
鱼相信要成为一个更好的开发人员,你必须更好地理解你每天使用的底层软件系统,包括编程语言、编译器和解释器、数据库和操作系统、web服务器和web框架。
引言
有一天,一个女人出去散步到一个建筑工地,看见三个男人在工作。
她问第一个男人:“你在干什么?”第一个男人被这个问题惹恼了,叫道:“你没看见我在砌砖吗?”
她对回答不满意,问第二个人在做什么。第二个男人回答说:“我在建一堵砖墙。”然后,他把注意力转向第一个男人,说:“嘿,你刚砌过了墙的尽头。你需要把最后一块砖头摘下来。”
她又一次对答案不满意,问第三个人在干什么。那人抬头望着天空对她说:“我正在建造世界上最大的大教堂。”当他站在那里仰望天空时,另外两个人开始为那块乱七八糟的砖头争吵起来。男人转身对前两个人说:“嘿,伙计们,别担心那块砖头。这是一个内墙,它会被粉刷过,没有人会看到那块砖。换一层吧。”
这个故事的寓意是,当你了解整个系统,了解不同部分(砖块、墙壁、大教堂)如何组合在一起时,你可以更快地识别和解决问题(错误的砖块)。
文章这样的开头,与《创建一个简单的Web服务器》有什么关系?
鱼相信要成为一个更好的开发人员,你必须更好地理解你每天使用的底层软件系统,包括编程语言、编译器和解释器、数据库和操作系统、web服务器和web框架。而且,为了更好更深入地了解这些系统,你必须从头开始,一块一块地,一堵墙一堵墙地重新构建它们。
孔子这样说:
听而易忘
见而易记
做而易懂
鱼希望你可以相信,对不同的软件系统进行造轮子,来学习它们的工作方式,是一个好办法。
在这个由三部分组成的系列中,鱼将向你展示如何构建自己的基本Web服务器。Here we go!
初识Web服务器
首先,什么是Web服务器?

简单滴说,它是一个网络服务器,位于物理服务器之上(没看错,就是服务器上的服务器),然后它等待客户端发送请求。当它接收到请求时,它生成一个响应并将其发送回客户端。客户端和服务器之间的通信使用HTTP协议进行。客户端可以是你的浏览器,也可以是任何其他讲HTTP的软件。
最简单的Web服务器
一个非常简单的Web服务器实现是什么样子的?
可以看下鱼的这个例子,这个例子是用Python编写的(在Python3.7+上进行了测试),但是即使你不了解Python(这是一种很容易掌握的语言,请尝试!)你仍然应该能够从下面的代码和解释中理解概念:
# Python3.7+
import socket
HOST, PORT = '', 8888
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(1)
print(f'Serving HTTP on port {PORT} ...')
while True:
client_connection, client_address = listen_socket.accept()
request_data = client_connection.recv(1024)
print(request_data.decode('utf-8'))
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
client_connection.close()
将以上代码保存为webserver1.py,然后使用以下命令运行它:
$ python webserver1.py
Serving HTTP on port 8888 …
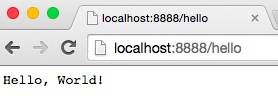
现在,在Web浏览器的地址栏输入http://localhost:8888/hello,按Enter,然后你应该看到“Hello World!”显示在浏览器中,如下所示:
快去实践一遍吧,简单地一匹!
分析Web服务器工作原理
鱼们来分析一下它到底是如何工作的。
首先让鱼们从你输入的网址开始。它被称为URL,其基本结构如下
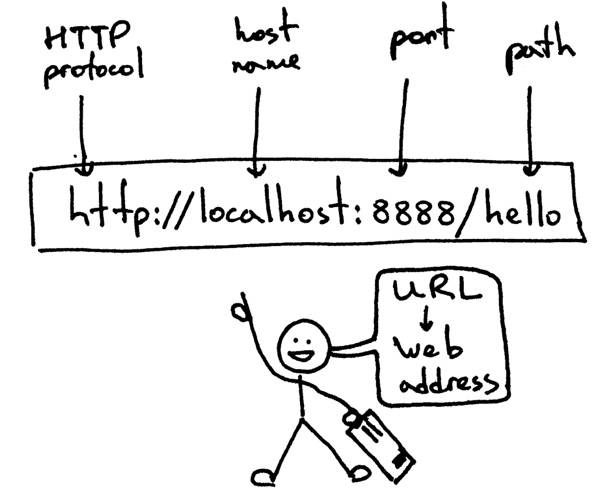
这个就是你要告诉浏览器的地址,相当于你要求浏览器查找和连接到的Web服务器的地址,以及服务器上要为你获取的页面(路径)。
但是,在浏览器发送HTTP请求之前,它首先需要与Web服务器建立TCP连接。然后浏览器通过TCP连接向服务器发送HTTP请求,并等待服务器发送HTTP响应。
当你的浏览器收到来自服务器的应答时,它会显示出来,在这种情况下,它会显示“Hello, World!”
现在,让鱼们来更详细地探讨,客户端和服务器在发送HTTP请求和响应之前如何建立TCP连接。为此,鱼使用所谓的套接字进行模拟。你将通过在命令行上使用telnet手动模拟浏览器,而不是直接使用浏览器。
在运行Web服务器的同一台计算机上,在命令行上启动telnet会话,指定要连接到本地主机和8888的端口,然后按Enter键:
$ telnet localhost 8888
Trying 127.0.0.1 …
Connected to localhost.
此时,你已经与本地主机上运行的服务器建立了TCP连接,并准备发送和接收HTTP消息。在下面的图片中,你可以看到一个服务器必须经过的标准过程,才能接受新的TCP连接。
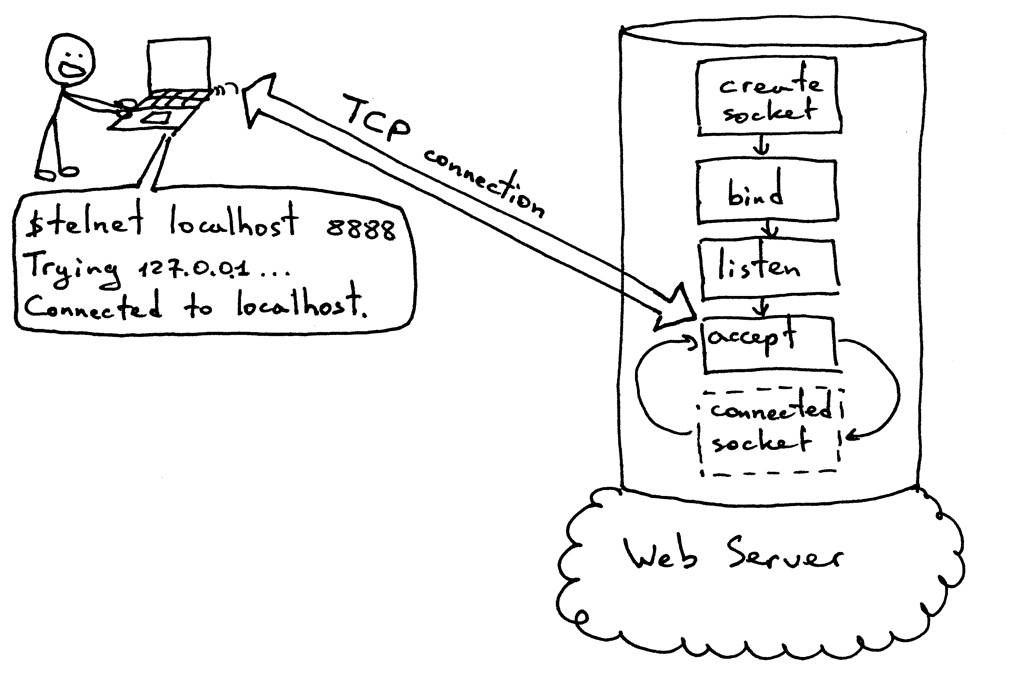
更多地关注造壳。
同时,鱼们继续试验,在同一个telnet会话中,输入“GET /hello HTTP/1.1”,然后按Enter:
$ telnet localhost 8888
Trying 127.0.0.1 …
Connected to localhost.
GET /hello HTTP/1.1
HTTP/1.1 200 OK
Hello, World!
就在此时,你手动模拟了你的浏览器!你发送了一个HTTP请求并得到了一个HTTP响应。这是HTTP请求的基本结构:

HTTP请求由这些元素组成:
- HTTP方法(GET)
- 表示所需服务器上的“页面”的路径(/hello)
- 协议版本(HTTP/1.1)
为了简单起见,鱼们的Web服务器此时完全忽略了上面的请求数据。你也可以输入任何垃圾而不是“GET/hello HTTP/1.1”,然后你仍然会得到一个“hello,World!”回应。
输入请求行并按Enter键后,客户机将请求发送到服务器,服务器读取请求行,打印请求行并返回正确的HTTP响应。
以下是服务器发送回客户端的HTTP响应(在本例中为telnet):
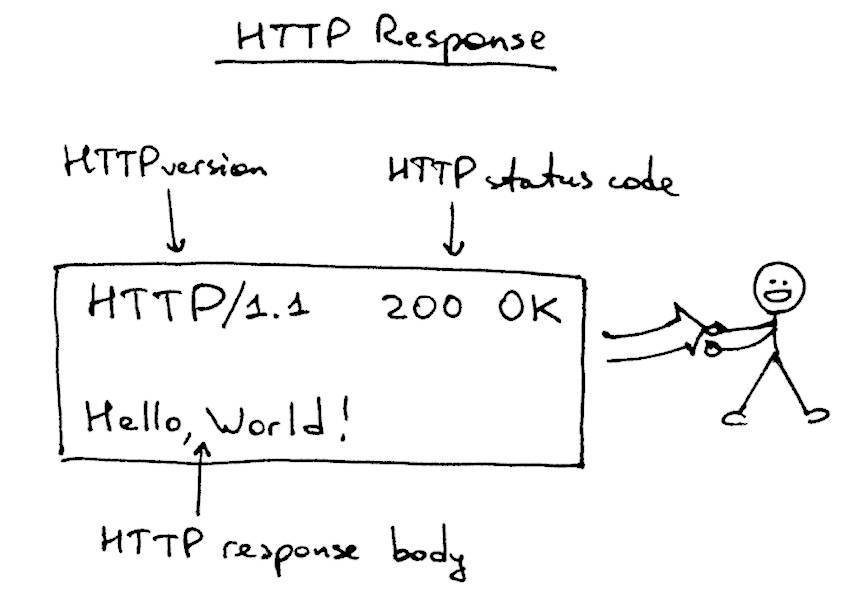
让鱼们解剖一下。HTTP响应由这几个元素组成:
- 响应状态行(协议版本+状态码/返回码),HTTP/1.1 200 OK,
- 一个必需的空行,
- HTTP响应体。
响应状态行HTTP/1.1 200 OK由HTTP协议版本、HTTP状态码和HTTP状态码原因短语OK组成。当浏览器得到响应时,它会显示响应的主体,这就是为什么你会看到“Hello,World!”在你的浏览器中。
这就是Web服务器工作的基本模式。总而言之:
- Web服务器创建一个监听套接字,并开始在循环中接受新连接。
- 客户端启动一个TCP连接,并在成功建立它之后,客户端向服务器发送一个HTTP请求,服务器返回HTTP响应结果,其中包含了展示给用户看的响应内容。
要建立TCP连接,客户端和服务器都使用套接字。
现在你有了一个非常基本的工作Web服务器,你可以使用浏览器或其他HTTP客户端进行测试。正如你已经看到并希望尝试过的那样,通过使用telnet并手动键入HTTP请求,你也可以成为一个人工HTTP客服端。
接下来鱼们要提出一个问题:
“在不对服务器进行任何更改的前提下,你如何在新开发的Web服务器下,运行/适配不同的Django应用程序、Flask应用程序和pyrampid应用程序”
解耦Web服务器和Python应用程序 —— WSGI
在过去,你对Python Web框架的选择会限制你对可用Web服务器的选择,反之亦然。如果框架和服务器设计为协同工作,那么一般是可行的:

但是,当你尝试将服务器和非设计为协同工作的框架结合在一起时,可能会遇到不match的问题:

基本上,你必须使用协同工作的东西,但有可能不是你想要使用的东西。比如你希望用ServerA的某个特性和FrameworkB的某个功能,但是FrameworkA不能满足你。
那么,如何确保可以使用多个Web框架运行Web服务器,而不必对Web服务器或Web框架进行代码更改呢?这个问题的答案就是Python Web服务器网关接口(简称WSGI,发音为wizgy)。

WSGI允许开发人员将Web框架与Web服务器解耦。现在,你可以混合和匹配Web服务器和Web框架,并选择适合你需要的配对。例如,可以使用Gunicorn、Nginx/uWSGI或Waitress运行Django、Flask或Pyramid。这样的解耦,得益于服务器和框架中的WSGI支持:
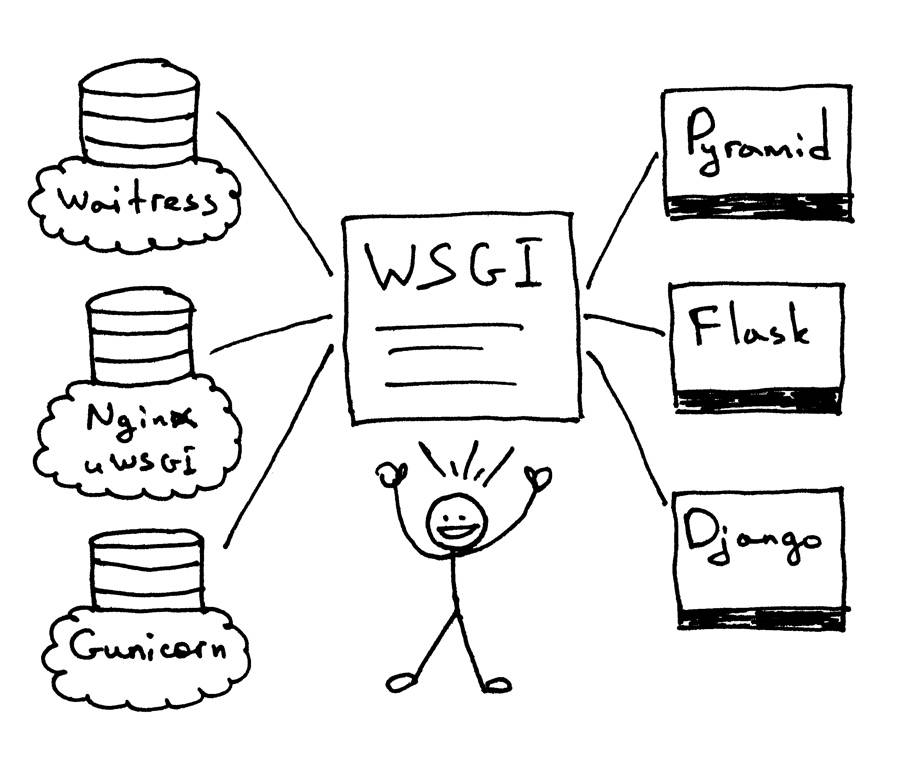
因此,WSGI就是问题的答案。你的Web服务器必须实现WSGI接口的服务器部分,并且要求所有的python web框架都已经实现了WSGI接口的框架端。这样,就可以将它们混合使用,而无需修改服务器代码以适应特定的Web框架。
现在你知道,Web服务器和Web框架对WSGI的支持允许你选择适合你的配对,但这也有利于服务器和框架开发人员,因为他们可以专注于自己喜欢的专业领域,而不是相互干涉。其他语言也有类似的接口:例如,Java有Servlet API,Ruby有Rack。
编写自己的WSGI服务器
理想很美好,但凡事都得“Show me the code”。鱼们来看看这个非常简单的WSGI服务器实现:
# Tested with Python 3.7+ (Mac OS X)
import io
import socket
import sys
class WSGIServer(object):
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
request_queue_size = 1
def __init__(self, server_address):
# Create a listening socket
self.listen_socket = listen_socket = socket.socket(
self.address_family,
self.socket_type
)
# Allow to reuse the same address
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# Bind
listen_socket.bind(server_address)
# Activate
listen_socket.listen(self.request_queue_size)
# Get server host name and port
host, port = self.listen_socket.getsockname()[:2]
self.server_name = socket.getfqdn(host)
self.server_port = port
# Return headers set by Web framework/Web application
self.headers_set = []
def set_app(self, application):
self.application = application
def serve_forever(self):
listen_socket = self.listen_socket
while True:
# New client connection
self.client_connection, client_address = listen_socket.accept()
# Handle one request and close the client connection. Then
# loop over to wait for another client connection
self.handle_one_request()
def handle_one_request(self):
request_data = self.client_connection.recv(1024)
self.request_data = request_data = request_data.decode('utf-8')
# Print formatted request data a la 'curl -v'
print(''.join(
f'< {line}\n' for line in request_data.splitlines()
))
self.parse_request(request_data)
# Construct environment dictionary using request data
env = self.get_environ()
# It's time to call our application callable and get
# back a result that will become HTTP response body
result = self.application(env, self.start_response)
# Construct a response and send it back to the client
self.finish_response(result)
def parse_request(self, text):
request_line = text.splitlines()[0]
request_line = request_line.rstrip('\r\n')
# Break down the request line into components
(self.request_method, # GET
self.path, # /hello
self.request_version # HTTP/1.1
) = request_line.split()
def get_environ(self):
env = {}
# The following code snippet does not follow PEP8 conventions
# but it's formatted the way it is for demonstration purposes
# to emphasize the required variables and their values
#
# Required WSGI variables
env['wsgi.version'] = (1, 0)
env['wsgi.url_scheme'] = 'http'
env['wsgi.input'] = io.StringIO(self.request_data)
env['wsgi.errors'] = sys.stderr
env['wsgi.multithread'] = False
env['wsgi.multiprocess'] = False
env['wsgi.run_once'] = False
# Required CGI variables
env['REQUEST_METHOD'] = self.request_method # GET
env['PATH_INFO'] = self.path # /hello
env['SERVER_NAME'] = self.server_name # localhost
env['SERVER_PORT'] = str(self.server_port) # 8888
return env
def start_response(self, status, response_headers, exc_info=None):
# Add necessary server headers
server_headers = [
('Date', 'Mon, 15 Jul 2019 5:54:48 GMT'),
('Server', 'WSGIServer 0.2'),
]
self.headers_set = [status, response_headers + server_headers]
# To adhere to WSGI specification the start_response must return
# a 'write' callable. We simplicity's sake we'll ignore that detail
# for now.
# return self.finish_response
def finish_response(self, result):
try:
status, response_headers = self.headers_set
response = f'HTTP/1.1 {status}\r\n'
for header in response_headers:
response += '{0}: {1}\r\n'.format(*header)
response += '\r\n'
for data in result:
response += data.decode('utf-8')
# Print formatted response data a la 'curl -v'
print(''.join(
f'> {line}\n' for line in response.splitlines()
))
response_bytes = response.encode()
self.client_connection.sendall(response_bytes)
finally:
self.client_connection.close()
SERVER_ADDRESS = (HOST, PORT) = '', 8888
def make_server(server_address, application):
server = WSGIServer(server_address)
server.set_app(application)
return server
if __name__ == '__main__':
if len(sys.argv) < 2:
sys.exit('Provide a WSGI application object as module:callable')
app_path = sys.argv[1]
module, application = app_path.split(':')
module = __import__(module)
application = getattr(module, application)
httpd = make_server(SERVER_ADDRESS, application)
print(f'WSGIServer: Serving HTTP on port {PORT} ...\n')
httpd.serve_forever()
代码还是比较简单的(不到150行),大家都可以理解,应该不会出现陷入细节泥潭的情况。上面的服务器还可以做更多的事情——它可以运行用你喜爱的Web框架编写的基本Web应用程序,无论是Pyramid、Flask、Django还是其他Python WSGI框架。
让鱼们来运行试试看。将上述代码保存为webserver2.py。如果你试图在没有任何参数的情况下运行它,它会提醒错误并退出。
$ python webserver2.py
Provide a WSGI application object as module:callable
它真的需要你的Web应用服务。要运行服务器,只需要安装Python。但是要运行使用Pyramid、Flask和Django编写的应用程序,你需要先安装这些框架,让鱼们把这三个都安装好。鱼首选的方法是使用venv创建一个虚拟环境,以免影响现有环境(venv在Python3.3版本以及以上默认自带)。只需按照下面的步骤创建并激活一个虚拟环境,然后安装所有三个Web框架。
$ python3 -m venv lsbaws
$ ls lsbaws
bin include lib pyvenv.cfg
$ source lsbaws/bin/activate
(lsbaws) $ pip install -U pip
(lsbaws) $ pip install pyramid
(lsbaws) $ pip install flask
(lsbaws) $ pip install django
搭建WSGI + Pyramid应用程序
此时,你需要创建一个Web应用程序。鱼们先从Pyramid开始。将以下代码另存为金字塔app.py保存到同一目录webserver2.py:
from pyramid.config import Configurator
from pyramid.response import Response
def hello_world(request):
return Response(
'Hello world from Pyramid!\n',
content_type='text/plain',
)
config = Configurator()
config.add_route('hello', '/hello')
config.add_view(hello_world, route_name='hello')
app = config.make_wsgi_app()
现在,你可以使用自己的Web服务器,来启动你的Pyramid应用程序了:
(lsbaws) $ python webserver2.py pyramidapp:app
WSGIServer: Serving HTTP on port 8888 ...
你刚才告诉服务器从python模块“Pyramid app”加载可调用的“app”,你的服务器现在可以接收请求并将它们转发到你的pyramid中叫app的应用程序。
同时,从webserver2.py代码中可以看出,应用程序现在只处理一个路由:/hello路由。在浏览器网站上输入http://localhost:8888/hello地址,按回车键,然后观察结果:

当然,你也可以在命令行中使用curl工具,也能达到同样的效果:
$ curl -v http://localhost:8888/hello
...
你可以看下服务器和curl都输出了些什么。
搭建WSGI + Flask应用程序
现在鱼们移步到Flask,跟着鱼一起做:
from flask import Flask
from flask import Response
flask_app = Flask('flaskapp')
@flask_app.route('/hello')
def hello_world():
return Response(
'Hello world from Flask!\n',
mimetype='text/plain'
)
app = flask_app.wsgi_app
将上述代码保存为flaskapp.py,然后允许它:
(lsbaws) $ python webserver2.py flaskapp:app
WSGIServer: Serving HTTP on port 8888 ...
在浏览器网站上输入http://localhost:8888/hello地址,按回车键:
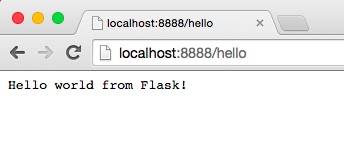
一样的,你也可以在命令行中使用curl工具:
$ curl -v http://localhost:8888/hello
...
搭建WSGI + Django应用程序
服务器还可以处理Django应用程序吗?当然可以,试试看!不过,它涉及的内容稍微多一些,鱼建议复制整个repo并使用djangoapp.py。
下面的源代码基本上将Django helloworld项目(使用Django的Django-admin.py startproject命令预先创建)添加到当前Python路径,然后导入项目的WSGI应用程序。
import sys
sys.path.insert(0, './helloworld')
from helloworld import wsgi
app = wsgi.application
将这段代码保存为djangoapp.py,然后运行起来:
(lsbaws) $ python webserver2.py djangoapp:app
WSGIServer: Serving HTTP on port 8888 ...
在浏览器网站上输入地址,按回车键:

虽然已经运行过很多次,但是你依然可以在命令行中使用curl工具,为了验证Django:
$ curl -v http://localhost:8888/hello
...
ok,到目前为止,鱼们把三个服务器都轮了一遍,如果你还没亲手试过,最好动下手,看是没啥用的。
WSGI程序分析
好吧,你已经体验过WSGI的强大功能:它允许你混合匹配你的Web服务器和Web框架。
WSGI在Python Web服务器和pythonweb框架之间提供了一个最小的接口。WSGI很简单,而且很容易在服务器端和框架端实现。
鱼们来分析下鱼们之前实现的WSGI的代码。
以下代码段显示了服务器和接口的框架端:
def run_application(application):
"""Server code."""
# This is where an application/framework stores
# an HTTP status and HTTP response headers for the server
# to transmit to the client
headers_set = []
# Environment dictionary with WSGI/CGI variables
environ = {}
def start_response(status, response_headers, exc_info=None):
headers_set[:] = [status, response_headers]
# Server invokes the ‘application' callable and gets back the
# response body
result = application(environ, start_response)
# Server builds an HTTP response and transmits it to the client
...
def app(environ, start_response):
"""A barebones WSGI app."""
start_response('200 OK', [('Content-Type', 'text/plain')])
return [b'Hello world!']
run_application(app)
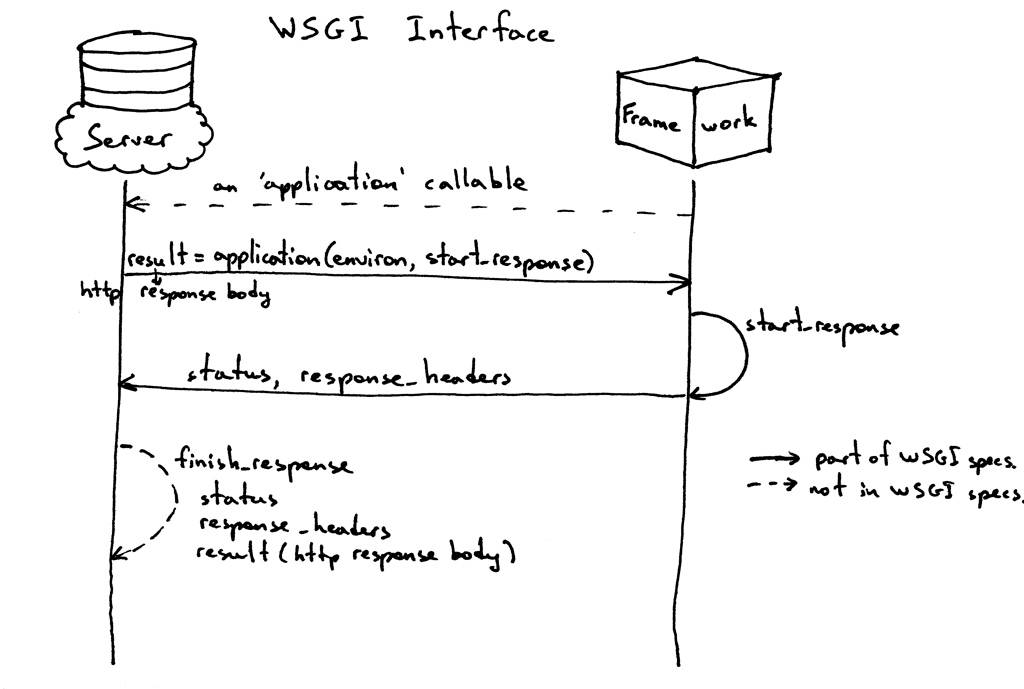
它的工作原理如下:
- 框架提供了一个可调用的“应用程序”(WSGI规范没有规定应该如何实现),指的就是鱼们的业务代码
- 服务器为从HTTP客户端接收的每个请求调用可调用的“应用程序”。它将包含WSGI/CGI变量的字典“environ”和可作为参数调用的“start_response”传递给可调用的“application”。
- 框架/应用程序生成一个HTTP状态和HTTP响应头,并将它们传递给服务器可调用的“start_response”来存储它们。框架/应用程序还返回一个响应体。
- 服务器将状态、响应头和响应体组合成一个HTTP响应并将其传输到客户端(此步骤不是规范的一部分,但它是流中的下一个逻辑步骤,一般都是需要的)
下面是界面的可视化表示:
到目前为止,鱼们已经轮过了Pyramid、Flask和Django Web应用程序,还看到了实现WSGI规范的服务器端的服务器代码。
当你使用这些框架之一编写Web应用程序时,你可以在更高的级别上工作,而不直接使用WSGI。
但鱼知道你对WSGI接口的框架方面也很好奇,因为你正在阅读本文。
更多地关注造壳。
因此,让鱼们创建一个极简的WSGI Web应用程序/Web框架,而不使用Pyramid、Flask或Django,并在服务器上运行它:
def app(environ, start_response):
"""A barebones WSGI application.
This is a starting point for your own Web framework :)
"""
status = '200 OK'
response_headers = [('Content-Type', 'text/plain')]
start_response(status, response_headers)
return [b'Hello world from a simple WSGI application!\n']
将上述代码保存为wsgiapp.py,运行它:
(lsbaws) $ python webserver2.py wsgiapp:app
WSGIServer: Serving HTTP on port 8888 ...
在浏览器网站上输入地址,按回车键:
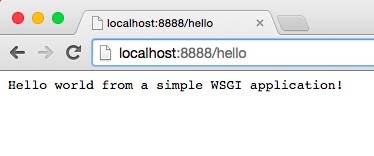
这样,鱼们就实现了一个极简的WSGI Web“框架”,没错,就是这么简单。
现在,让鱼们回到服务器向客户端传输的内容。
下面是服务器在使用HTTP客户端调用金字塔应用程序时生成的HTTP响应:

这个响应有一些是你在前文中能看到的熟悉部分,但它也有一些新的内容。例如,它有四个你以前从未见过的HTTP头:内容类型、内容长度、日期和服务器。其实这些是Web服务器响应通常应该具有的头。不过,这些都不是严格要求的。报头的目的是传输关于HTTP请求/响应的附加信息。
现在你已经了解了更多关于WSGI接口的信息,同样的,下面HTTP响应,其中包含了有关生成它的部分的更多信息:

