
本文以Elasticsearch 6.8.4版本为例,介绍Elasticsearch父子文档的使用。

上一篇文章介绍了Elasticsearch的嵌套文档,这一篇来介绍另外一种关系文档,父子文档。
1、父子文档
父子文档在理解上来说,可以理解为一个关联查询,有些类似MySQL中的JOIN查询,通过某个字段关系来关联。
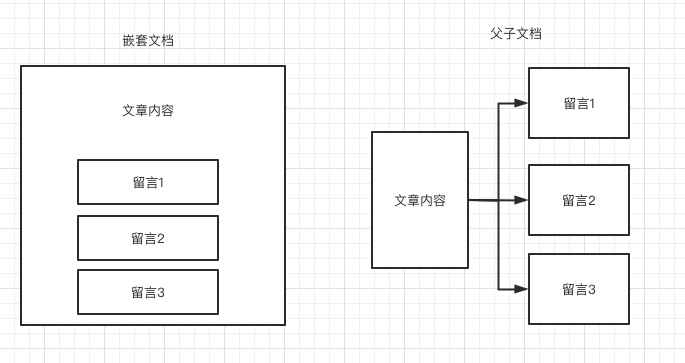
父子文档与嵌套文档主要的区别在于,父子文档的父对象和子对象都是独立的文档,而嵌套文档中都在同一个文档中存储,如下图所示:
这里引用官网的话,对比嵌套文档来说,父-子关系的主要优势有:
- 更新父文档时,不会重新索引子文档。
- 创建,修改或删除子文档时,不会影响父文档或其他子文档。这一点在这种场景下尤其有用:子文档数量较多,并且子文档创建和修改的频率高时。
- 子文档可以作为搜索结果独立返回。
1.1 创建索引
这里还是以嵌套文档的数据为例,假设数据如下:
[
{
"title":"这是一篇文章",
"body":"这是一篇文章,从哪里说起呢? ... ..."
},
{
"name":"张三",
"comment":"写的不错",
"age":28,
"date":"2020-05-04"
},
{
"name":"李四",
"comment":"写的很好",
"age":20,
"date":"2020-05-04"
},
{
"name":"王五",
"comment":"这是一篇非常棒的文章",
"age":31,
"date":"2020-05-01"
}
]
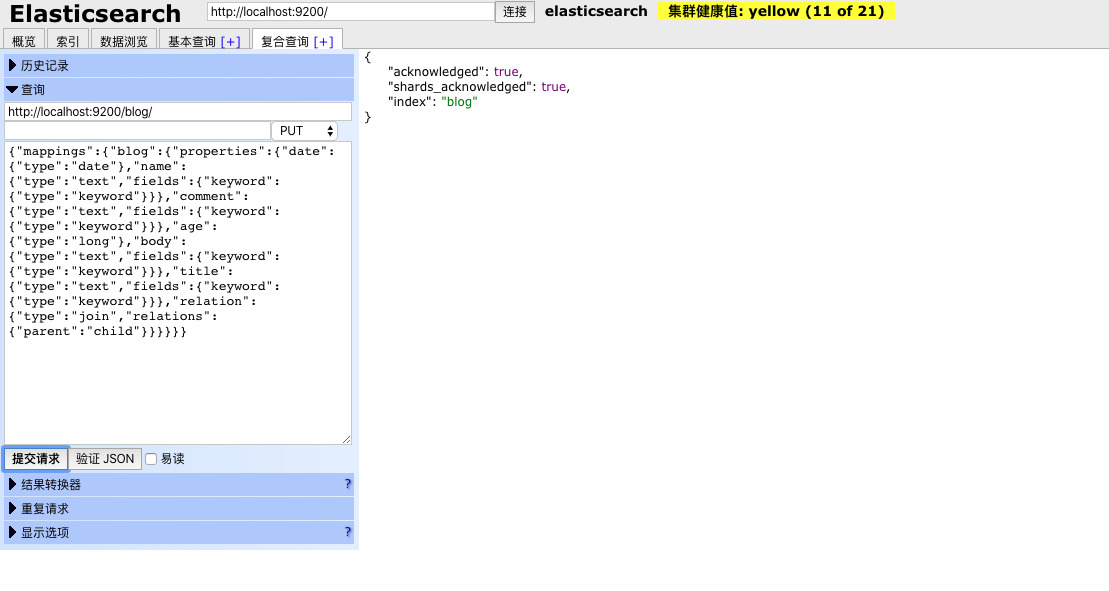
