
前言
随着 Web 2.0 时代的到来,互联网的网络架构已经从传统的 C/S 架构转变为更加方便、快捷的 B/S 架构,B/S 架构大大简化了用户使用网络应用的难度,提高了用户体验。
B/S 架构带来了以下两方面的好处:
- 客户端使用统一的浏览器(
Browser)。由于浏览器具有统一性,不需要特殊的配置和网络连接。另外浏览器的交互特性使得用户使用它非常简便,且用户行为的可继承性非常强,也就是用户只要学会了上网,不管使用哪个应用,一旦学会了,便具备了使用其它任何互联网服务的经验。 - 服务端(
Server)基于统一的HTTP。和传统的 C/S 架构使用自定义的应用层协议不同。使用统一的 HTTP 简化了开发模式,并且基于 HTTP 的服务器又很多,如Apache、Nginx、Tomcat等,这些服务器可以直接拿来使用,不仅如此,连开发服务的通用框架也可以直接拿来使用,不需要单独开发,如Spring、Spring MVC、MyBatis等,我们只需关注服务的业务逻辑,同样简化了我们的开发工作。
B/S 网络架构概述
B/S 基于统一的应用层协议 HTTP 来交互数据,与大多数 C/S 互联网应用程序采用的长连接的交互模式不同。HTTP 采用无状态的短连接的通信方式,通常情况下,一次请求就完成了一次数据交互,然后这次通信连接就断开了。采用这种方式可以有效应对更多的用户请求。
当在浏览器里输入 antoniopeng.com 这个 URL 并按下回车键时,会发生很多操作:
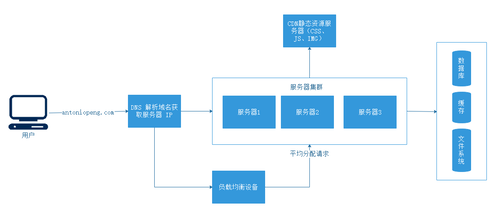
- 首先请求
DNS把这个域名解析成对应的IP地址。 - 然后根据这个
IP地址在互联网上找到对应的服务器,向这个服务器发起一个(GET/POST/…)请求。由这个服务器返回默认的数据资源给访问的用户,在服务端也可能还有很复杂的业务逻辑。- 服务器可能有很多台,由一台负载均衡设备(如
Nginx)来平均分配所有用户的请求。 - 还有请求的数据是存储在缓存里还是一个静态文件中,或是在数据库里。
- 服务器可能有很多台,由一台负载均衡设备(如
- 最后当数据返回浏览器时,解析到发现还有一些静态资源(如
CSS、JS、IMG)时又会发起另外的HTTP请求,而这些请求很可能会在CDN上,那么CDN服务器又会处理这些请求。
如何发起一个请求
这个问题简单又复杂,简单是指当我们在浏览器里数据一个 URL 时,按下回车键就发起了这个 HTTP 请求,很快就可以看到这个请求的返回结果。复杂是指不借助浏览器也能发起请求。
而一个 HTTP 连接本质上是一个 Socket 连接,那么我们可以完全模拟浏览器来发起 HTTP 请求。Apache HttpClient 就是一个开源的通过程序实现的处理 HTTP 请求的工具包。
下面是一个基于 HttpClient 的调用示例:
引入依赖
在 pom.xml 中添加 org.apache.httpcomponents:httpclient 依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.5</version>
</dependency>
创建 Http Get 请求
实现代码如下
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class MyTest {
public static void main(String[] args) {
get();
}
private static void get() {
// 创建 HttpClient 客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建 HttpGet 请求
HttpGet httpGet = new HttpGet("http://www.baidu.com");
// 设置长连接
httpGet.setHeader("Connection", "keep-alive");
// 设置代理(模拟浏览器版本)
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
// 设置 Cookie