鱼还没有提到“environ”字典,但基本上它是一个Python字典,必须包含WSGI规范指定的某些WSGI和CGI变量。服务器在分析请求后从HTTP请求中获取字典的值。这就是字典的内容:
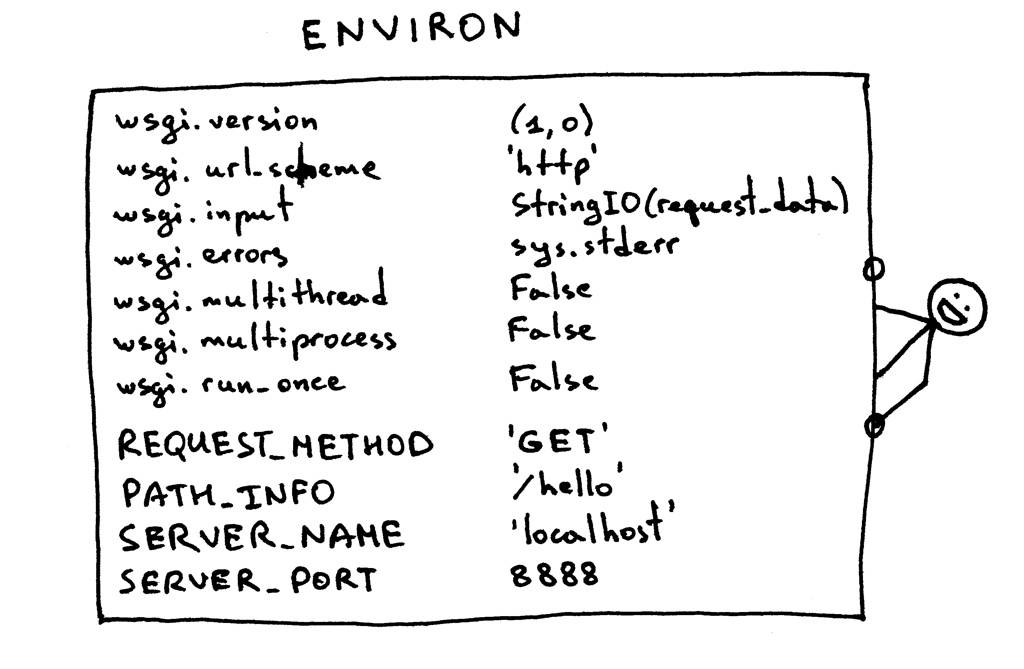
Web框架使用该字典中的信息,根据指定的路由、请求方法等信息,决定使用哪个视图、从何处读取请求体以及在何处写入错误(如果有的话)。
现在,你已经创建了自己的WSGI Web服务器,并使用不同的Web框架编写了Web应用程序。而且,你还创建了一个简单的Web应用程序/Web框架。
让鱼们回顾一下你的WSGI Web服务器必须做些什么来服务针对WSGI应用程序的请求:
首先,服务器启动并加载Web框架/应用程序提供的可调用的“应用程序”;
然后,服务器读取一个请求;
然后,服务器解析它;
然后,它使用请求数据构建一个“environ”字典;
然后,它用“environ”字典调用“application”,用“start_response”作为参数调用“start_response”,并返回一个响应体;
然后,服务器使用对“application”对象的调用返回的数据以及可调用的“start_response”设置的状态和响应头来构造HTTP响应;
最后,服务器将HTTP响应发送回客户端。
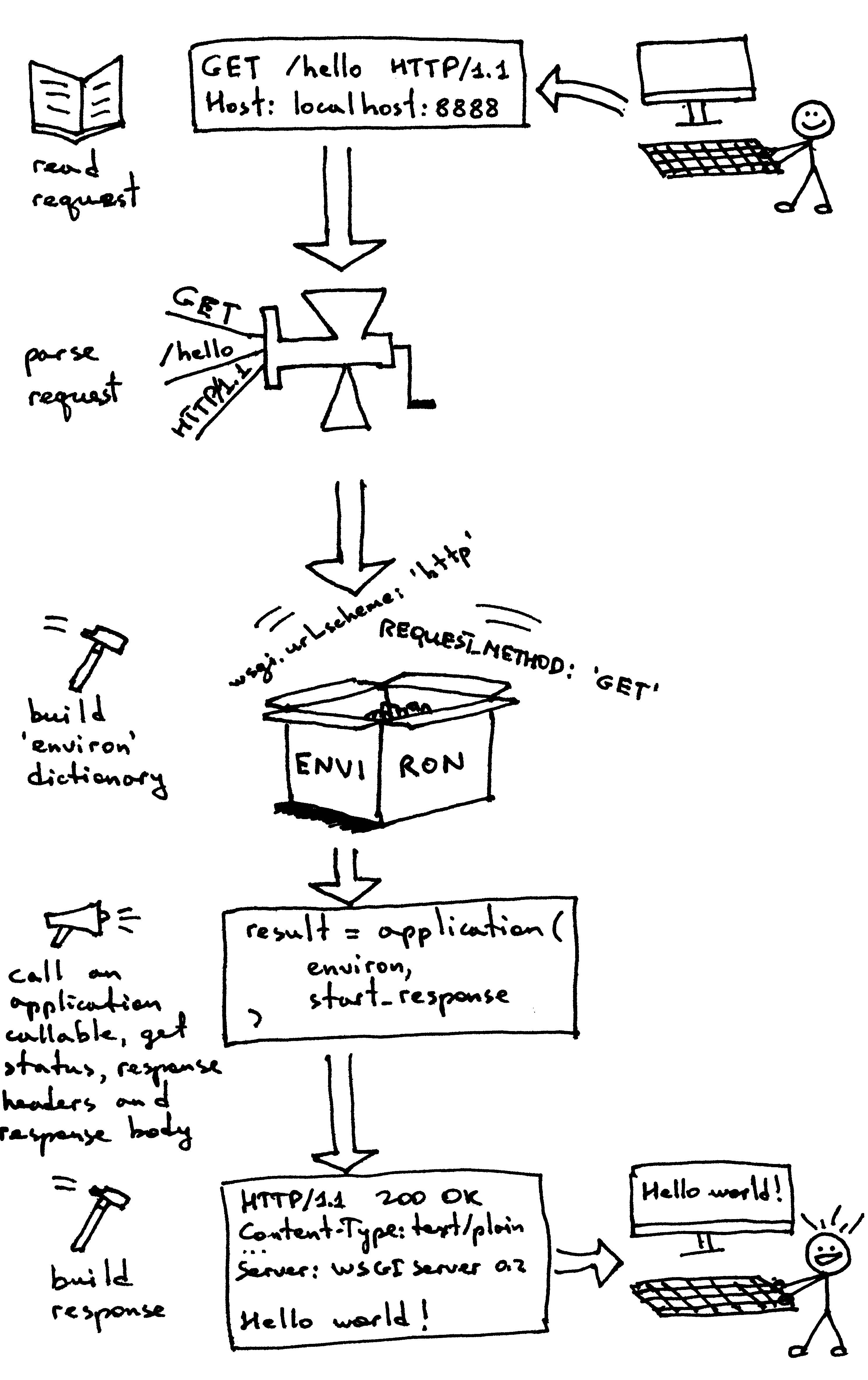
就是这些步骤,贯穿了鱼们的整个服务流程。
现在你有了一个可以工作的WSGI服务器,它可以为使用符合WSGI的Web框架(如Django、Flask、Pyramid或你自己的WSGI框架)编写的基本Web应用程序提供服务。最理想的,是服务器可以与多个Web框架一起使用,而不需要对服务器代码库进行任何更改。
但这还不够完美,甚至还有明显的缺点。
鱼们来思考一下:“为了提高你的程序的性能,你如何让你的服务器一次处理多个请求?”
创建并发服务器
在前面,鱼们创建了一个极简的WSGI服务器,它可以处理基本的HTTP GET请求。但是,它是一个“迭代服务器”,一次处理一个客户机请求。在处理完当前客户端请求之前,它无法接受新连接。有些客户端可能不满意,因为他们将不得不排队等候,而对于繁忙的服务器,排队现象尤其严重。