创建索引名和type均为blog的索引,从上面数据可以看出,其实父文档(博客内容)与子文档分别用不同的字段来存储对应的数据,不过在创建索引文档的时候需要指定父子文档的关系,即文章为parent,留言为child,创建索引语句如下:
{
"mappings": {
"blog": {
"properties": {
"date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"comment": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"age": {
"type": "long"
},
"body": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"relation": {
"type": "join",
"relations": {
"parent": "child"
}
}
}
}
}
}
如下图所示
1.2 插入数据
插入父文档数据,需要指定上文索引结构中的relation为parent,如下:
{
"title":"这是一篇文章",
"body":"这是一篇文章,从哪里说起呢? ... ...",
"relation":"parent"
}
插入子文档,需要在请求地址上使用routing参数指定是谁的子文档,并且指定索引结构中的relation关系,如下:
{
"name":"张三",
"comment":"写的不错",
"age":28,
"date":"2020-05-04",
"relation":{
"name":"child",
"parent":1
}
}
{
"name":"李四",
"comment":"写的很好",
"age":20,
"date":"2020-05-04",
"relation":{
"name":"child",
"parent":1
}
}
{
"name":"王五",
"comment":"这是一篇非常棒的文章",
"age":31,
"date":"2020-05-01",
"relation":{
"name":"child",
"parent":1
}
}
插入完成后,如下图所示。
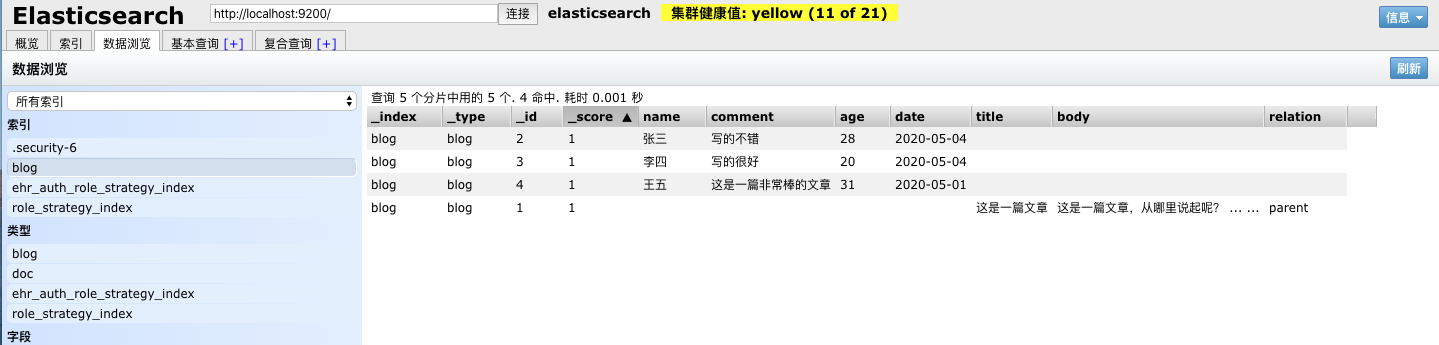
从这里其实可以很明显的看出与嵌套文档的区别了,嵌套文档只有一个文档,而这里是有四个文档。
1.3 查询
普通查询这里不进行赘述,关系查询的话其实很好理解,大致分为两种特殊情况:
- 根据父文档查询子文档 has_child
- 根据子文档查询父文档 has_parent
接下来我们来看如何进行关系查询,首先看一下通过子文档查询父文档,比如这样的场景,查询名称是张三的人留言的文章,查询语句如下:
{
"query": {
"has_child": {
"type":"child",
"query": {
"match": {
"name": "张三"
}
}
}
}
}
查询结果如下:
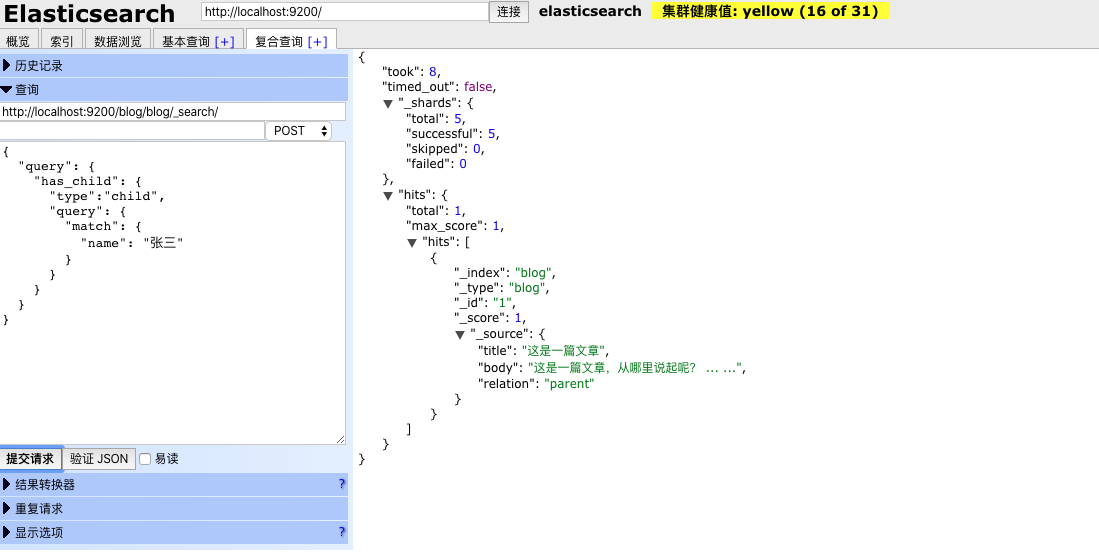
使用has_child来根据子文档内容查询父文档,其实type就是创建文档时,子文档的标识。
在使用子查父的时候,可以添加一些筛选条件来增强匹配的结果,比如最大匹配max_children和最小匹配min_children,这里有点类似should查询的minimum_should_match,感兴趣的可以去官网了解更多的细节。
