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
我们的数据集需要先从摄像头采集一些人脸例子照片,当然,只能是同一个人的。然后程序会给这些例子照片添加id,并将照片保存在一个文件夹中,这个文件夹我们就将它命名为dataSet吧。
来,我们在py脚本的同目录下创建一个dataSet的文件夹。为了不会将不同的人脸照片弄混,我们需要定一个命名规则,用于给照片命名。
例如,命名规则为User.[ID].[SampleNumber].jpg。如果是2号人的第十张照片,我们可以将它命名为User.2.10.jpg。
为什么要定义这样的格式呢?因为这样,在加载照片训练的时候,我们就可以只通过照片的文件名,就能简单地判断是几号用户的人脸照片。
接下来,我们尝试用比较简单的方法,通过shell输入,来获取人的id,并且初始化计算器变量来存储人们的例子数。
Id = raw_input('enter your id: ')
sampleNum = 0
然后我们加入一个主循环,我们会从视频流中输入20个例子,然后把例子都保存在已经创建好的dataSet文件夹。
这是之前写过的代码版本,用于人脸检测:
while True:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
现在我们将它改造成数据集生成程序:
while True:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 增加例子数
sampleNum = sampleNum + 1
# 把照片保存到数据集文件夹
cv2.imwrite("dataSet/user." + str(Id) + '.' + str(sampleNum) + ".jpg", gray[y:y + h, x:x + w])
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
我们添加了两行代码,用以计算例子数,以及将人脸照片按照我们的命名规则保存为jpg格式。
其中有一个值得注意的地方,就是gray[y : y + h, x : x + w]。此处我们是把一张灰度图片看成一个二维数组(或二维矢量),然后使用python中[]截取OpenCV检测出来的人脸区域。
不过这样的代码会在一秒内快速地生成许多照片,比如说20张。我们不想要那么快,我们需要的是更好的素材,比如说从不同角度拍摄出来的照片,这样的话,要求慢一点。
为了慢一点,我们需要提高一下两次拍摄之间的延迟。同时,我们素材不需要太多,20张就好。
while True:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 增加例子数
sampleNum = sampleNum + 1
# 把照片保存到数据集文件夹
cv2.imwrite("dataSet/User." + str(Id) + '.' + str(sampleNum) + ".jpg", gray[y:y + h, x:x + w]) #
cv2.imshow('frame', img)
# 延迟100毫秒
if cv2.waitKey(100) & 0xFF == ord('q'):
break
# 超过20张就可以停了
elif sampleNum > 20:
break
好,继续,现在的代码就会在两个拍摄间延迟100毫秒,100毫秒足够让我们去移动我们人脸的角度了(时间不够长就再加)。而且,在拍摄20张后就停止了。
最后记得释放资源:
cap.release()
cv2.destroyAllWindows()
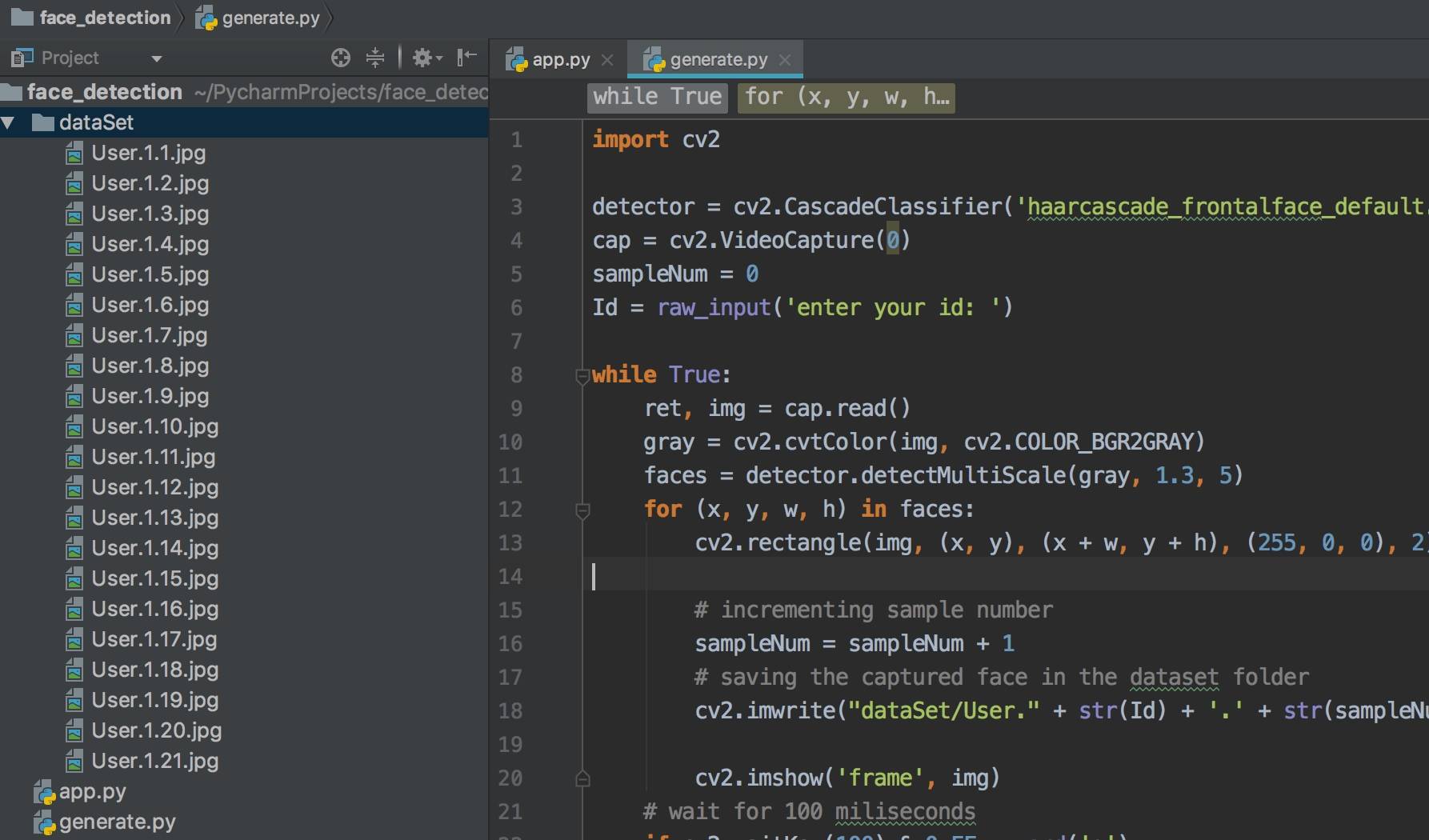
放出完整代码:
import cv2
detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
cap = cv2.VideoCapture(0)
sampleNum = 0
Id = raw_input('enter your id: ')
while True:
ret, img = cap.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# incrementing sample number
sampleNum = sampleNum + 1
# saving the captured face in the dataset folder
cv2.imwrite("dataSet/User." + str(Id) + '.' + str(sampleNum) + ".jpg", gray[y:y + h, x:x + w]) #
cv2.imshow('frame', img)
# wait for 100 miliseconds
if cv2.waitKey(100) & 0xFF == ord('q'):
break
# break if the sample number is morethan 20
elif sampleNum > 20:
break
cap.release()
cv2.destroyAllWindows()
生成结果
如图,已经生成了一堆训练素材了。
先这样吧
若有错误之处请指出,更多地关注煎鱼。







热门评论
-

BNUZYoung72018-10-11 0
查看全部评论为什么我用python3.7搭建opencv,设定收集20张人像,他收集数据的时候停不下来,无限循环