串行的“迭代服务器”
鱼们来看一眼鱼们的“迭代服务器”,webserver3a.py:
#####################################################################
# Iterative server - webserver3a.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
#####################################################################
import socket
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 5
def handle_request(client_connection):
request = client_connection.recv(1024)
print(request.decode())
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
while True:
client_connection, client_address = listen_socket.accept()
handle_request(client_connection)
client_connection.close()
if __name__ == '__main__':
serve_forever()
为了更直观地观察服务器一次只处理一个请求,鱼们稍微“降低一下性能”,修改服务器并在向客户端发送响应后添加60秒延迟。
“降低性能”的代码保存为webserver3b.py:
#########################################################################
# Iterative server - webserver3b.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
# #
# - Server sleeps for 60 seconds after sending a response to a client #
#########################################################################
import socket
import time
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 5
def handle_request(client_connection):
request = client_connection.recv(1024)
print(request.decode())
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
time.sleep(60) # sleep and block the process for 60 seconds
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
while True:
client_connection, client_address = listen_socket.accept()
handle_request(client_connection)
client_connection.close()
if __name__ == '__main__':
serve_forever()
然后运行起来:
$ python webserver3b.py
在命令行中请求一下,你马上就能看到“Hello, World!”:
$ curl http://localhost:8888/hello
Hello, World!
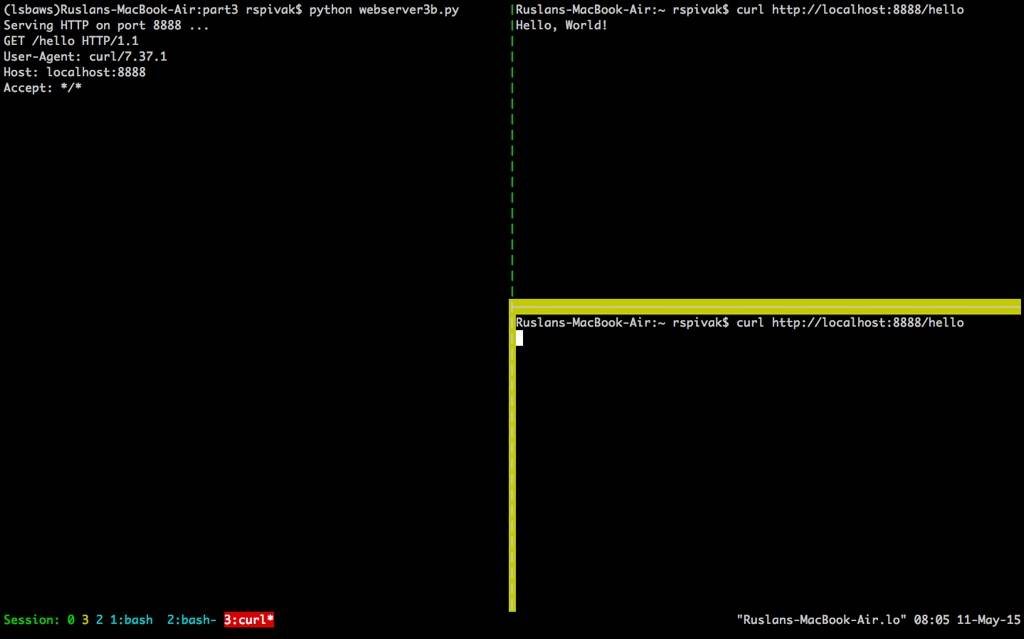
然后,紧接着,鱼们赶紧发起第二个请求:
$ curl http://localhost:8888/hello
如果你足够地“赶紧”,在60秒内完成了发起了这两个请求,那么第二个请求应该不会马上产生任何输出,而应该只是hung在那里。服务器也不应该在其标准输出上打印新的请求体。下面是在鱼的Mac上的情况(右下角以黄色突出显示的窗口显示第二个curl命令挂起,等待服务器接受连接):
当你等了60秒到了,你就会看到第二个“Hello, World!”出现了,然后服务器继续hung住60秒。
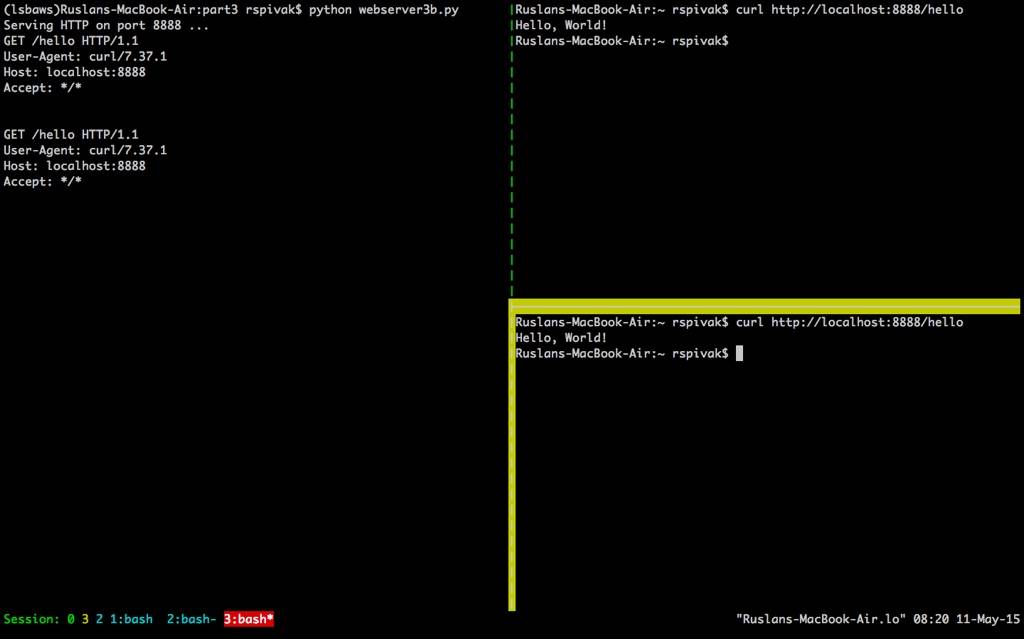
鱼们看到服务器完成对第一个curl客户机请求的服务,然后仅在第二个请求休眠60秒后才开始处理它。这一切都是因为“迭代服务器”是按顺序或迭代地进行的,一步一个步骤,或者在鱼们的情况下,一次处理一个请求。
Socket、进程、文件描述符是什么
为了更好地分析鱼们怎么解决这个性能问题,鱼们来谈谈客户端和服务器之间的通信。
鱼们为了让两个程序通过网络相互通信,必须使用套接字/Socket。前面的代码鱼们使用了Socker,那么什么是Socket?
Socket是通信端点的抽象,它允许你的程序使用文件描述符与另一个程序通信。在本文中,鱼将特别讨论Linux/Mac OS X上的TCP/IP socket。
其中,鱼们需要理解,什么是Socket Pair(套接字对)?
TCP连接的Socket Pair是一个4元组,用于标识TCP连接的两个端点:本地IP地址、本地端口、外部IP地址和外部端口。Socket Pair唯一标识网络上的每个TCP连接。标识每个连接点的两个值(IP地址和端口号)通常称为Socket。
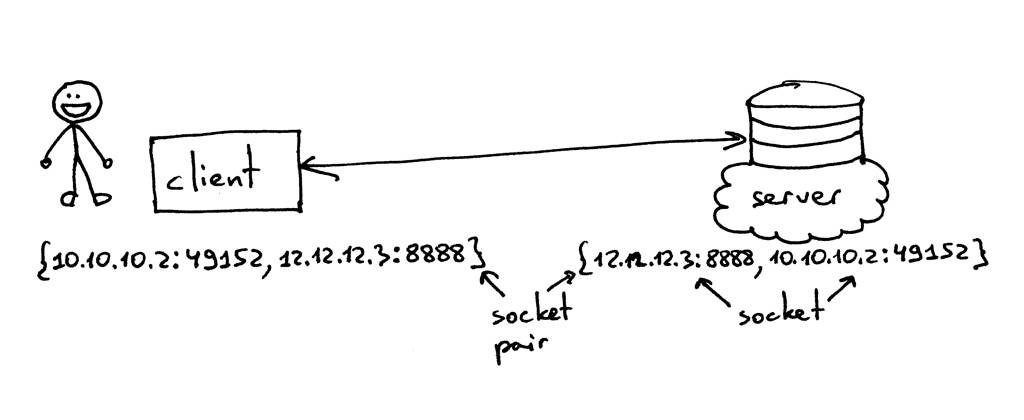
所以,元组{10.10.10.2:49152, 12.12.12.3:8888}是一个Socket Pair,它唯一地标识出客户端上两个终端的TCP连接;而元组 {12.12.12.3:8888, 10.10.10.2:49152}也是一个Socket Pair,标识出服务器上两个终端的TCP连接。地址12.12.12.3和端口8888两个值,能标识TCP连接的服务器端点,在这里鱼们称之为Socket(客户端依然)。
服务器创建Socket并开始接受客户端连接的标准顺序如下:
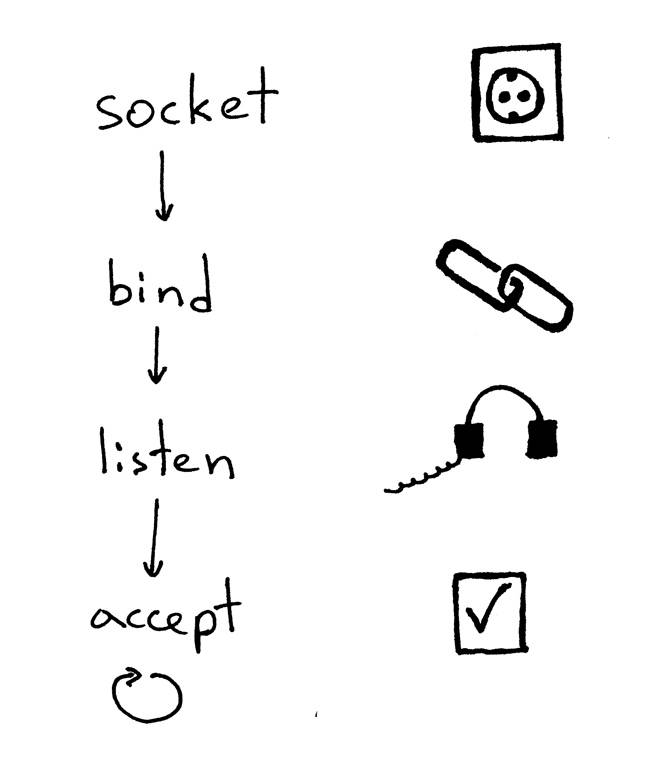
- 服务器创建TCP/IP Socket。这是通过Python语句完成的:
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- 服务器可能会设置一些Socket参数选项(这是可选的参数。鱼们可以看到上面实现过的服务器代码,使用的是REUSEADDR,正是为了能够反复使用同一地址)。
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
- 然后,服务器绑定地址。bind函数为Socket分配一个本地协议地址。对于TCP,调用bind允许你指定端口号、IP地址,或者两者都指定,或者都不指定。
listen_socket.bind(SERVER_ADDRESS)
- 然后,监听。
listen_socket.listen(REQUEST_QUEUE_SIZE)
listen方法仅由服务器调用,客户端没有。它告诉内核应该接受这个Socket的传入连接请求。
完成后,服务器开始在一个循环中一次接受一个客户端连接。当有可用的连接时,accept调用返回已连接的客户端Socket。然后,服务器从连接的客户端Socket中读取请求数据,在其标准输出上打印数据,并将消息发送回客户端。然后,服务器关闭客户端连接,并准备再次接受新的客户端连接。
鱼们再来看看客户端通过TCP/IP与服务器通信所需执行的操作:
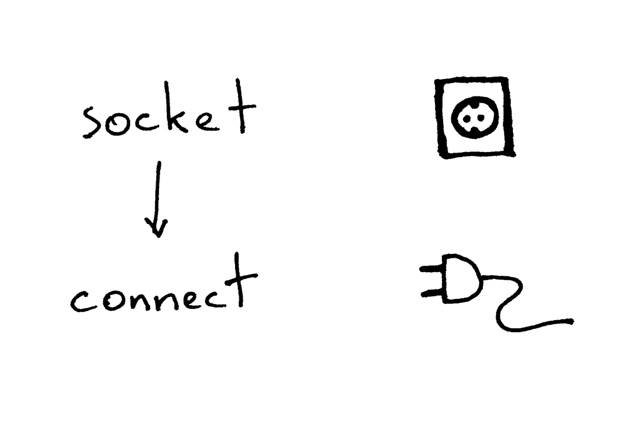
鱼们再看看客户端连接服务器再打印返回的代码,比较简单:
import socket
# create a socket and connect to a server
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(('localhost', 8888))
# send and receive some data
sock.sendall(b'test')
data = sock.recv(1024)
print(data.decode())
客户端创建完Socket之后,需要连接服务端,这是通过connect函数做到的:
sock.connect(('localhost', 8888))
客户端只需提供远程IP地址或主机名以及要连接到的服务器的远程端口号即可。
你可能已经注意到客户端没有调用bind和accept,是的,客户端不需要调用bind,因为客户端不关心本地IP地址和本地端口号。
当客户端调用connect时,内核中的TCP/IP堆栈会自动分配本地IP地址和本地端口。本地端口称为临时端口,一般来说很快就释放了。

一般,常用服务的端口称为常用端口,如HTTP服务的80端口,SSH服务的22端口。
如果你想知道你的客服端的本地端口是什么,可一启动Python shell并与在本地主机上运行的服务器建立客户端连接,然后查看内核为你创建的套接字分配的临时端口(在尝试以下示例之前启动服务器webserver3a.py或webserver3b.py):
>>> import socket
>>> sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
>>> sock.connect(('localhost', 8888))
>>> host, port = sock.getsockname()[:2]
>>> host, port
('127.0.0.1', 60589)
在上述情况下,内核将临时端口60589分配给Socket。
除了Socket之外,鱼需要快速介绍一些其他重要的概念,分别是进程和文件描述符。你很快就会明白这些概念为什么很重要。
什么是进程?进程只是执行程序的一个实例。例如,当服务器代码被执行时,它被加载到内存中,执行程序的一个实例称为进程。内核记录了一堆关于进程的信息,它的进程ID就是一个例子,用来跟踪它。当你运行迭代服务器webserver3a.py或webserver3b.py时,你只是运行一个进程。

在终端中启动webserver3b.py:
$ python webserver3b.py
在另一个终端中,使用ps命令查看这个进程:
$ ps | grep webserver3b | grep -v grep
7182 ttys003 0:00.04 python webserver3b.py
ps命令显示你实际上只运行了一个Python进程webserver3b。当创建一个进程时,内核会为它分配一个进程ID,即PID。在UNIX中,每个用户进程都有一个父进程,该父进程又有自己的进程ID,称为父进程ID,简称PPID。鱼假设你在默认情况下运行BASH shell,当你启动服务器时,会创建一个带有PID的新进程,其父PID设置为bashshell的PID。