到这里,其实对Elasticsearch特性了解的读者就会知道如何根据父文档查询子文档了,只需要注意一点,父查子type需要修改成parent_type,其余都与自查父类似,比如查询标题为“这是一篇文章”的数据的留言内容,查询语句如下:
{
"query": {
"has_parent": {
"parent_type":"parent",
"query": {
"match": {
"title": "这是一篇文章"
}
}
}
}
}
查询结果如下:
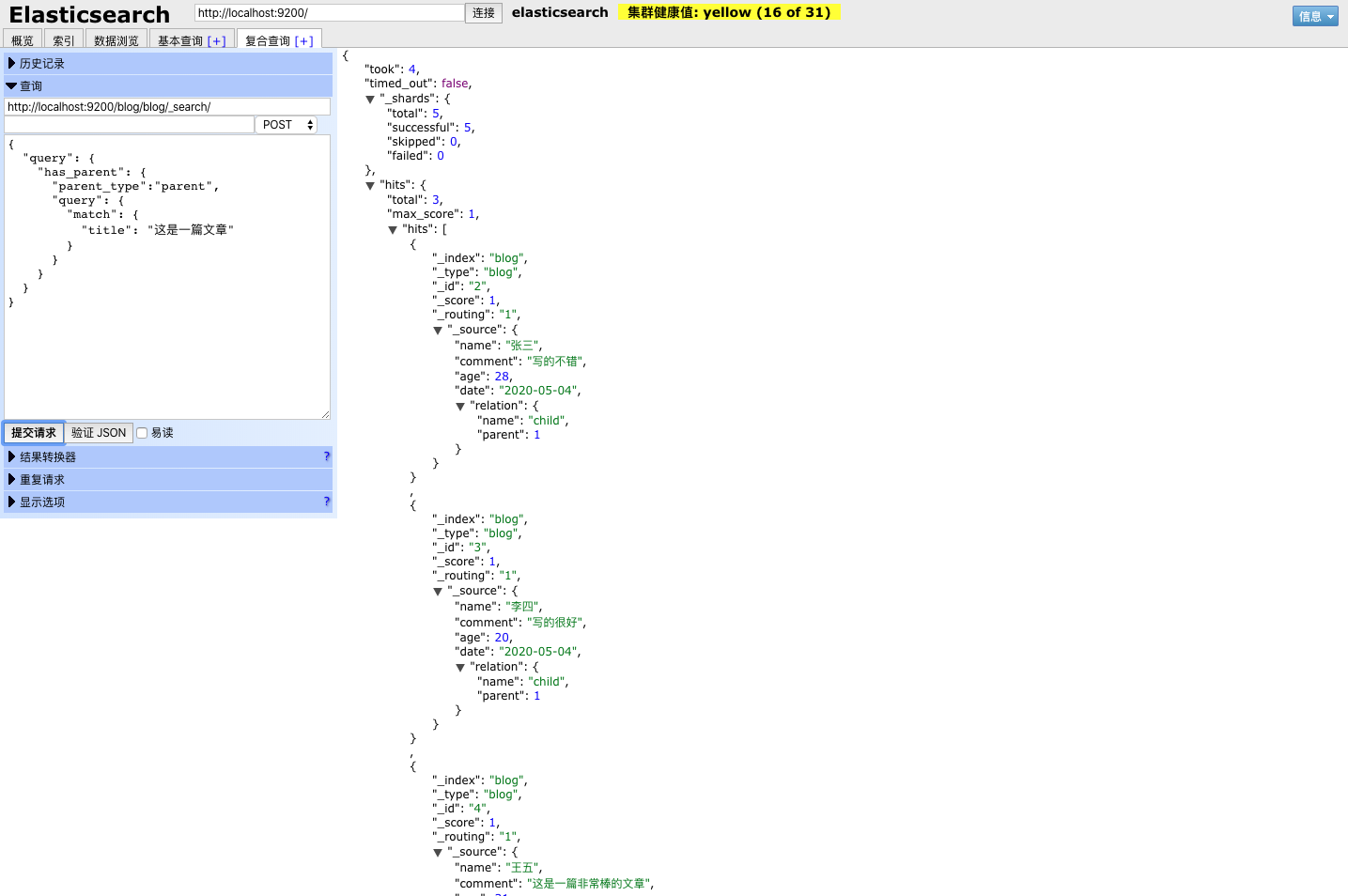
由于只有一组父子文档,效果不是很明显,感兴趣可以多造一些数据去体验
聚合查询与嵌套文档类似,比较简单,这里在说明另外一种场景:祖辈和孙辈可以创建吗?比如本文中的留言如果它也有子文档,那么可以根据文章查询孙辈吗?答案是可以的,只需要在has_child里面在嵌套一层has_child查询即可。
1.4 使用建议
- 父子文档都可以独立返回,对于某些场景很适用,比如主表信息是一些基本不变的数据,而子表信息经常增删改,并且子表信息经常有查询场景,这样就很适合使用父子文档。
- 父子文档需要在同一分片上,当然,我们无需做特殊处理,默认就会为我放入同一个分片,其实原理是这样的,Elasticsearch会根据routing中的参数去看父文档所在分片在哪,然后将对应文档存储进去。
- 父子文档查询效率相对嵌套文档较低,官网说是5-10倍左右。
其余官网也给定了一些建议,具体可以查看官方文档,地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/parent-child-performance.html