httpGet.setHeader("Cookie", "UM_distinctid=34342706a09352-0376059833914f-3c604504-1fa400-16442706a0b345; CNZZDATA1262458286=1603637673-1530123020-%7C1530123020; JSESSIONID=805587506F1594AE02DC45845A7216A4");
CloseableHttpResponse httpResponse = null;
try {
// 请求并获得响应结果
httpResponse = httpClient.execute(httpGet);
HttpEntity httpEntity = httpResponse.getEntity();
// 输出请求结果
System.out.println(EntityUtils.toString(httpEntity));
} catch (IOException e) {
e.printStackTrace();
}
// 无论如何必须关闭连接
finally {
if (httpResponse != null) {
try {
httpResponse.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (httpClient != null) {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
除了在 Java 中使用非常普遍的 HttpClient 工具,另外在命令行中的 curl 命令,通过 curl + URL 就可以简单地发起一个 HTTP 请求
- 输入命令
curl https://www.baidu.com
- 返回 HTML 数据结果
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>鐧惧害涓€涓嬶紝浣犲氨鐭ラ亾</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=鐧惧害涓€涓?class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>鏂伴椈</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>鍦板浘</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>瑙嗛</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>璐村惂</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>鐧诲綍</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">鐧诲綍</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">鏇村浜у搧</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>鍏充簬鐧惧害</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>浣跨敤鐧惧害鍓嶅繀璇?/a> <a href=http://jianyi.baidu.com/ class=cp-feedback>鎰忚鍙嶉</a> 浜琁CP璇?30173鍙?nbsp; <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
HTTP 解析
要理解 HTTP,最重要的是要熟悉 HTTP 中的 HTTP Header,它控制着数据的传输。最重要的是,它控制着浏览器的渲染行为和服务器的执行逻辑。例如,当服务器没有用户请求的数据时就会返回一个 404 状态码,告诉浏览器没有要请求的数据,通常浏览器会展示一个非常不愿意看到的个 “该页面不存在” 的错误信息。
常见的 HTTP 请求头
| 请求头 | 说明 |
|---|---|
| Accept-Charset | 指定客户端接收的字符集 |