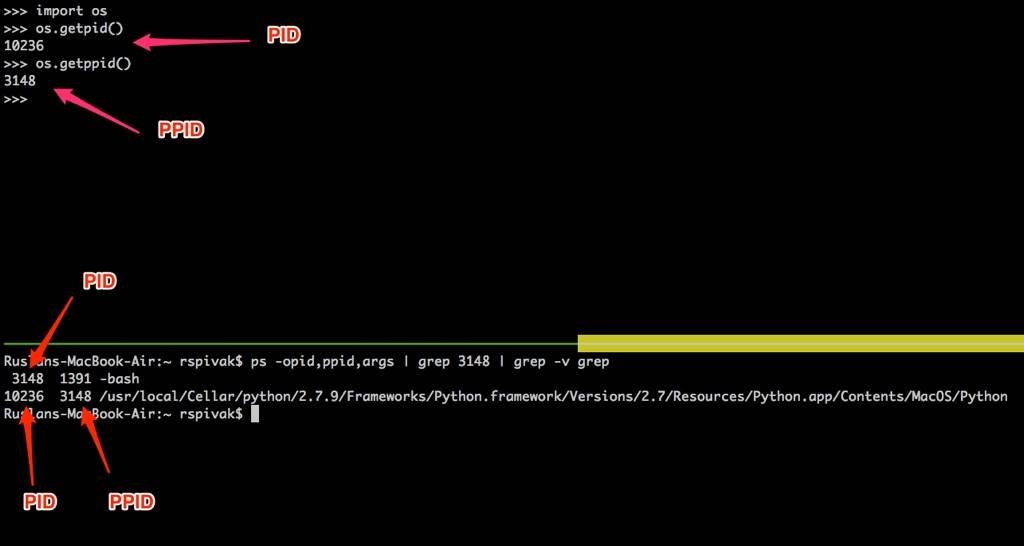
再次启动Python shell,它将创建一个新进程,然后鱼们使用os.getpid() 和os.getppid() 系统调用获取pythonshell进程的PID和父PID(bashshell的PID)。
然后,在另一个终端窗口中为PPID(父进程ID,在鱼的例子中是3148)运行ps命令和grep。在下面的屏幕截图中,你可以看到鱼的Mac OS X上的子Python shell进程和父BASH shell进程之间的父子关系示例:
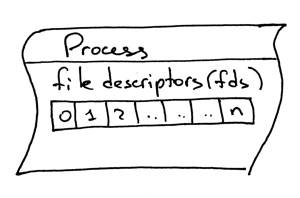
另一个需要知道的重要概念是文件描述符。那么什么是文件描述符?是一个非负整数。
?什么鬼非负整数?
内核在打开现有文件、创建新文件或创建新Socket时返回给进程一个非负整数,这个非负整数就是文件描述符。
你可能听说过,在UNIX中,一切都是文件。内核通过文件描述符引用进程的打开文件。当你需要读或写一个文件时,你可以用文件描述符来识别它。
Python为你提供了处理文件(和socket)的高级对象,你不必直接使用文件描述符来标识文件,但实际上,在UNIX中,文件和socket是通过它们的整数文件描述符来标识的。
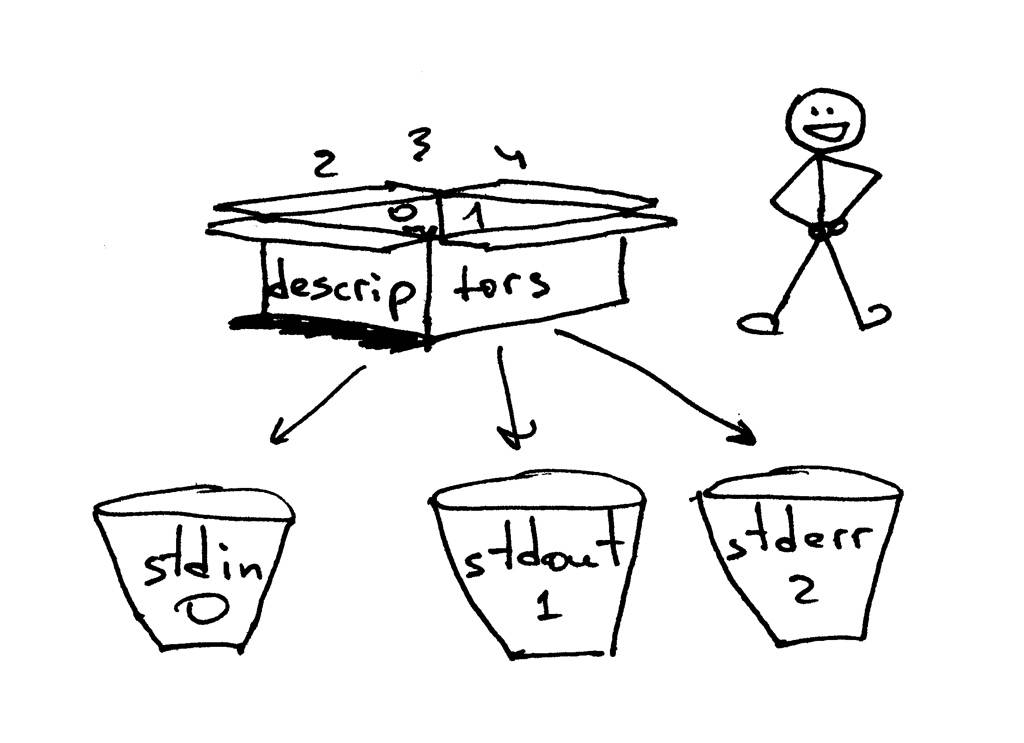
默认情况下,unixshell将文件描述符0分配给进程的标准输入,将文件描述符1分配给进程的标准输出,将文件描述符2分配给标准错误。
如前所述,尽管Python提供了一个高级文件或类似文件的对象,但你始终可以对该对象使用 fileno() 方法来获取与该文件关联的文件描述符。回到Python shell,看看鱼们如何做到这一点:
>>> import sys
>>> sys.stdin
<open file '<stdin>', mode 'r' at 0x102beb0c0>
>>> sys.stdin.fileno()
0
>>> sys.stdout.fileno()
1
>>> sys.stderr.fileno()
2
在Python中处理文件和Socket时,通常会使用高级文件/Socket对象,但有时可能需要直接使用文件描述符。
下面是一个例子,说明了如何使用以文件描述符整数为参数的write系统调用将字符串写入标准输出:
>>> import sys
>>> import os
>>> res = os.write(sys.stdout.fileno(), 'hello\n')
hello
这里有一个有趣的事,不过对你来说不再奇怪,因为你已经知道所有东西都是Unix中的一个文件,你的socket也有一个与之相关的文件描述符。同样,在Python中创建一个socket时,会返回一个对象,而不是一个非负整数,但你始终可以使用前面提到的fileno() 方法直接访问socket的整数文件描述符。
>>> import socket
>>> sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
>>> sock.fileno()
3
鱼还想提一件事:你是否注意到在“迭代服务器”webserver3b.py中,当服务器进程休眠60秒时,你仍然可以使用第二个curl命令连接到服务器?当然,curl没有立即输出任何内容,它只是挂在那里,但为什么服务器当时不接受连接,客户端也没有立即被拒绝,而是能够连接到服务器?答案是socket对象的listen方法及其BACKLOG参数,鱼在代码中称之为REQUEST-QUEUE-SIZE。BACKLOG参数确定内核中传入连接请求的队列大小。当服务器webserver3b.py处于睡眠状态时,你运行的第二个curl命令能够连接到服务器,因为内核在服务器套接字的传入连接请求队列中有足够的可用空间。
虽然增加BACKLOG参数并不能神奇地将你的服务器转变为一次可以处理多个客户机请求的服务器,但是对于繁忙的服务器,有一个相当大的backlog参数是很重要的,这样accept调用就不必等待建立新连接,而是可以立即从队列中获取新连接,并立即开始处理客户端请求。
到目前为止,文章以上的内容覆盖了很多知识点,鱼们复习下:

- 迭代服务器
- 服务器Socket创建序列 (socket, bind, listen, accept)
- 客户端Socket创建序列 (socket, connect)
- Socket Pair(套接字对)
- Socket
- 临时端口和常用端口
- 进程
- 进程id(PID),父进程id(PPID),父子进程关系
- 文件描述符
- BACKLOG参数的含义
使用fork编写并发服务器
现在鱼们已经准备好回答那一个问题:“为了提高你的程序的性能,你如何让你的服务器一次处理多个请求?”
或者鱼们换一个问法:“你怎么写一个并发的服务器呢?”

写一个并发服务器最简单的方法,是在Unix系统下使用fork()系统调用。
下面是新的闪亮登场的并发服务器的代码,命名为webserver3c.py,它可以同时处理多个客户端请求(在鱼们的迭代服务器示例webserver3b.py中,每个子进程睡眠60秒):

###########################################################################
# Concurrent server - webserver3c.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
# #
# - Child process sleeps for 60 seconds after handling a client's request #
# - Parent and child processes close duplicate descriptors #
# #
###########################################################################
import os
import socket
import time
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 5
def handle_request(client_connection):
request = client_connection.recv(1024)
print(
'Child PID: {pid}. Parent PID {ppid}'.format(
pid=os.getpid(),
ppid=os.getppid(),
)
)
print(request.decode())
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
time.sleep(60)
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
print('Parent PID (PPID): {pid}\n'.format(pid=os.getpid()))
while True:
client_connection, client_address = listen_socket.accept()
pid = os.fork()
if pid == 0: # child
listen_socket.close() # close child copy
handle_request(client_connection)
client_connection.close()
os._exit(0) # child exits here
else: # parent
client_connection.close() # close parent copy and loop over
if __name__ == '__main__':
serve_forever()
在深入讨论fork是如何工作的之前,鱼们先尝试一下并亲眼确认服务器确实可以同时处理多个客户机请求。
不同于webserver3a.py和webserver3b.py,使用以下命令行启动服务器:
$ python webserver3c.py
在迭代服务器上尝试同样的两个curl命令,然后鱼们可以看到,即使服务器子进程在服务客户机请求后睡眠60秒,它也不会影响其他客户端的请求,因为它们由不同的完全独立的进程提供服务。你应该看到curl命令输出“Hello,World!”马上就hung住60秒。你可以继续运行任意数量的curl命令(当然不能大于fd的上限),所有这些命令都将立即输出服务器的响应“Hello,World”,不会有任何明显的延迟。
关于fork()要注意一点,一个代码里面调用fork一次,它会返回两次:一次在父进程中,一次在子进程中。派生新进程时,返回给子进程的进程ID为0。当fork在父进程中返回时,它返回子进程的PID。
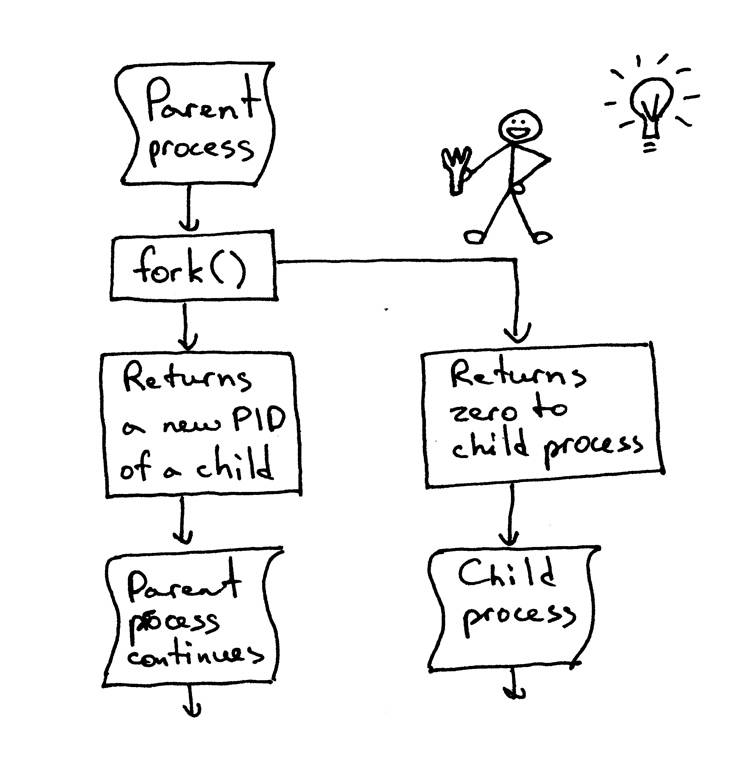
鱼依稀记得当鱼第一次读到并尝试fork的时候鱼是多么的迷,现在这在鱼看来依然很神奇。
更多地关注造壳。
当父进程派生新的子进程时,子进程将获取父进程的文件描述符的副本:

