
数据库表设计是项目开发中逃不掉的问题,每一张表,我们都会设计一个ID主键字段,关于表ID的生成方式,每个人都有自己的见解,我们就来讨论如何优雅的设计数据库ID
自增ID
这种方式用起来最简单,也是很多程序员喜欢用的方式。使用方法:mysql有auto_increment;oracle里有sequence
这种方式的缺点很明显,容易被探测,假设我是一个博客系统,某一遍文章的id=10,那么显示在浏览器上的地址大概是这样子:www.xxxx.com/article?id=10,对于有点程序经验的人来说,他就会直接在浏览器上打www.xxxx.com/article?id=11,id=12等,更甚的可以用postman,jmeter等http测试工具,这样就可以探测出所有的文章。博客文章系统可能还不要紧,但如果是一些商城系统,就容易泄露重要信息,比如系统有多少笔订单,每笔订单的金额、状态都可以被试探出来。
还有一个缺点,当我们在做一个新增操作时,这个ID是数据库自增的,但是代码业务层并不知道,如果我们要拿这个ID做其他操作,这时就只能重新查一遍数据库了。
数据库UUID
这种方式解决了自增ID容易被探测的问题,使用方法:mysql的uuid()函数,生成出来是32位的16进制数,在有生之年不会有重复,如下图:

但是它依然有一个缺点,就是新增操作时,业务层不知道ID,非要重新查一遍数据库才知道。
JAVA生成UUID
这种方式解决了数据库UUID的一个问题,ID是JAVA代码生成的,减少了一次数据库查询。这种方式是大多数项目在使用的方式,具体代码如下
public class UuidUtil {
/**
* 获得一个UUID
*/
public static String getUUID(){
String uuid = UUID.randomUUID().toString();
//去掉“-”符号
return uuid.replaceAll("-", "");
}
}
优雅的短UUID
JAVA生成UUID的方式虽然已经很通用了,但是依然有一个小缺点,占用的空间太大,所有表的ID都要占用32位的字符。所以我自己设计了一个短UUID,原理就是生成一个8位的62进制数,将所有的数字、大小写字母全部用上(数据库UUID是16进制,只用了数字和6个字母)。代码如下
public class UuidUtil {
public static String[] chars = new String[] { "a", "b", "c", "d", "e", "f",
"g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s",
"t", "u", "v", "w", "x", "y", "z", "0", "1", "2", "3", "4", "5",
"6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "I",
"J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V",
"W", "X", "Y", "Z" };
public static String getShortUuid() {
StringBuffer shortBuffer = new StringBuffer();
String uuid = UUID.randomUUID().toString().replace("-", "");
for (int i = 0; i < 8; i++) {
String str = uuid.substring(i * 4, i * 4 + 4);
int x = Integer.parseInt(str, 16);
shortBuffer.append(chars[x % 0x3E]);
}
return shortBuffer.toString();
}
}
生成的ID如下:
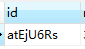
将UUID的32位的16进制数,每4位转成62进制,看不懂的直接用就是了,这样的短ID不仅有UUID不重复的特性,还不占用空间,8位ID在一些查询等操作的性能上也优于32位ID,这就是优雅的UUID设计方案。















热门评论
-

专杀小幕2020-04-29 16
-

慕粉21335098722020-04-29 3
-

qq_坚持v_02020-04-29 2
查看全部评论首先,uuid作为主键是非常影响数据库性能的,一是无序,二是太大,这点可以去了解一下mysql的实现架构与索引原理,而自增id才是非常推荐的做法,除非你的项目足够小,数据量不超过十万。然后是自己简单映射的所谓8字节uuid,因碰撞可能很难避免主键重复的尴尬
这样质量的文章就不要写了
疯了吧 字符串作主键