| Accept-Encoding | 指定可接受的编码(如 Accept-Encoding : gzip.deflate) |
| Accept-Language | 指定一种自然语言(如 Accept-Language : zh-cn) |
| Host | 指定被请求资源的主机和端口号(如 Host : www.baidu.com) |
| User-Agent | 客户端将它的操作系统、浏览器和其它属性告诉服务端 |
| Connection | 指定当前连接是否保持(如 Connection : Keep-Alive) |
常见的 HTTP 响应头
| 响应头 | 说明 |
|---|---|
| Server | 服务器名称(如 Server : nginx/1.17.6) |
| Content-Type | 发送给接收者的实体的类型(如 Content-Type : text/html;charset=GBK) |
| Content-Encoding | 与 Accept-Encoding 对应,服务端采用的编码 |
| Content-Language | 与 Accept-Language 对应,资源所用的自然语言 |
| Content-Length | 正文的长度 |
| Keep-Alive | 保持连接的时间(如 Keep-Alive : timeout=5) |
常见的 HTTP 状态码
| 状态码 | 说明 |
|---|---|
| 200 | 请求成功 |
| 302 | 临时跳转 |
| 400 | 客户端请求有语法错误,不能被服务器识别 |
| 403 | 服务器收到请求,但是拒绝提供服务,即没有权限 |
| 404 | 请求的资源不存在 |
| 500 | 服务器发生不可预期的错误 |
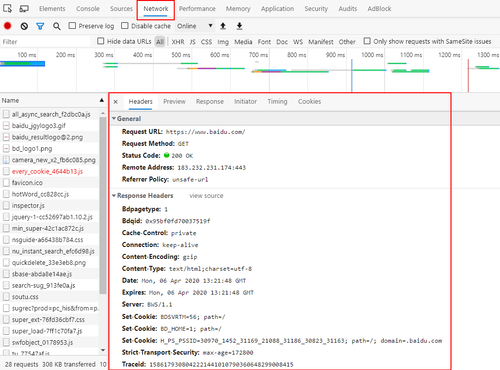
查看 HTTP 信息
要看一个 HTTP 请求的请求头和响应头可以通过 F12 快捷键打开浏览器的调试工具查看,例如我们正在访问 www.baidu.com,按下 F12 并打开 Network 调试栏可以看到以下 HTTP Header 内容
浏览器缓存机制
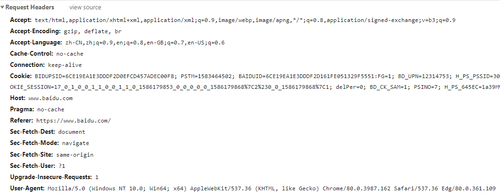
当浏览一个网页发现有异常时,通常要考虑的就是是不是浏览器做了缓存,所以一般的做法就是按 Ctrl + F5 组合键重新请求一次这个页面,这样的话请求的肯定是最新的页面。因为按 Ctrl + F5 组合键会直接向目标 URL 发送请求,而不会使用浏览器缓存的数据。
如图所示,这次请求没有到服务端,使用的是浏览器的缓存数据
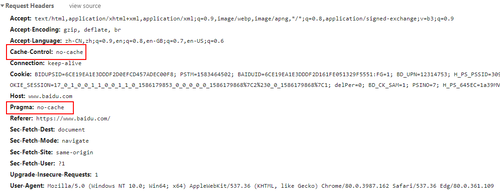
按 Ctrl + F5 组合键刷新页面后,会发现在 HTTP 的请求头中通常多了两个参数,分别是 Cache-Control:no-cache 和 Pragma:no-cache,该参数作用就是请求内容不会被缓存
DNS 域名解析
互联网是通过 URL(统一资源定位符)来发布和请求资源的,而 URL 中的域名需要解析成 IP 地址才能与远程主机建立连接,如何将域名解析成 IP 地址就属于 DNS 解析的工作范畴。
当用户在浏览器里输入 www.baidu.com 时,DNS 解析的工作步骤大体如下
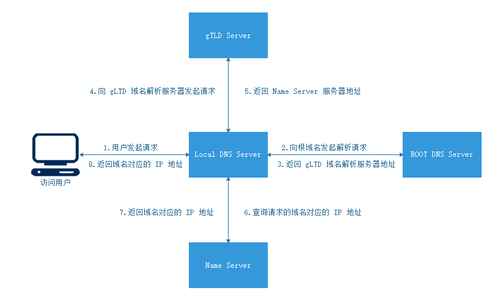
- 首先浏览器会先检查缓存中有没有这个域名对应的解析过的 IP 地址。如果缓存中有,这个解析过程就将结束。域名的缓存时间限制可以通过
TTL属性来设置。 - 如果浏览器缓存中没有,会检查操作系统中是否有这个域名对应的
DNS解析结果,在 Windows 中可以通过C:\Windows\System32\drivers\etc\hosts文件来设置,在 Linux 中这个配置文件是/etc/hosts,修改这个文件同样可以配置域名解析的 IP 结果。 - 如果以上步骤无法完成域名的解析,就会真正请求域名服务器来解析这个域名了。操作系统会先把域名发送给