你可能注意到上面代码中的父进程关闭了客户端连接:
else: # parent
client_connection.close() # close parent copy and loop over
那么,当一个子进程的父进程关闭了同一个套接字,它为什么还能从客户端socket里面读取数据呢?
答案如上图所示。内核使用描述符引用计数来决定是否关闭socket。它只在其描述符引用计数变为0时,关闭套接字。
当服务器创建子进程时,子进程获取父进程文件描述符的副本,内核增加这些描述符的引用计数。在一个父进程和一个子进程的情况下,客户端socket的描述符引用计数为2,当上面代码中的父进程关闭客户端连接套接字时,它只会减少其引用计数,该计数将变为1,不足以导致内核关闭socket。
另外,子进程还关闭父进程侦听套接字的副本,因为子进程不关心接受新的客户端连接,它只关心处理来自已建立的客户端连接的请求:
listen_socket.close() # close child copy
鱼将在本文后面讨论如果不关闭重复的描述符会发生什么。
从并发服务器的源代码中可以看到,服务器父进程现在的唯一角色是接受一个新的客户端连接,派生一个新的子进程来处理该客户端请求,并循环接受另一个客户端连接,仅此而已。服务器父进程不处理客户端请求,而是让其子进程处理。
鱼们先讨论另一个问题,鱼们所说的两个事件同时发生是什么意思?
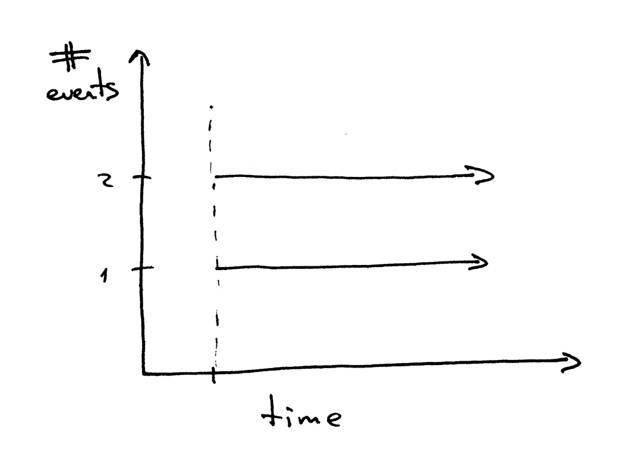
当鱼们说两个事件同时发生时,通常是指它们同时发生。这个定义很好,但你应该记住严格的定义:
如果你看不出哪个程序会先发生,那么两个事件是并发的。
再次重申一下,现在是时候回顾一下你迄今为止所涉及的主要思想和概念了。

- 在Unix中编写并发服务器的最简单方法是使用
fork()系统调用 - 当进程分叉新进程时,它将成为该新分叉子进程的父进程。
- 在调用fork之后,父级和子级共享相同的文件描述符。
- 内核使用描述符引用计数来决定是否关闭文件/socket
- 服务器父进程的角色:它现在所做的只是接受来自客户端的新连接,派生子进程来处理客户端请求,然后循环接受新的客户端连接。
回收文件描述符
让鱼们看看如果不关闭父进程和子进程中的重复套接字描述符,将会发生什么。webserver3d.py是并发服务器的修改版本,其中服务器不关闭重复的描述符:
###########################################################################
# Concurrent server - webserver3d.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
###########################################################################
import os
import socket
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 5
def handle_request(client_connection):
request = client_connection.recv(1024)
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
clients = []
while True:
client_connection, client_address = listen_socket.accept()
# store the reference otherwise it's garbage collected
# on the next loop run
clients.append(client_connection)
pid = os.fork()
if pid == 0: # child
listen_socket.close() # close child copy
handle_request(client_connection)
client_connection.close()
os._exit(0) # child exits here
else: # parent
# client_connection.close()
print(len(clients))
if __name__ == '__main__':
serve_forever()
运行起来:
$ python webserver3d.py
使用curl请求服务器:
$ curl http://localhost:8888/hello
Hello, World!
curl打印了并发服务器的响应,但它没有终止并一直挂起。服务器不再休眠60秒:其子进程主动处理客户端请求,关闭客户端连接并退出,但客户端这边的curl仍然没有终止。

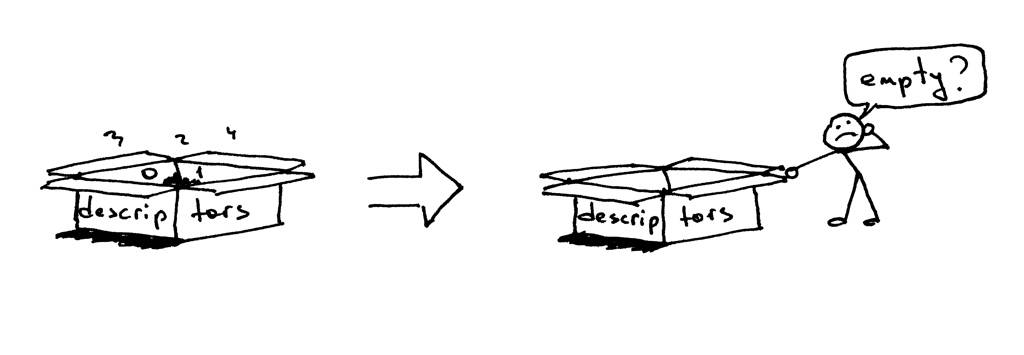
为什么curl不终止?原因是文件描述符还有余。
当子进程关闭客户端连接时,内核减少了该客户端套接字的引用计数,计数变为1。服务器子进程已退出,但客户端套接字未被内核关闭,因为该套接字描述符的引用计数不是0。因此,终止数据包(在TCP/IP术语中称为FIN)未发送到客户端,客户端保持在线。
如果长时间运行的服务器没有关闭重复的文件描述符,它最终将耗尽可用的文件描述符:
使用Control-C终止你webserver3d.py程序,检查下你所在服务器上的默认可用资源,可以使用ulimit命令:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 3842
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 3842
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
如上所示,在鱼的Ubuntu机器上,服务器进程可以使用的打开文件描述符(打开的文件)的最大数量是1024个。
现在让鱼们看看如果服务器不关闭重复的描述符,它将如何耗尽可用的文件描述符。在现有或新的终端窗口中,将服务器的最大打开文件描述符数设置为256:
$ ulimit -n 256
在同一个终端中启动服务:
$ python webserver3d.py
然后使用以下的自动化代码client3.py,模拟请求数量比较多的客户端:
#####################################################################
# Test client - client3.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
#####################################################################
import argparse
import errno
import os
import socket
SERVER_ADDRESS = 'localhost', 8888
REQUEST = b"""\
GET /hello HTTP/1.1
Host: localhost:8888
"""
def main(max_clients, max_conns):
socks = []
for client_num in range(max_clients):
pid = os.fork()
if pid == 0:
for connection_num in range(max_conns):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(SERVER_ADDRESS)
sock.sendall(REQUEST)
socks.append(sock)
print(connection_num)
os._exit(0)
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='Test client for LSBAWS.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
parser.add_argument(
'--max-conns',
type=int,
default=1024,
help='Maximum number of connections per client.'
)
parser.add_argument(
'--max-clients',
type=int,
default=1,
help='Maximum number of clients.'
)
args = parser.parse_args()
main(args.max_clients, args.max_conns)
在一个新的终端中,启动client3.py,请求量设定为300:
$ python client3.py --max-clients=300
很快你的服务器就会爆炸。这是鱼实验时异常的截图:
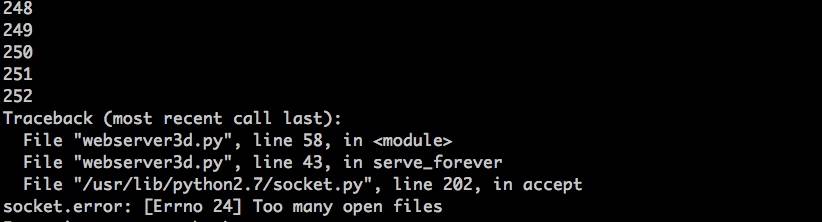
试验给鱼们带来的教训很清楚:服务器应该关闭重复的描述符。
僵尸进程的危害
但即使你关闭了重复的描述符,你还没有走出困境,因为你的服务器还有一个问题,那就是僵尸进程!
是的,其实你的服务器代码实际上创建了僵尸进程。让鱼们看看怎么做。鱼们先重新启动服务器:
$ python webserver3d.py
在另一个终端中,使用curl请求:
$ curl http://localhost:8888/hello
现在运行ps命令来显示正在运行的Python进程。这是鱼的Ubuntu上ps输出的例子:
$ ps auxw | grep -i python | grep -v grep
vagrant 9099 0.0 1.2 31804 6256 pts/0 S+ 16:33 0:00 python webserver3d.py
vagrant 9102 0.0 0.0 0 0 pts/0 Z+ 16:33 0:00 [python] <defunct>
你是否看到上面的第二行,其中显示PID 9102的进程的状态是Z+,进程的名称是?那是鱼们的僵尸进程。甚至鱼们还不能杀死他们。

即使鱼们使用kill -9,他们依然会存在。
什么是僵尸进程?为什么鱼们的服务器要创建僵尸进程?
僵尸进程是已终止的进程,但其父进程尚未等待它,也尚未收到其终止状态。当子进程在其父进程之前退出时,内核会将子进程变成僵尸进程,并存储一些有关该进程的信息,供其父进程以后检索。存储的信息通常是进程ID、进程终止状态和进程的资源使用情况。
所以说,僵尸进程是有目的的,但是如果你的服务器不处理这些僵尸进程,你的系统最终就会被阻塞。
让鱼们试验看看不清理僵尸进程会怎么样。
首先停止正在运行的服务器,并在新的终端窗口中,使用ulimit命令将max user processess设置为400(确保将open files设置为一个很高的数字,也就是说500):
$ ulimit -u 400
$ ulimit -n 500
在刚刚运行$ulimit-u 400命令的同一终端中,启动服务器webserver3d.py:
$ python webserver3d.py
在新的终端窗口中,启动client3.py并告诉它创建500个到服务器的同时连接:
$ python client3.py --max-clients=500
很快,你的服务器就会出现一个OSError:Resource temporary unavailable异常,当它试图创建一个新的子进程时,创建失败,因为它已经达到了允许创建的最大子进程数的限制。这是鱼机器上异常的截图:
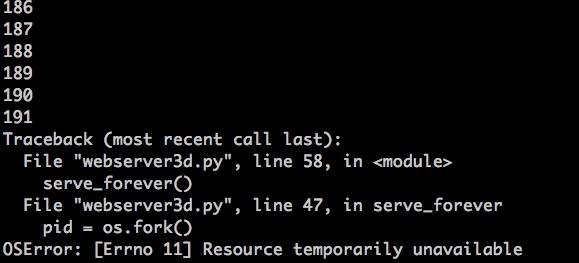
如你所见,如果不处理僵尸进程,就会给长期运行的服务器带来问题。鱼将后面会讨论服务器应该如何处理僵尸问题。
鱼们再回顾一下知识点:

- 如果不关闭重复的描述符,则客户端不会终止,因为客户端连接不会关闭。
- 如果不关闭重复的描述符,长期运行的服务器最终将耗尽可用的文件描述符(最大打开文件数)。
- 当派生子进程并退出,而父进程不等待它,也不收集其终止状态时,它将成为一个僵尸进程。
- 僵尸需要吃点东西,在鱼们的例子中,这是记忆。如果服务器不处理僵尸进程,那么它最终将耗尽可用进程(最大用户进程)。
- 你不能杀僵尸,你需要等待。
解决僵尸进程:信号处理程序 + 等待系统调用
那么你需要做什么来处理掉僵尸进程呢?你需要修改服务器代码,以等待僵尸进程,获得其终止状态。然后可以通过修改服务器来调用等待系统调用来完成此操作。
不幸的是,这远不是理想的,因为如果调用wait,将阻塞服务器,从而有效地阻止服务器处理新的客户端连接请求。还有其他选择吗?是的,有,其中一个是信号处理程序和等待系统调用的组合。

鱼们来看一下工作原理。当子进程退出时,内核发送一个SIGCHLD信号。父进程可以设置一个信号处理程序,以异步通知该SIGCHLD事件,然后它可以等待子进程收集其终止状态,从而防止僵尸进程留在周围。
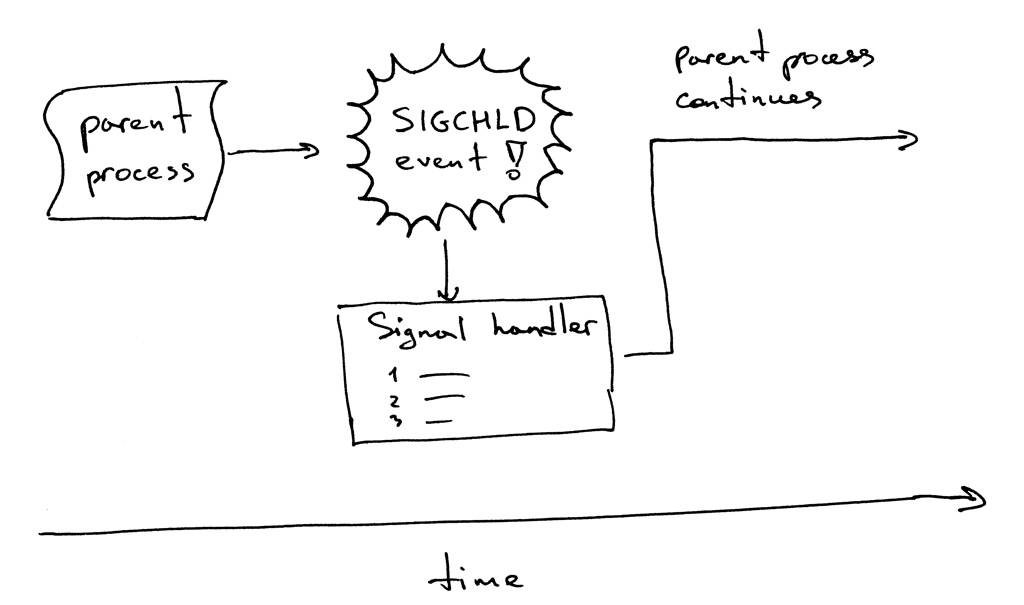
顺便说一下,异步事件意味着父进程不能提前知道事件将要发生。
修改服务器代码以设定SIGCHLD事件,并在事件处理程序中等待终止的子进程。修改代码得webserver3e.py文件:
###########################################################################
# Concurrent server - webserver3e.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
###########################################################################
import os
import signal
import socket
import time
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 5
def grim_reaper(signum, frame):
pid, status = os.wait()
print(
'Child {pid} terminated with status {status}'
'\n'.format(pid=pid, status=status)
)
def handle_request(client_connection):
request = client_connection.recv(1024)
print(request.decode())
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
# sleep to allow the parent to loop over to 'accept' and block there
time.sleep(3)
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
signal.signal(signal.SIGCHLD, grim_reaper)
while True:
client_connection, client_address = listen_socket.accept()
pid = os.fork()
if pid == 0: # child
listen_socket.close() # close child copy
handle_request(client_connection)
client_connection.close()
os._exit(0)
else: # parent
client_connection.close()
if __name__ == '__main__':
serve_forever()
启动服务器:
$ python webserver3e.py
再请求一次:
$ curl http://localhost:8888/hello
看服务器终端:

发生了什么呢?accept调用失败了,返回了EINTR错误。

当子进程退出导致SIGCHLD事件后,父进程accept调用会被阻塞,然后导致激活了信号处理程序,当信号处理程序完成时,accept系统调用被中断:

Don’t worry, it’s a pretty simple problem to solve, though. All you need to do is to re-start the accept system call. Here is the modified version of the server webserver3f.py that handles that problem:
不过这是个很简单的问题,只需要重新启动accept系统调用。修改版本webserver3f.py解决了这个问题:
###########################################################################
# Concurrent server - webserver3f.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
###########################################################################
import errno
import os
import signal
import socket
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 1024
def grim_reaper(signum, frame):
pid, status = os.wait()
def handle_request(client_connection):
request = client_connection.recv(1024)
print(request.decode())
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
signal.signal(signal.SIGCHLD, grim_reaper)
while True:
try:
client_connection, client_address = listen_socket.accept()
except IOError as e:
code, msg = e.args
# restart 'accept' if it was interrupted
if code == errno.EINTR:
continue
else:
raise
pid = os.fork()
if pid == 0: # child
listen_socket.close() # close child copy
handle_request(client_connection)
client_connection.close()
os._exit(0)
else: # parent
client_connection.close() # close parent copy and loop over
if __name__ == '__main__':
serve_forever()
启动升级后的webserver3f.py:
$ python webserver3f.py
请求一下:
$ curl http://localhost:8888/hello
现在不再有EINTR异常了。
接下来鱼们再验证是否不再有僵尸进程,以及带有wait调用的SIGCHLD事件处理程序是否处理已终止的子进程。
要做到这一点,只需运行ps命令,并亲自查看不再有Z+状态的Python进程(不再有进程)就ok了。

- 如果你用fork创建一个子进程而不wait它,它就会变成僵尸进程;
- 处理僵尸进程的方法:使用SIGCHLD事件处理程序,异步等待已终止的子进程获取其终止状态;
- 当使用事件处理程序时,你需要记住系统调用可能会被中断,并且你需要为该场景做好准备。
好吧,到目前为止还不错。没问题吧?好吧,差不多了。再次尝试webserver3f.py,但不要使用curl发出一个请求,而是使用client3.py创建128个同时连接:
$ python client3.py --max-clients 128
运行下ps命令看下:
$ ps auxw | grep -i python | grep -v grep
然而,僵尸进程还在。

这次是什么问题呢?当你同时运行128个客户端并建立128个连接时,服务器上的子进程处理这些请求并几乎同时退出,导致大量SIGCHLD信号被发送到父进程。问题是,信号没有排队,服务器进程错过了几个信号,导致几个僵尸进程无人值守:

解决这个问题的方法是,设置一个SIGCHLD事件处理程序,但是不要等待,而是在循环中使用带WNOHANG选项的waitpid系统调用,以确保所有终止的子进程都得到处理。以下是修改后的服务器代码webserver3g.py:
###########################################################################
# Concurrent server - webserver3g.py #
# #
# Tested with Python 2.7.9 & Python 3.4 on Ubuntu 14.04 & Mac OS X #
###########################################################################
import errno
import os
import signal
import socket
SERVER_ADDRESS = (HOST, PORT) = '', 8888
REQUEST_QUEUE_SIZE = 1024
def grim_reaper(signum, frame):
while True:
try:
pid, status = os.waitpid(
-1, # Wait for any child process
os.WNOHANG # Do not block and return EWOULDBLOCK error
)
except OSError:
return
if pid == 0: # no more zombies
return
def handle_request(client_connection):
request = client_connection.recv(1024)
print(request.decode())
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
def serve_forever():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind(SERVER_ADDRESS)
listen_socket.listen(REQUEST_QUEUE_SIZE)
print('Serving HTTP on port {port} ...'.format(port=PORT))
signal.signal(signal.SIGCHLD, grim_reaper)
while True:
try:
client_connection, client_address = listen_socket.accept()
except IOError as e:
code, msg = e.args
# restart 'accept' if it was interrupted
if code == errno.EINTR:
continue
else:
raise
pid = os.fork()
if pid == 0: # child
listen_socket.close() # close child copy
handle_request(client_connection)
client_connection.close()
os._exit(0)
else: # parent
client_connection.close() # close parent copy and loop over
if __name__ == '__main__':
serve_forever()
启动服务:
$ python webserver3g.py
发起请求:
$ python client3.py --max-clients 128
现在可以确认没有僵尸进程了。

总结
恭喜!代码的旅途很漫长,但总算结束了。
现在你拥有了自己的简单并发服务器,代码可以作为你进一步面向生产级Web服务器的基础。
接下来是什么?正如乔希·比林斯所说,
“就像一张邮票,坚持一件事,直到你到达那里。”
开始掌握基本知识,质疑你已经知道的,然后总是深入挖掘。

“如果你只学方法,你就会被方法束缚住。但如果你学会了原则,你就可以设计出自己的方法。” —— 爱默生。
下面是鱼为这篇文章中的大部分内容而绘制的书籍列表。它们将帮助你拓宽和加深你对鱼所涉及主题的知识。鱼强烈建议你以某种方式去买那些书:从你的朋友那里借,从你当地的图书馆里看,或者在亚马逊上买:
- Unix Network Programming, Volume 1: The Sockets Networking API (3rd Edition)
- Advanced Programming in the UNIX Environment, 3rd Edition
- The Linux Programming Interface: A Linux and UNIX System Programming Handbook
- TCP/IP Illustrated, Volume 1: The Protocols (2nd Edition) (Addison-Wesley Professional Computing Series)
- The Little Book of SEMAPHORES (2nd Edition): The Ins and Outs of Concurrency Control and Common Mistakes. Also available for free on the author’s site here.
先这样吧