Local DNS Server,也就是本地区的域名服务器。例如你在学校接入校园网,那么本地域名服务器肯定在你的学校,如果你是在一个小区接入互联网,那这个Local DNS Server就是提供给你接入互联网的应用提供商(电信、移动或联通),通常会在城市里的某个角落,不会很远。 - 如果
Local DNS Server仍然没有命中,就直接到ROOT DNS Server(根域名服务器)请求解析。 - 根域名服务器会返回给本地域名服务器一个所查询域名的
gLTD Server(主域名服务器)地址,gLTD是国际顶级域名服务器,如.com、.cn等。 Local DNS Server(本地域名服务器)会再向刚才返回的gTLD Server发送请求。- 接受请求的
gTLD Server查找并返回此域名对应的Name Server域名服务器的地址,这个Name Server通常就是你注册的域名服务提供商(例如阿里云-万网)。 Name Server再查询存储的域名和 IP 的映射关系表,正常情况下,域名得到 IP 记录,连同一个TTL值返回给Local DNS Server(本地域名服务器)。Local DNS Server会缓存这个域名和 IP 的对应关系,缓存时间由TTL值控制,最后把解析的结果返回给用户。
域名解析方式
域名解析记录主要分为 A 记录、MX 记录、CNAME 记录、NS 记录和 TXT 记录。
- A 记录:指定域名对应的 IP 地址(多个域名可以解析到同一个 IP,而一个 IP 只能指向一个域名)。
- MX 记录:将其它某域名下的邮件服务器指向自己的邮件服务器。
- CNAME 记录:将一个域名指向另一个域名。
- NS 记录:指定 DNS 解析服务器。
- TXT 记录:为某个主机名或域名设置说明。
CDN 工作机制
CDN 也就是内容分布网络,以缓存网站中的静态数据为主,如 CSS、JS、IMG 等数据。用户先从主站服务器请求到动态内容后,再从 CDN 上下载这些静态数据,从而加速网页数据内容的下载速度。
通常来说 CDN 要达到可扩展性、安全性、可靠性几个目标。工作步骤如下:
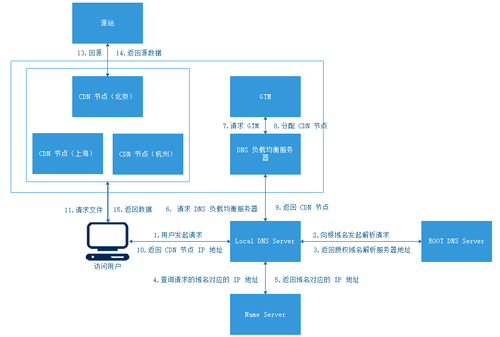
- 首先向
Local DNS Server本地域名解析服务器发起请求,一般经过迭代解析后回到这个域名的注册服务商去解析。 - 通常会有一台
DNS解析服务器会把这个域名重新CNAME解析到另外一个域名,而这个域名最终会被指向CDN全局中的DNS负载均衡服务器,再由GTM根据访问用户的地址,返回给离这个访问用户最近的CDN节点。 - 拿到
CDN解析结果后,用户就直接去这个CDN节点访问这个静态文件了,如果这个节点中所请求的文件不存在,就会再回到源站去获取这个文件,然后再返回给用户。
负载均衡
负载均衡(Load Balance)是对工作任务进行平衡、分摊到多个操作单元上执行,共同完成任务。
它可以提高服务器响应速度及利用效率,避免软件出现单点失效,解决网络排塞问题。
通常有三种负载均衡架构:
- 链路负载均衡:优点是:不需要经过其它代理服务器,通常访问速度会很快,缺点是有缓存,难以及时更新域名解析结构。
- 集群负载均衡
- 硬件负载均衡:优点是性能非常好,缺点是非常贵,不能进行动态扩容。
- 软件负载均衡:优点是成本非常低,缺点是一般一次访问请求要经过多次代理服务器,增加网络延时。
- 操作系统负载均衡:利用操作系统级别的软中断或者硬中断来达到负载均衡,如设置多列网卡等来实现。
CDN 动态加速
技术原理:在 CDN 的 DNS 解析中通过动态的链路探测来寻找回源最好的一条路径,然后通过 DNS 的调度将所有请求调度到选定的这条路径上回源,从而加速用户访问的效率。
链路探测:在每个 CDN 节点上从源站下载一个一定大小的文件,看哪个链路的总耗时最短,这样就可以构成一个链路列表,然后绑定到 DNS 解析上,更新到 Local DNS Server。
- 文章作者:彭超
- 本文首发于个人博客:https://antoniopeng.com/2020/04/07/java/%E6%B7%B1%E5%85%A5Web%E8%AF%B7%E6%B1%82%E8%BF%87%E7%A8%8B/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 彭超 | Blog!



